「データ解析のための統計モデリング入門」 読書メモ一覧 - jiku log
はじめに
数理統計学より実践的な内容の理解に向けて,久保 拓弥 著「データ解析のための統計モデリング入門 一般化線形モデル・階層ベイズモデル・MCMC」を読み,第10章「階層ベイズモデル ―GLMMのベイズモデル化― 」の読書メモをまとめた。
stern-bow.hatenablog.com
このときはCmdStanPyを用いて実装した。
このたびNumPyroを学んだので,本章の内容をPythonコードで書き直した。
- 参考サイト
第10章 階層ベイズモデル ―GLMMのベイズモデル化―
GLMMのベイズモデル化
本章で扱う手法は,一般化混合線形モデル(GLMM)である。題材として,個体差がある生存種子数のデータを扱う。
今回扱うモデルは,サンプルにおいて生存する種子数
が,確率
の二項分布にしたがうとする。
またこの確率確率は,固定効果とランダム効果を組込めるような統計モデルである。
またランダム効果自体に事前分布を設定した階層モデルであるとする。
分析の目的は,データが与えられたときのパラメータの事後分布を求めることである。
NumPyroによる事後分布の推定の流れ
NumPyroを用いて事後分布を推定する流れは以下のようになる。
- Step 1. パッケージを読み込む。
- Step 2. データを読み込む。
- Step 3. データを整形する。
- Step 4. NumPyroでモデルを定義する。
- Step 5. MCMCを実行する。
- Step 6. 収束判定を行なう。
- Step 7. 事後分析を行なう(可視化など)。
今回は手元のPC(メモリ:16GB,コア数:10)で行なった。Pythonは,Python3.12.6を用いた。使用したライブラリ群は以下の通りである。
arviz : 0.22.0 jax : 0.10.1 matplotlib: 3.10.9 numpyro : 0.21.0 pandas : 3.0.3 seaborn : 0.13.2
以下に,使用したコード群を説明する。
Step 1. パッケージを読み込む。
MCMC実行用など,各種パッケージを読み込む。
コード:
# ------------------------------- # パッケージの読み込み # ------------------------------- # データ処理一般用 import pandas as pd import numpy as np # NumPyroによるMCMC実行・可視化用 import jax import jax.numpy as jnp import numpyro import numpyro.distributions as dist from numpyro.infer import MCMC, NUTS import arviz as az # 可視化用 import matplotlib.pyplot as plt import seaborn as sns sns.set_style(style='darkgrid') # 計算環境の設定 numpyro.set_platform('cpu') # CPUで動作させる。 numpyro.set_host_device_count(4) # 4チェーン並列実行のため、デバイス数を設定
Step 2. データを読み込む。
データを読み込む。なおデータは,https://kuboweb.github.io/-kubo/ce/IwanamiBook.html のdata7a.csvをダウンロードして利用する。
コード:
# ------------------------------- # データの読み込み # ------------------------------- file_path = "data7a.csv" df = pd.read_csv(file_path) print(df.head(3)) print(df.describe())
出力:
id y
0 1 0
1 2 2
2 3 7
id y
count 100.000000 100.000000
mean 50.500000 4.030000
std 29.011492 3.150934
min 1.000000 0.000000
25% 25.750000 1.000000
50% 50.500000 4.000000
75% 75.250000 7.000000
max 100.000000 8.000000今回利用するデータはyとである。また,最大値が8であるため,生存する種子数がしたがう分布は二項分布
であることが分かる。
Step 3. データを整形する。
NumPyroでデータを扱うために,JAXのjax.numpy モジュールを用いて,データを変換する。
コード:
n_trials = max(df["y"].values) print(n_trials) # ------------------------------- # デザイン行列の作成 # ------------------------------- y = jnp.array(df["y"].values)
先ほど確認した通り,この後二項分布を扱っていくため,二項分布のうち
に該当する値である
n_trialsを設定している。
Step 4. NumPyroでモデルを定義する。
ここが1つ目の重要ポイントである。事後分布を求めるので,
- 事前分布 (固定効果およびランダム効果)
- 尤度
- 線形予測子
を設定する。
ランダム効果は,個体数だけ登場するため,
expand([N])のように,ランダム効果の事前分布をN個分発生させている。
また,尤度の設定において重要なのは,numpyro.plate である。
このクラスは,サンプリングの際に条件付き独立になることを指定している。
コード:
# ------------------------------- # モデル定義 # ------------------------------- def binom_glmm_model(seed_num): N = len(seed_num) # 事前分布 ## 固定効果 beta = numpyro.sample("beta", dist.Normal(0, 100)) ## ランダム効果 s = numpyro.sample("s", dist.HalfNormal(100)) # ランダム効果の標準偏差 r = numpyro.sample("r", dist.Normal(0, s).expand([N])) # ランダム効果 # 線形予測子 logits = beta + r # 観測モデル(尤度) with numpyro.plate("data", N): numpyro.sample("obs", dist.Binomial(total_count=n_trials, logits=logits), obs=seed_num)
Step 5. MCMCを実行する。
ここが2つ目の重要ポイントである。MCMCを実行する際には,以下の手順で進める。
- 乱数の設定
- MCMCの手法の設定(今回はNUTSを使用する。)
- MCMCの実施条件の設定
- バーンイン期間の設定(
num_warmup) - バーンイン後のサンプル数(
num_samples)
- バーンイン期間の設定(
- MCMCの実行
コード:
# ------------------------------- # MCMC実行 # ------------------------------- rng_key = jax.random.PRNGKey(1) kernel = NUTS(binom_glmm_model) mcmc = MCMC( kernel, num_warmup=2000, num_samples=2000, num_chains=4, progress_bar=True ) mcmc.run( rng_key, seed_num = y )
Step 6. 収束判定を行なう。
これが3つ目の重要ポイントである。
収束については,How to Diagnose and Resolve Convergence Problems – Stan に詳しく説明されている。
収束の判定の際には,以下を確認する。
- Rhat
- 1.01以下であれば,得られたサンプルを信頼してもよい。
- トレースプロット
- サンプルの遷移が発散していなければ,得られたサンプルは信頼してもよい。
コード:
# ------------------------------- # 収束判定 # ------------------------------- print("\nMCMCサマリー:") mcmc.print_summary(prob=0.95) # MCMCサンプルをArviZ InferenceDataオブジェクトに変換し、プロットしやすくする idata = az.from_numpyro(mcmc) # トレースプロット ------------------------------------------------------------ az.plot_trace(idata, var_names=['beta','s']) plt.tight_layout() plt.show()
出力:
MCMCサマリー:
mean std median 2.5% 97.5% n_eff r_hat
beta 0.06 0.34 0.06 -0.63 0.71 1453.36 1.00
r[0] -3.85 1.73 -3.63 -7.32 -0.82 7198.97 1.00
r[1] -1.22 0.87 -1.20 -2.88 0.45 5972.77 1.00
r[2] 1.96 1.09 1.87 -0.01 4.20 7591.77 1.00
r[3] 3.79 1.77 3.57 0.62 7.23 6313.91 1.00
r[4] -2.07 1.10 -1.96 -4.27 -0.04 6552.06 1.00
r[5] 1.98 1.09 1.90 -0.03 4.21 7518.39 1.00
r[6] 3.79 1.76 3.56 0.81 7.46 6568.83 1.00
r[7] 3.76 1.79 3.53 0.58 7.37 6453.29 1.00
r[8] -2.09 1.12 -2.00 -4.41 -0.05 6670.68 1.00
r[9] -2.09 1.11 -1.99 -4.39 -0.09 6522.55 1.00
r[10] -0.06 0.80 -0.07 -1.67 1.48 5557.73 1.00
r[11] -3.86 1.75 -3.63 -7.38 -0.77 7193.79 1.00
r[12] -2.08 1.10 -1.98 -4.20 0.07 5922.50 1.00
r[13] -0.06 0.79 -0.07 -1.68 1.38 5185.72 1.00
r[14] 1.99 1.09 1.90 -0.06 4.23 7049.44 1.00
r[15] 3.79 1.78 3.56 0.69 7.34 6721.07 1.00
r[16] 1.98 1.10 1.89 -0.01 4.25 6162.30 1.00
r[17] -3.86 1.73 -3.65 -7.24 -0.78 6327.09 1.00
r[18] -1.23 0.90 -1.18 -3.01 0.49 6364.10 1.00
r[19] -1.21 0.90 -1.17 -3.00 0.50 5846.77 1.00
...
r[99] -3.87 1.74 -3.65 -7.39 -0.89 5921.50 1.00
s 3.03 0.37 3.01 2.32 3.76 1957.09 1.00
Number of divergences: 0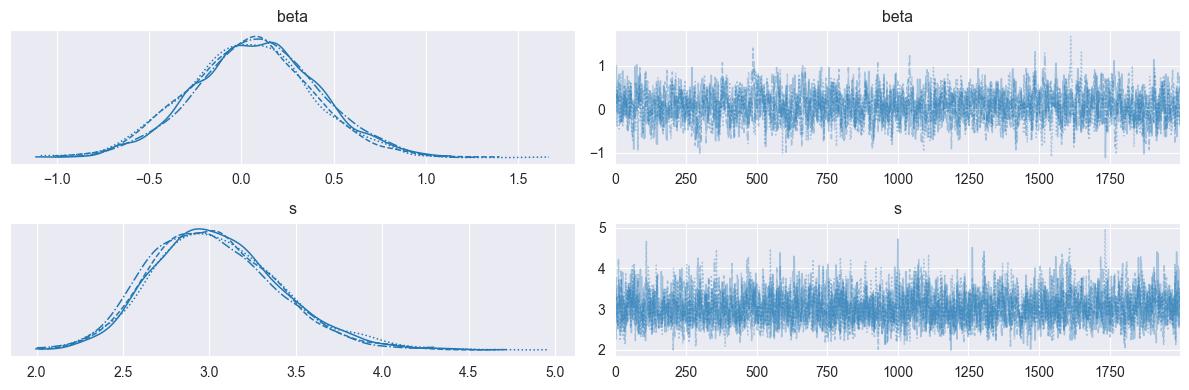
階層ベイズモデルの場合,ランダム効果のMCMCサンプルが,ランダム効果の数(今回の場合,データ数である100)だけ入手できるため,推定対象のパラメータが多くなることが特徴である。
Step 7. 事後分析を行なう(可視化など)。
得られたパラメータの事後分布を確認する。固定効果のパラメータと,事前分布の分散
に関する95%の最高密度区間(HDI)を可視化すると以下のようになる。
コード:
# ------------------------------- # 可視化 # ------------------------------- # 最高密度区間の表示 print("\nGenerating posterior plots...") az.plot_posterior(idata, var_names=['beta','s'], hdi_prob=0.95) plt.suptitle('Posterior distributions', y=1.02) plt.tight_layout() plt.show()
出力:
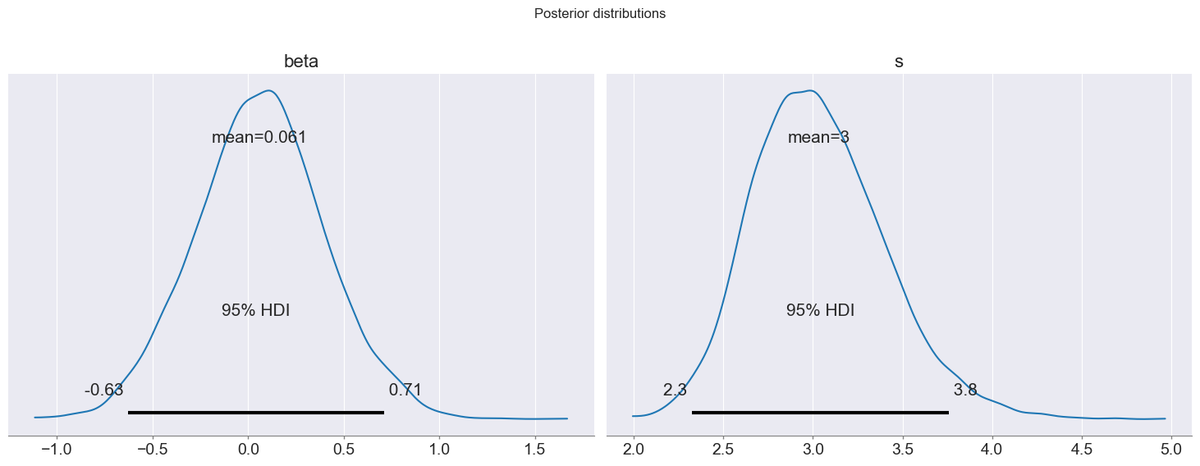
補足
今回扱った階層ベイズモデルのグラフィカルモデルは以下のようになる。
コード:
numpyro.render_model(binom_glmm_model,
model_args=(y, ),
render_distributions=True
)
出力:
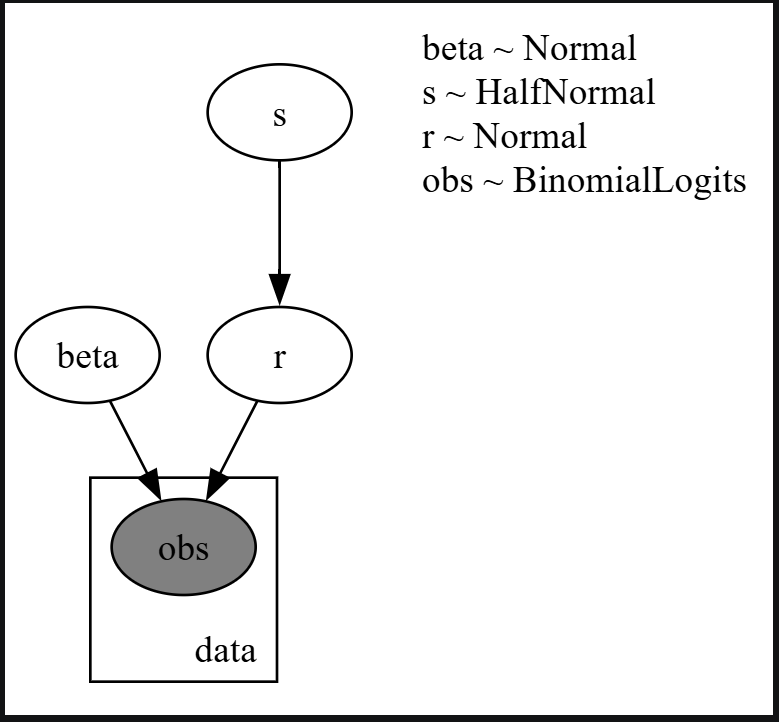
グラフィカルモデルを可視化しておくと,設定した統計モデルが正しくコーディングされているかどうかを確認することができる。
まとめと感想
NumPyroによる階層ベイズモデル
階層ベイズモデルは,ランダム効果をモデル化するために有用なツールである。この際,階層的に事前分布を設定する必要があるが,
## ランダム効果 s = numpyro.sample("s", dist.HalfNormal(100)) # ランダム効果の標準偏差 r = numpyro.sample("r", dist.Normal(0, s).expand([N])) # ランダム効果
のように直感的にコード化できることがNumPyroの強みであると感じた。
また,モデルが複雑になると,コーディングを誤っている可能性が出てくる。その際にはモデルの可視化機能を使い,変数間の依存関係や,変数がしたがう確率分布を可視化することで,自分自身のチェックができたり,他者からレビューを受けやすくなると感じた。