「確率的機械学習 入門編II」読書メモ一覧 - jiku log
はじめに
持橋大地・鈴木大慈 監訳「確率的機械学習 入門編II」は,世界的に評価の高いK.P.Murphy著 "Probabilistic Machine Learning (Book1)" の和訳であり,確率モデルに基づく機械学習,深層学習といった基礎が丁寧に整理されている。
本記事は,「第19章 より少ないラベル付きデータからの学習」の半教師あり学習における,自己訓練・エントロピー最小化に関する読書メモである。
19.3 半教師あり学習
半教師あり学習の概要
実応用の設定では,ラベル付きデータを取得するのは高コストである。半教師あり学習(semi-supervised learning)では,ラベル無しデータを上手く活用して,必要なラベル付きデータの量を緩和する。
また半教師あり学習は,
- データの大まかな構造をラベル無しデータによって学習
- 目標タスクの細かい部分だけをラベル付きデータから獲得
することを目指している。
半教師あり学習における仮定
半教師あり学習には,いくつかの仮定を置いている。
- 周辺分布の利用
教師あり学習では,データとラベルの同時分布を用いるが,半教師あり学習ではデータの周辺分布
も利用できることが仮定されている。
下図の(a)は,ラベル付きデータのみから生成される決定境界である。これに対して(b)は,データの周辺分布を考慮した決定境界である。
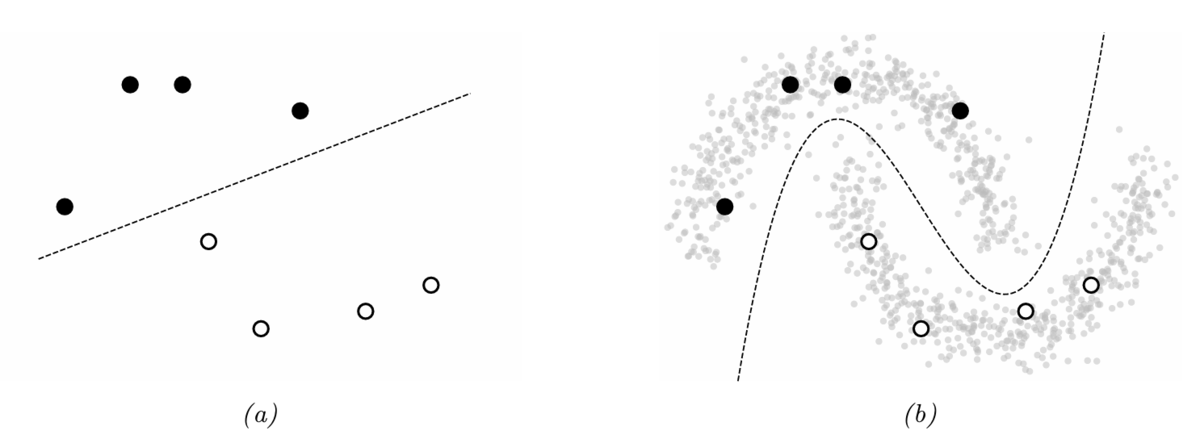
- ラベルなしデータの入手
半教師あり学習では,大量のラベル無しデータが入手可能であるという仮定している。
現実のデータセットにおいても,たとえば自動音声認識の例では,文字起こしされた録音データは少ないが,単に録音されたラベルなしデータは入手しやすいと考えられる。
19.3.1 自己訓練(擬似ラベリング)
半教師あり学習の単純な方法の1つが自己訓練(self-training)である。
自己訓練では,モデル自身を使って,ラベルなしデータのラベルを予測し,予測したラベルをその後の学習に用いる。
自己教師あり学習の典型的なアルゴリズムは,以下の2つが挙げられる。
- 1. ラベルなしデータの全てにラベルを付与する方法
- ラベルなしデータに擬似ラベルを付与して学習を行ない,収束するまで繰り返す(可能であれば再学習する)。
- 2. ランダムサンプリングしたバッチに疑似ラベルを付与する方法
- ランダムサンプリングしたラベルなしデータのバッチに対して擬似ラベルを付与して学習する。
- それをもとに最初から訓練することなく継続的に学習する。
自己訓練では,誤った擬似ラベルを用いてモデル更新を繰り返した場合,次第に分類タスクの性能が劣化することである(確証バイアス)。
一般的には,何らかの方法で正しい疑似ラベルのみを残すような選択基準を用いてこの問題を防ぐ。
19.3.2 エントロピー最小化
エントロピー最小化(entropy minimization)は,ラベルなしデータの予測分布をできるだけ確信度の高い分布にする,というアイディアに基づいている。
エントロピー最小化では
クラスター仮説
エントロピー最小化が上手くいく理由を説明する仮説として,クラスター仮説(cluster assumption)が挙げられる。
このクラスター仮説は,「クラス間の決定境界が,データ多様体の低密度領域に存在する」という仮説である。
クラスター仮説に基づく半教師あり学習では,ラベルなしデータからデータ多様体の形を推定し,決定境界がデータ多様体から離れるように学習を行なう。
下図(a)は,エントロピー最小化を用いていない学習による決定境界である。決定境界が,データの密度が高い領域を通過しているため,この近辺のデータに対する予測クラス確率が半々程度の予測確率になっている,すなわちエントロピーが高くなっている。
下図(b)は,エントロピー最小化を用いた学習による決定境界であり,データにおける予測クラス確率のエントロピーが低くなっている。
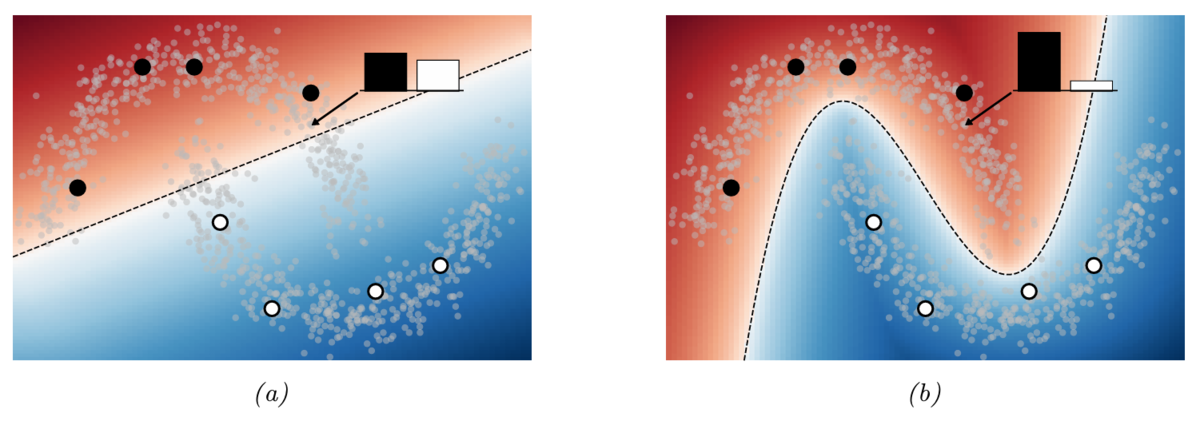
19.3.3 共訓練
共訓練(co-training)は,「異なる特徴ビュー(特徴量の集合)を使う2つのモデルが互いに教師になる」というアイディアに基づく学習方法である。
共訓練では,以下の過程を繰り返す。
- 各特徴ビューで学習し,ラベルなしデータを分類して擬似ラベルを得る。
- 擬似ラベルが以下のような特徴を持つ学習データを探す。
- 一方のモデルではエントロピーが低い(予測の確信度が高い)
- もう一方のモデルではエントロピーが高い(予測の確信度が低い)
- 確信度が低いモデルを学習データに追加する。
この過程を繰り返すことで,確信度の高い擬似ラベルを持つ学習データ(正しくラベル付けされたと考えられる学習データ)を生成する。
まとめと感想
今回は,「19章 より少ないラベル付きデータからの学習」の半教師あり学習における,自己訓練・エントロピー最小化についてまとめた。
製造業においては,ラベル付きのデータは少ないが,ラベル付きのデータが大量に得られる場合がある。例えば,
- 何らかのイベント情報に紐づく時系列データと,単に蓄積されただけの時系列データ
- 品質の不具合などに紐づくテキストデータ(報告書など)と,単に蓄積されただけのテキストデータ(メールやチャットなど)
といったものが挙げられる。そのため,半教師あり学習が利用できるシーンは大きいと考えられる。
エントロピー最小化においては,「同じクラスに属するデータはクラスターを形成している」というクラスター仮説が重要であった。
本書でも触れられている通り,入出力間の相互情報量によってエントロピー最小化は正当化されていた。
データ間の関連性は,線形相関のような単純な指標だけではなく,相互情報量なども使いこなせるようになりたい。
本記事を最後まで読んでくださり,どうもありがとうございました。
参考サイト
- 確率的機械学習:入門編 II |朝倉書店
- 『確率的機械学習:入門編』サポートサイト
- 原著関連
- Probabilistic Machine Learning: An Introduction : 原著のサポートページ
- pyprobml/notebooks.md at auto_notebooks_md · probml/pyprobml · GitHub : 原著の図作成用Notebooks一覧