はじめに
これまで,統計モデリングや状態空間モデルを用いた時系列分析,機械学習などを学んできた。いずれも背景にはベイズ統計学がある。
あらためてベイズ統計学を学ぶために,ピーター・D・ホフ 著,入江 薫・菅澤 翔之助・橋本 真太郎 訳 「標準 ベイズ統計学」を読むことにした。

本書は,以下のブログ記事においても,かなり高評価であった。
- ベイズ統計学を勉強する参考書のフロー #データサイエンス - Qiita
- 『標準ベイズ統計学』はベイズ統計学をきちんと基礎から日本語で学びたいという人にとって必携の一冊 - 渋谷駅前で働くデータサイエンティストのブログ
本記事では,第8.1節を題材とした,NumPyroによる2グループ比較を学んだ。
本記事のハイライト
- 本記事では,「標準ベイズ統計学」の第8.1節を題材に,NumPyroを用いることで,ギブスサンプラーを構成することなく,パラメータの事後分布を得る方法を説明した。
- パラメータの事後分布をもとに,「平均の差が0を超える確率」などを直接評価することで,t検定とは異なる,ベイズ流の2グループ比較の方法を説明した。
第8章 グループ比較と階層モデリング
第8.1節 二つのグループを比較する
問題設定
本節における問題設定は,米国の2つの公立高校における1年生の数学の得点を比較している。学校1は31人,学校2は28人いる。
得点の箱ひげ図を描くと以下のようになる。
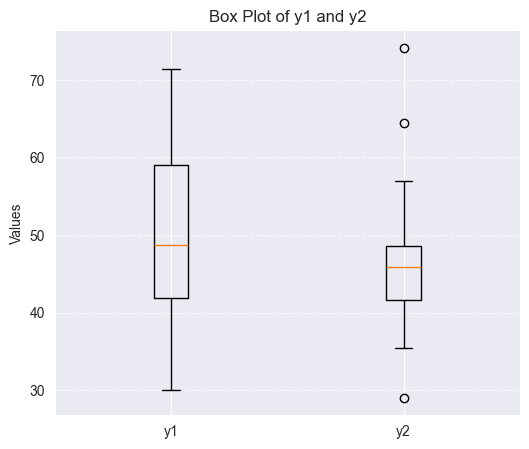
平均点は,学校1の平均点の方が大きいが,サンプル数も分散も異なるので,これらも加味して比較する必要がある。
モデル化
学校1・学校2の2つのグループに対して,以下のようなモデルを考える。
未知パラメータについては,以下のような共役事前分布を設定する。
NumPyroによる実装例
本書では,パラメータの完全条件付き分布を導出し,ギブスサンプラーを構成してサンプリングを実行している。
本記事では,NumPyroを用いて実装した。
参考にしたコード
本記事では,Index of /~pdh10/FCBS/ReplicationのChapter8.Rを参考に作成した。
実行環境
今回は手元のPC(メモリ:16GB,コア数:10)で行なった。Pythonは,Python3.12.6を用いた。使用したライブラリ群は以下の通りである
arviz : 0.22.0 jax : 0.10.1 matplotlib: 3.10.9 numpy : 2.4.6 numpyro : 0.21.0 pandas : 3.0.3 rdata : 1.0.0 scipy : 1.17.1 seaborn : 0.13.2
Step. 1 パッケージを読み込む。
MCMC用など各種パッケージを読み込んだ。
# ------------------------------- # パッケージの読み込み # ------------------------------- # データ処理一般用 import pandas as pd import numpy as np import rdata # NumPyroによるMCMC実行・可視化用 from jax import random import jax.numpy as jnp import numpyro import numpyro.distributions as dist from numpyro.infer import MCMC, NUTS import arviz as az # 可視化用 import matplotlib.pyplot as plt import seaborn as sns sns.set_style(style='darkgrid') # 計算環境の設定 numpyro.set_platform('cpu') # CPUで動作させる。 numpyro.set_host_device_count(4) # 4チェーン並列実行のため、デバイス数を設定
Step2. データを読み込む。
データを読み込んだ。今回のデータは,異なる配列長のデータを用いるので,pandasは利用しなかった。
# ------------------------------- # データの読み込み # ------------------------------- file_path = "../r_codes/nels.RData" parsed = rdata.parser.parse_file(file_path) converted = rdata.conversion.convert(parsed) y1 = np.array(converted['y.school1']) y2 = np.array(converted['y.school2'])
Step 3. データを整形する。
NumPyroで実行するために,JAXモジュールを用いてデータを変換した。
# ------------------------------- # デザイン行列の作成 # ------------------------------- y1_jax = jnp.asarray(y1) y2_jax = jnp.asarray(y2)
Step 4. NumPyroでモデルを定義する。
今回は,事前分布の各種パラメータをモデル定義に組込んだ。
# ------------------------------- # モデル定義 # ------------------------------- # Two-sample comparison model def two_sample_model( y1, y2, mu0=50.0, g02=625.0, del0=0.0, t02=625.0, s20=100.0, nu0=1.0, ): # 事前分布 mu = numpyro.sample("mu", dist.Normal(mu0, np.sqrt(g02))) delta = numpyro.sample("delta", dist.Normal(del0, np.sqrt(t02))) sigma2 = numpyro.sample( "sigma2", dist.InverseGamma( concentration=nu0 / 2, rate=nu0 * s20 / 2, ) ) sigma = jnp.sqrt(sigma2) numpyro.deterministic("mu1", mu + delta) numpyro.deterministic("mu2", mu - delta) # 観測モデル(尤度) numpyro.sample("y1", dist.Normal(mu + delta, sigma), obs=y1,) numpyro.sample("y2", dist.Normal(mu - delta, sigma), obs=y2,)
のちほど平均の差を扱うべく,を保存するために,
numpyro.deterministicを用いた。
Step 5. MCMCを実行する。
MCMCによって,パラメータの事後分布を推定した。
# ------------------------------- # MCMC実行 # ------------------------------- rng_key = random.PRNGKey(1) nuts_kernel = NUTS(two_sample_model) mcmc = MCMC( nuts_kernel, num_warmup=1000, num_samples=4000, num_chains=4, progress_bar=True, ) mcmc.run( rng_key, y1=y1_jax, y2=y2_jax, )
Step 6. 収束判定を行なう。
Rhatなどにもとづき,収束判定を行なった。
コード:
# ------------------------------- # 収束判定 # ------------------------------- print("\nMCMCサマリー:") mcmc.print_summary(prob=0.95)
出力:
MCMCサマリー:
mean std median 2.5% 97.5% n_eff r_hat
delta 2.33 1.36 2.32 -0.40 4.95 13618.32 1.00
mu 48.50 1.34 48.49 45.88 51.11 14477.73 1.00
sigma2 109.05 20.71 106.37 72.31 149.74 11982.29 1.00
Number of divergences: 0Rhatは1.00であり,問題なく収束ができているようであった。
2グループの比較
パラメータの事後分布の推定が完了し,ここからが2グループ比較の本番である。そのため,事後分布のMCMCサンプルから集計や可視化を行なう。
収束判定結果の可視化
まずデータの後処理をしやすくするために,Arvizを用いてデータの変換などを行なう。
python.arviz.org
今回興味があるのは,2つの群における平均の差である。そのため,および
について,その差
を計算し,内容の確認を行なう。
まずは,MCMCの収束の確認がてら,パラメータの分布を確認する。
コード:
# ------------------------------- # 可視化 # ------------------------------- # 1. ArviZ形式へ変換 samples = mcmc.get_samples() mu = samples["mu"] delta = samples["delta"] sigma2 = samples["sigma2"] mu1 = mu + delta mu2 = mu - delta mean_diff = mu1 - mu2 idata = az.from_numpyro( mcmc, posterior_predictive=None, ) idata.posterior["mu1"] = ( ("chain", "draw"), mu1.reshape(idata.posterior["mu"].shape) ) idata.posterior["mu2"] = ( ("chain", "draw"), mu2.reshape(idata.posterior["mu"].shape) ) idata.posterior["mean_diff"] = ( ("chain", "draw"), mean_diff.reshape(idata.posterior["mu"].shape) ) # 2. トレースプロット az.plot_trace( idata, var_names=[ "mu", "delta", "sigma2", "mean_diff" ] ) plt.tight_layout() plt.show()
出力:
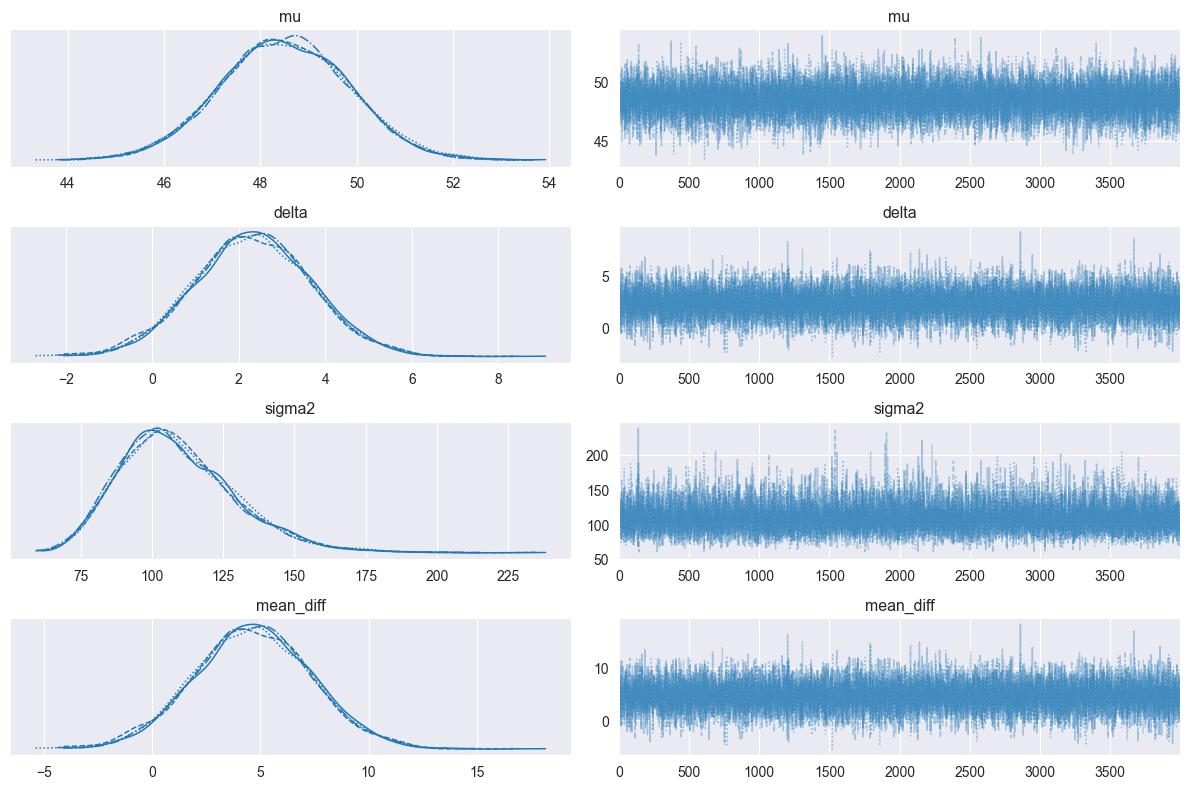
特に注目するべきは,最下段にあるmean_diffである。
もし2群に差が無いのであれば,この分布の平均値は0に近づくはずである。
しかしこの密度推定結果を確認すると,いずれのチェーンにおいてもその平均は5付近にあり,どうやらこの2群には差がありそうであると考えられる。
事後分布の信用区間の確認
次に,パラメータの信用区間,特に2群の平均の差の信用区間を確認する。
コード:
#3. 事後分布 # 全パラメータ az.plot_posterior( idata, var_names=[ "mu", "delta", "sigma2", "mean_diff" ], hdi_prob=0.95, ) plt.tight_layout() plt.show()
出力:※平均の差のみ
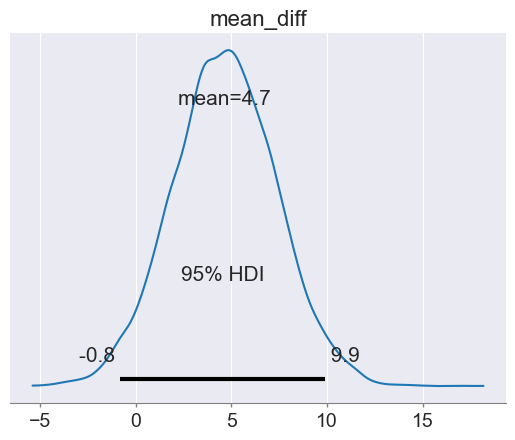
この図を確認すると,mean_diff95%事後信用区間はであり,この区間にゼロを含んでいるものの,平均値は4.7で,0から大きく離れている。
そのため,学校1の母平均が,学校2の母平均よりも大きいという根拠が得られたと言える。
平均差の事後確率
更に,平均差の事後確率,すなわちを評価することで,よりダイレクトに平均差が0よりも大きいことを確認した。
コード:
# 5. 平均差の事後確率 p = np.mean(mean_diff > 0) print(f"P(mu1 > mu2) = {p:.4f}")
出力:
P(mu1 > mu2) = 0.9568
このように,平均の差が0よりも大きくなる確率はおよそ0.96であり,ここからも平均の差が0よりも大きいということが言える。
なお事前分布においては,は平均0の正規分布にしたがうと仮定しているので,
となる。
サンプルの大小比較
先ほどは,
- 学校1の平均が学校2の平均よりも大きくなる確率
を計算した。
さらに,
- 学校1から無作為に選ばれた生徒が,学校2から選ばれた生徒よりも高い得点を得る確率
を計算する。これを計算するには,を得るための事後予測分布を構成する。
コード:
# 同時事後予測分布からPr(Y_1 > Y_2)を求める rng = np.random.default_rng(123) # posterior predictive samples y1_pred = rng.normal( loc=mu + delta, scale=np.sqrt(sigma2) ) y2_pred = rng.normal( loc=mu - delta, scale=np.sqrt(sigma2) ) # Pr(Y1 > Y2) p_y1_gt_y2 = np.mean(y1_pred > y2_pred) print(f"Pr(Y1 > Y2) = {p_y1_gt_y2:.4f}")
出力:
Pr(Y1 > Y2) = 0.6228
このように,一般にとなる。
これは,平均と比べて観測値には観測ノイズが入るためである。
まとめと感想
本記事では,第8.1節を題材とした,NumPyroによる2グループ比較を学んだ。
本章の冒頭では,伝統的な2グループの比較方法であるt検定について説明していた。
t検定では,「2群の平均は同じである」という帰無仮説については評価することができるが,平均の差が0以上である確率などは直接評価することができない。
一方で,ベイズ流の問題設定を行なうと,2群の平均差が0を超える確率を直接的に評価することができるので,解釈はしやすいことが確認できた。
また本書では,事後分布のサンプリングのために完全条件付き分布(注目しているパラメータ以外のパラメータは,条件部分に入っているような確率分布)を構成していたが,モデルによってはこのような分布を作るのが大変なことがある。
NumPyroでは,単に事前分布と尤度を設定すればよいので,NumPyroの手軽さを確認することもできた。
本記事を最後まで読んでくださり,どうもありがとうございました。