「確率的機械学習 入門編II」読書メモ一覧 - jiku log
はじめに
持橋大地・鈴木大慈 監訳「確率的機械学習 入門編II」は,世界的に評価の高いK.P.Murphy著 "Probabilistic Machine Learning (Book1)" の和訳であり,確率モデルに基づく機械学習,深層学習といった基礎が丁寧に整理されている。
本記事は,「第19章 より少ないラベル付きデータからの学習」における,転移学習に関する読書メモである。
19.2 転移学習
19.2.3 教師あり事前学習
事前学習タスクは,教師ありの場合も,教師なしの場合もあり得る。
教師あり学習の最も単純な形式は,大きなラベル付きデータセットで事前学習するものである。
代表的なデータセットは,ImageNetである。ただしImageNetは,医療画像のように自然画像と大きく異なる場合はあまり役に立たない。
19.2.4 教師なし事前学習(自己教師あり学習)
ラベルなしのデータの収集は容易であることが多いため,教師なし事前学習(unsupervised pre-training)(または,自己教師あり(self-supervised)学習)は一般的になっている。
教師なし事前学習(自己教師あり学習)には,以下のようなものが挙げられる。
- 補完タスク
- 代理タスク
- 対照タスク
- SimCLR
- CLIP
補完タスク
補完タスク(imputation task)は,自己教師あり学習の1つのアプローチである。これは,入力の一部を隠して,見えている部分から隠されている部分を予測する。
例えば下図のように,画像の一部を切り抜いて,符号化→復号化してから,切り抜いた部分と差分を損失とする。
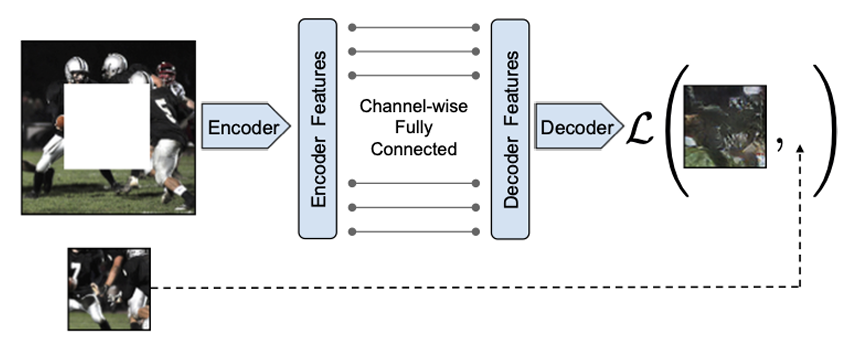
代理タスク
代理タスク(proxy task)は,表現学習におけるラベルを学習する方法である。
代理タスクでは,入力のペアを作成する。たとえば,
: 画像のパッチ
: 入力
: 回転に用いた角度
のようにして,表現学習を行なう関数を学習する。
●ブログ筆者註 :
教師なし事前学習ではラベル付きデータが無いため,データから生成できるタスク(回転に用いた角度をラベルとして,その変換関数
を学習する)から,よい表現を学習している,と理解した。
対照タスク
対照タスク(contrastive task)は,自己教師あり学習で最も良く用いられるアプローチであり,
- 意味的に類似したデータペアは近くする
- 意味的に無関係なデータペアは遠くする
ように学習を行なう。
対照タスクは,深層距離学習と似たアイディアであるが,
- 対照タスク : アルゴリズムが自動的に類似ペアを作る
- 深層距離学習 : 外部から与えられる類似度をラベルに用いる
という違いがある。
SimCLR
SimCLR(Simple Contrastive Learning of visual Representation)の略であり,以下のような手順で学習を行なう。
- 入力
を準備する。
- 2種類の変換
を準備し,2つのビュー
を作成する。
- この変換は,ランダム切り抜きなど,画像に対する小さな摂動とする。
- 入力画像と意味的に異なる画像(負例)を作成する。
- データの埋め込みを与える特徴量マップで,入力画像を埋め込む。
- 埋め込み空間において,対照学習を行なう。
という学習を行なう。
CLIP
CLIP(Contrastive Language-Image Pre-training)は,Webから抽出された4億もの画像と文のペアを膨大なコーパスとして用いる。
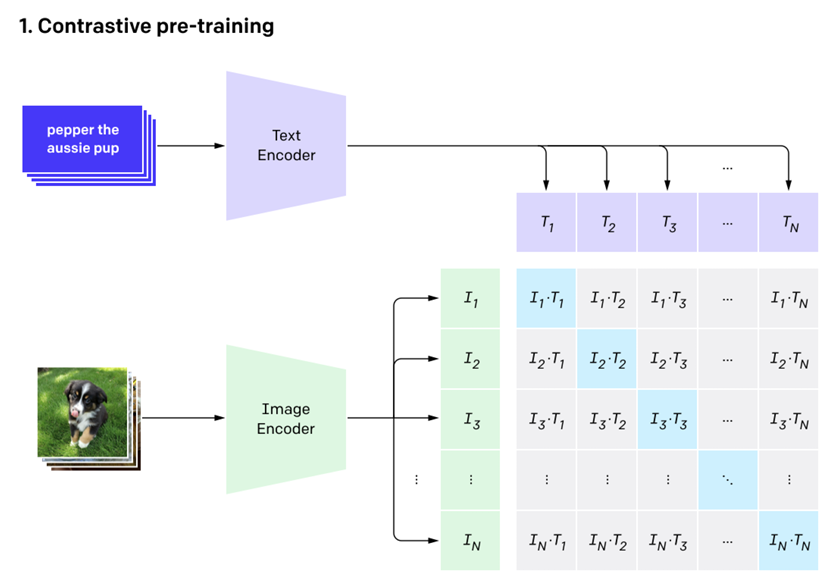
訓練されたモデルは,画像のゼロ例示分類などに利用することができる。
19.2.5 ドメイン適応
ドメイン適応(domain adaptation)は,
- 入力データが転移元ドメイン(source domain)
と転移先ドメイン(target domain)
で異なる。
- 出力ラベルの集合
が共通である
という問題設定のもと,モデルを転移元ドメインで学習し,そのパラメータを調整して転移先ドメインを上手く予測することを目指す手法である。
ドメイン適応に対する一般的なアプローチの1つは,転移元の分類器を訓練する際に,入力が転移元分布からきているか,転移先分布からきているか区別できないように学習する手法である。
まとめと感想
今回は,「19章 より少ないラベル付きデータからの学習」における,転移学習についてまとめた。
転移学習は,製造業のデータ分析においても重要な手法だと感じた。たとえば,製品開発において実験データが大量に得られている際に,類似した別の製品の分析に使ったり,同じ製品を量産するときの分析に使ったりする,ということをしようとすると,この問題設定は転移学習の問題設定に近いので,転移学習の各手法は威力を発揮すると考えられる。
レコメンデーションにおいては,推薦に使えるデータが少ない「コールドスタート問題」という問題があるが,製造業においてもこのような問題は起きうる。
本節において,転移学習の手法はいろいろと紹介されているので,実務でも応用できればと思った。
本記事を最後まで読んでくださり,どうもありがとうございました。
参考サイト
- 確率的機械学習:入門編 II |朝倉書店
- 『確率的機械学習:入門編』サポートサイト
- 原著関連
- Probabilistic Machine Learning: An Introduction : 原著のサポートページ
- pyprobml/notebooks.md at auto_notebooks_md · probml/pyprobml · GitHub : 原著の図作成用Notebooks一覧