「確率的機械学習 入門編II」読書メモ一覧 - jiku log
はじめに
持橋大地・鈴木大慈 監訳「確率的機械学習 入門編II」は,世界的に評価の高いK.P.Murphy著 "Probabilistic Machine Learning (Book1)" の和訳であり,確率モデルに基づく機械学習,深層学習といった基礎が丁寧に整理されている。
本記事は,「第19章 より少ないラベル付きデータからの学習」における,メタ学習・少数例示学習・弱教師あり学習に関する読書メモである。
19.5 メタ学習
メタ学習(meta-learning)は,学習の仕方を学習する(learning to learn)方法である。
学習アルゴリズムは,データからパラメータ推定値
を出力する関数
メタ学習では,
- アルゴリズム
を用いて,
とする。
- その後,新しいデータセット
が得られたら,
を適用してパラメータ
を学習する。
という手順で行なわれる。
19.5.1 モデル非依存メタ学習(MAML)
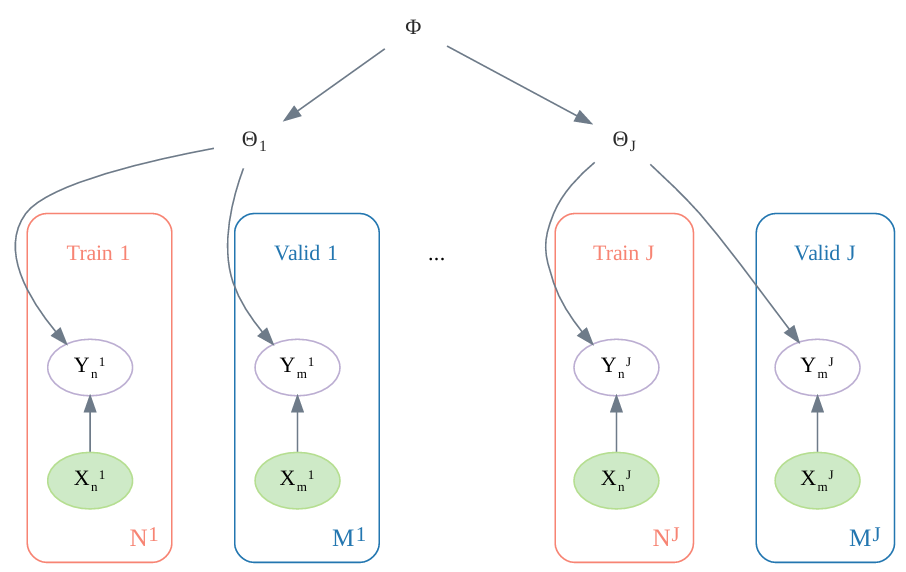
メタ学習の自然なアプローチの1つは,階層ベイズモデルを用いることである(Figure 19.14)。
各タスクのパラメータは,共通の事前分布
を持つと仮定し,データが乏しいタスクを複数集めて,統計的推論の確実性を高める。
このとき,メタ学習は事前分布のパラメータを学習することと等価になる。
事前分布のパラメータを求めるには,
- 各タスク(
)において,訓練用データと検証用データのセットを作る。
- 各タスクにおける尤度のを最大化するように[tex: \mathbfit{\phi}を求める。
という経験ベイズ近似を用いる。
目標タスクのパラメータの点推定値を計算する際には,初期値
と学習率
を用いて勾配上昇を行なう。この手法はモデル非依存メタ学習(model-agnostic meta-learning, MAML)と呼ばれる。
19.6 少数ショット学習
ごく少数のラベル付きデータから行なう学習は,少数例示学習(few-shot learning)と呼ばれる。
極端な例として,
- 単例示学習(one-shot learning) : 各クラスに1つのラベル付きデータが与えられている。
- ゼロ例示学習(zero-shot learning) : ラベル付きのデータが1つも与えられていない。
が挙げられる。
少数例示学習の問題設定は,以下のようになっている。
クラス
例示分類(
- サポート集合とクエリー集合
- メタアルゴリズム
個の訓練用タスクのサポート集合で学習し,これに対応するクエリー集合で評価される。
- その後,テスト用タスクのサポート集合で予測し,これに対応するクエリー集合で評価される。
- メタアルゴリズム
19.6.1 マッチングネットワーク
マッチングネットワークは,少数例示学習のアプローチ方法の1つである。
マッチングネットワークでは,
: 小さなラベル付きデータセット(サポート集合)
: 距離尺度のパラメータ
: 類似度カーネル
を用いて,最近傍分類器をモデル化する。
最近傍分類器は,
この重みは,データに基づく類似度であり,例えば注意機構カーネル(attention kernel)が用いられる。
: 余弦距離
: クエリーに対する埋め込み関数
: サポートに対する埋め込み関数
である。
マッチングネットワークの学習
関数は,メタ学習のように,複数の小さなデータセットを用いて訓練する。
具体的には以下のような手順となる。
- Step 1. 大きなラベル付きデータ
(たとえばImageNet)を準備する。
- Step 2. ラベルの分布
を作成する。
- Step 3. 小さなラベル集合を
のようにして選ぶ(たとえば,25個のラベル集合)。
- Step 4. そのラベルの付いたデータを
- Step 5. 同様にしてテストデータ集合
を作る。
- Step 6. 以下の損失関数の最適化により,モデルを訓練する。
19.7 弱教師あり学習
弱教師あり学習(weakly supervised learning)は,訓練データの1つ1つのラベルが正確なものではなく,ラベルの分布が得られているとするような問題設定である。
このとき,パラメータの学習は,最尤法で学習でき,以下の損失関数(交差エントロピー)を最小化する。
弱教師あり学習における他の問題設定は,バッグ(bag)と呼ばれるデータ点の集合に対して,ラベルが1つだけ与えられているような問題設定である。
まとめと感想
今回は,「19章 より少ないラベル付きデータからの学習」における,メタ学習・少数例示学習・弱教師あり学習についてまとめた。
メタ学習
メタ学習のように,データセットの組合せから共通する部分を学習したい,というモチベーションは,製造業においてもあり得る。
たとえば,同じ型式の製品を大量に作るのではなく,ユーザの要望に応じて少しずつカスタマイズするような「多品種少量生産」においては,似ているものの微妙に異なるデータセットが得られる。
メタ学習のアプローチは,階層ベイズモデルに基づいているが,パラメータ推定には経験ベイズ近似が用いられている。
モデルの柔軟さやパラメータ推定の効率などは,どちらが有利であるか,ということが気になったので,機会があれば試してみたい。
第19章全般の感想
第19章は,「より少ないラベル付きデータからの学習」に関する内容であり,実用上とても重要なテーマを扱っていた。
しかし全体的に概念がとっつきにくい印象があった。説明を読んでも,何をしようとしているのかが理解しづらいところも多いと感じた。
このような場合は,何度か読み返してみるとだんだん理解ができるようになるので,この章の内容は定期的に見返してみたい。
本記事を最後まで読んでくださり,どうもありがとうございました。
参考サイト
- 確率的機械学習:入門編 II |朝倉書店
- 『確率的機械学習:入門編』サポートサイト
- 原著関連
- Probabilistic Machine Learning: An Introduction : 原著のサポートページ
- pyprobml/notebooks.md at auto_notebooks_md · probml/pyprobml · GitHub : 原著の図作成用Notebooks一覧