「データ解析のための統計モデリング入門」 読書メモ一覧 - jiku log
はじめに
数理統計学より実践的な内容の理解に向けて,久保 拓弥 著「データ解析のための統計モデリング入門 一般化線形モデル・階層ベイズモデル・MCMC」を読み,第11章「空間構造のある階層ベイズモデル」の読書メモをまとめた。
stern-bow.hatenablog.com
このときはCmdStanPyを用いて実装した(そして,挫折した)。
このたびNumPyroを学んだので,本章の内容をPythonコードで書き直した。
- 参考サイト
第11章 空間構造のある階層ベイズモデル
問題設定
本章では,「調査区画を50個設定し,そこに存在している架空植物の個体数」のデータを用いる。また,「隣にある個体数は似ている」という空間相関を取り込むため,以下のようにモデル化を行なう。
正規分布の平均
NumPyroでCARを用いる
NumPyroでは,確率分布のクラスの1つとして,CARを提供している。CARの確率分布は,多変量正規分布の一種である。
num.pyro.ai
CARを使うときのパラメータとして,以下のようなものを設定する。
loc:平均correlation:自己回帰パラメータ(基本的に0から1の間の値)conditional_precision:正規分布の精度(分散の逆数)adj_matrix:対称な隣接行列is_sparse:疎行列を使うかどうかのフラグ
今回は,このCARクラスを用いて実装する。
NumPyroによる空間構造のある階層ベイズモデルの実装
今回は手元のPC(メモリ:16GB,コア数:10)で行なった。Pythonは,Python3.12.6を用いた。使用したライブラリ群は以下の通りである。
arviz : 0.22.0 jax : 0.10.1 matplotlib: 3.10.9 numpy : 2.4.6 numpyro : 0.21.0 pandas : 3.0.3 rdata : 1.0.0 seaborn : 0.13.2
以下に,使用したコード群を説明する。
Step 1. パッケージを読み込む。
MCMC実行用など,各種パッケージを読み込んだ。
コード:
# ------------------------------- # パッケージの読み込み # ------------------------------- # データ処理一般用 import pandas as pd import numpy as np # NumPyroによるMCMC実行・可視化用 import jax import jax.numpy as jnp import numpyro import numpyro.distributions as dist from numpyro.infer import MCMC, NUTS, Predictive import arviz as az # 可視化用 import matplotlib.pyplot as plt import seaborn as sns sns.set_style(style='darkgrid') # 計算環境の設定 numpyro.set_platform('cpu') # CPUで動作させる。 numpyro.set_host_device_count(4) # 4チェーン並列実行のため、デバイス数を設定
Step 2. データを読み込む。
データを読み込み,その後可視化した。
なおデータは,https://kuboweb.github.io/-kubo/ce/IwanamiBook.html のY.RDataをダウンロードして利用した。
なお,拡張子が.RDataのファイルを読み込むために,rdata パッケージを用いた。
コード:
# ------------------------------- # データの読み込み # ------------------------------- import rdata file_path = "Chapter11_Y.RData" parsed = rdata.parser.parse_file(file_path) converted = rdata.conversion.convert(parsed) df = pd.DataFrame(converted) print(df.head(3)) print(df.describe()) # 散布図を作成 plt.figure(figsize=(8, 6)) sequence = list(range(1, df.shape[0]+1, 1)) plt.scatter(sequence, df['Y'], color='white', edgecolor='black') plt.plot(sequence, df['m'], linestyle='dashed') plt.ylim(-1, 27) # ラベルと凡例を追加 plt.xlabel('Situation j') plt.ylabel('Number of samples y_i') # グラフを表示 plt.show()
出力:
Y m
0 0.0 2.154980
1 3.0 3.254165
2 2.0 4.628666
Y m
count 50.000000 50.000000
mean 10.880000 10.990589
std 5.231927 3.865481
min 0.000000 2.154980
25% 7.000000 9.804759
50% 11.000000 11.573849
75% 15.000000 13.101365
max 19.000000 16.662963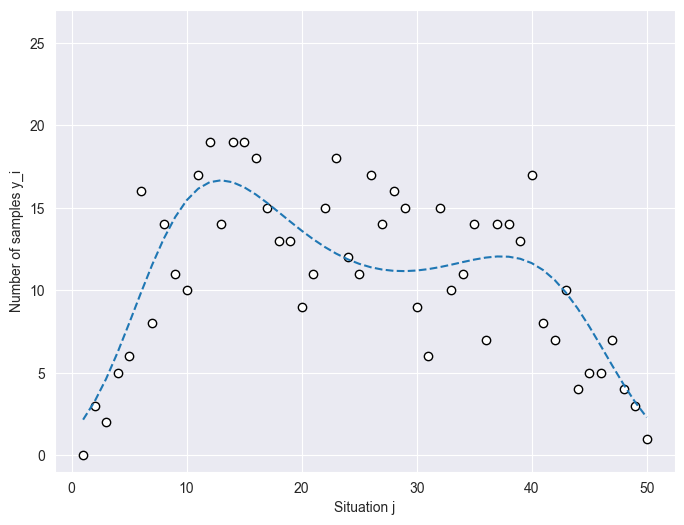
図において,横軸は調査区画の位置(),縦軸は観測された個体数(
),破線はこのデータをポアソン乱数で生成するときに使った場所ごとに変化する平均値である(※データとして与えられており,いわば真値のようなものである)。
破線が滑らかに変化していいるため,空間相関があると言える。
Step 3. データを整形する。
NumPyroでデータを扱うために,JAXのjax.numpy モジュールを用いて,データを変換した。
さらに,空間相関を扱うために,CARの入力でもある隣接行列を設定した。
コード:
# ------------------------------- # デザイン行列の作成 # ------------------------------- Y = df["Y"].values N_site = len(Y) # 隣接行列 adj_matrix = np.zeros((N_site, N_site)) for i in range(N_site): if i > 0: adj_matrix[i, i - 1] = 1 if i < N_site - 1: adj_matrix[i, i + 1] = 1 # 行列の可視化 plt.imshow(adj_matrix, cmap='Blues') plt.show() adj_matrix = jnp.array(adj_matrix)
出力:
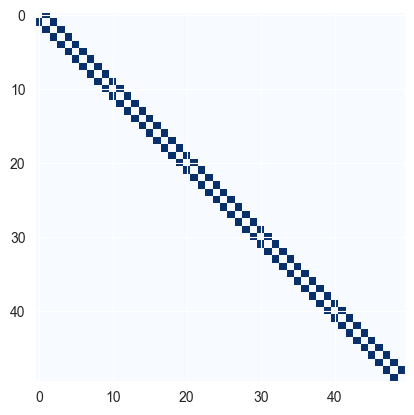
今回用いる隣接行列は,両隣には1を,それ以外には0を設定している。問題に応じて,この隣接行列の構造を変えることになると想定される。
観測された個体数が50であるため,隣接行列の大きさはである。
Step 4. NumPyroでモデルを定義する。
パラメータの事後分布を求めるので,
- 事前分布 (固定効果およびランダム効果)
- 尤度
- 線形予測子
を設定した。
ランダム効果は,個体数だけ登場する。このランダム効果は,NumPyroのCARクラスによって定められる。
コード:
# ------------------------------- # モデル定義 # ------------------------------- def car_poisson_model(Y, adj_matrix): N = Y.shape[0] # 事前分布 ## 固定効果 beta = numpyro.sample("beta", dist.Normal(0.0, 100.0)) ## ランダム効果 s = numpyro.sample("s", dist.HalfNormal(100)) tau = 1.0 / (s ** 2) rho = numpyro.sample("rho", dist.Uniform(0.0, 1.0)) ### CAR prior r = numpyro.sample( "r", dist.CAR( loc=jnp.zeros(N), correlation=rho, conditional_precision=tau, adj_matrix=adj_matrix ) ) # 線形予測子 log_mean = beta + r mean = jnp.exp(log_mean) numpyro.deterministic("mean", mean) # 観測モデル(尤度) numpyro.sample( "Y_obs", dist.Poisson(mean), obs=Y )
Step 5. MCMCを実行する。
MCMCを実行する際には,以下の手順で進める。
- 乱数の設定
- MCMCの手法の設定(今回はNUTSを使用する。)
- MCMCの実施条件の設定
- バーンイン期間の設定(
num_warmup) - バーンイン後のサンプル数(
num_samples)
- バーンイン期間の設定(
- MCMCの実行
コード:
# ------------------------------- # MCMC実行 # ------------------------------- rng_key = jax.random.PRNGKey(1) kernel = NUTS(car_poisson_model) mcmc = MCMC( kernel, num_warmup=2000, num_samples=4000, num_chains=4, progress_bar=True ) mcmc.run( rng_key, Y=jnp.array(Y), adj_matrix=adj_matrix )
Step 6. 収束判定を行なう。
収束の判定の際には,以下を確認する。
- Rhat
- 1.01以下であれば,得られたサンプルを信頼してもよい。
- トレースプロット
- サンプルの遷移が発散していなければ,得られたサンプルは信頼してもよい。
コード:
# ------------------------------- # 収束判定 # ------------------------------- print("\nMCMCサマリー:") mcmc.print_summary(prob=0.95) # ------------------------------- # 収束判定 # ------------------------------- # MCMCサンプルをArviZ InferenceDataオブジェクトに変換し、プロットしやすくする idata = az.from_numpyro(mcmc) # トレースプロット ------------------------------------------------------------ az.plot_trace(idata, var_names=['beta','s', 'rho']) plt.tight_layout() plt.show()
出力:
MCMCサマリー:
mean std median 2.5% 97.5% n_eff r_hat
beta 2.29 0.37 2.29 1.49 3.03 461.44 1.00
r[0] -1.32 0.53 -1.29 -2.36 -0.30 896.98 1.00
r[1] -1.11 0.48 -1.09 -2.07 -0.21 749.01 1.00
r[2] -0.94 0.46 -0.92 -1.87 -0.10 681.57 1.00
r[3] -0.63 0.44 -0.62 -1.46 0.24 630.33 1.00
r[4] -0.34 0.42 -0.33 -1.14 0.51 608.12 1.00
r[5] 0.05 0.42 0.06 -0.79 0.85 591.42 1.00
r[6] 0.01 0.42 0.01 -0.80 0.84 595.66 1.00
r[7] 0.17 0.42 0.16 -0.66 0.99 586.47 1.00
r[8] 0.15 0.41 0.15 -0.64 1.00 576.07 1.00
r[9] 0.19 0.41 0.19 -0.61 1.01 577.19 1.00
r[10] 0.42 0.41 0.42 -0.35 1.27 552.63 1.00
r[11] 0.52 0.41 0.51 -0.28 1.32 537.99 1.00
r[12] 0.46 0.41 0.45 -0.34 1.29 553.44 1.00
r[13] 0.56 0.40 0.56 -0.19 1.43 539.15 1.00
r[14] 0.57 0.40 0.57 -0.21 1.39 542.41 1.00
r[15] 0.52 0.40 0.52 -0.30 1.30 550.11 1.00
r[16] 0.40 0.41 0.39 -0.37 1.25 547.93 1.00
r[17] 0.29 0.41 0.28 -0.55 1.08 554.90 1.00
r[18] 0.22 0.41 0.22 -0.57 1.03 572.21 1.00
r[19] 0.11 0.41 0.11 -0.70 0.91 580.85 1.00
...
rho 0.98 0.03 0.99 0.93 1.00 2031.23 1.00
s 0.28 0.07 0.28 0.16 0.43 2466.83 1.00
Number of divergences: 0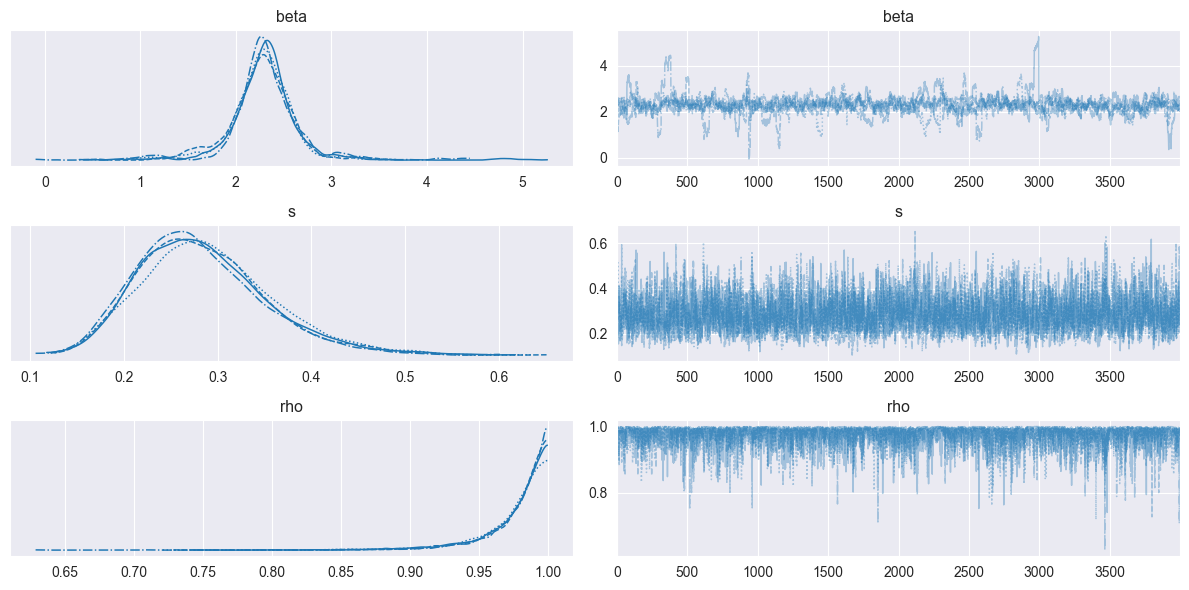
パラメータの収束は上手くできているようであった。また,自己回帰の相関を表すrhoは,1に近い値を取っていた。
Step 7. 事後分析を行なう(可視化など)。
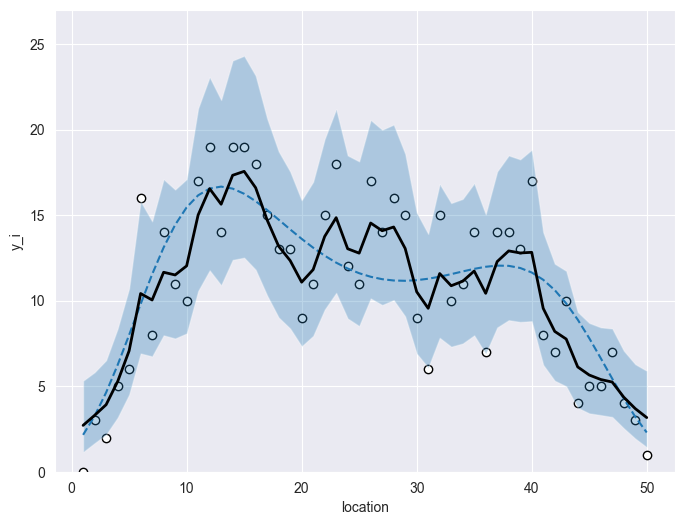
観測データと,推定された95%信用区間や中央値を可視化した。
コード:
# ------------------------------- # 可視化 # ------------------------------- posterior = mcmc.get_samples() beta_samples = np.array(posterior["beta"]) r_samples = np.array(posterior["r"]) lambda_samples = np.exp( beta_samples[:, None] + r_samples ) lambda_q = np.percentile( lambda_samples, q=[2.5, 50.0, 97.5], axis=0 ) lower = lambda_q[0] median = lambda_q[1] upper = lambda_q[2] # プロット plt.figure(figsize=(8, 6)) plt.scatter(sequence, df['Y'], color='white', edgecolor='black') plt.plot(sequence, df['m'], linestyle='dashed') plt.fill_between(sequence,lower,upper,alpha=0.3) plt.plot(sequence,median,linewidth=2, color="black") plt.xlabel("location") plt.ylabel("y_i") plt.ylim(0, 27) plt.grid(True) plt.show()
出力: