「確率的機械学習 入門編II」読書メモ一覧 - jiku log
はじめに
持橋大地・鈴木大慈 監訳「確率的機械学習 入門編II」は,世界的に評価の高いK.P.Murphy著 "Probabilistic Machine Learning (Book1)" の和訳であり,確率モデルに基づく機械学習,深層学習といった基礎が丁寧に整理されている。
本記事は,「第21章 クラスタリング」における,混合モデルに関する読書メモである。
21.4 混合モデルを用いたクラスタリング
21.3節で紹介されていたK平均法クラスタリングには,以下のような制約がある。
- クラスターが同一の超球の形をとるという強い仮定を置く(ブログ筆者註 : 距離尺度としてユークリッド距離を用いているため)。
- K平均法は,すべてのクラスターは入力空間で正規分布に従うことを仮定しているので,離散的なデータには用いることができない。
本節では,混合モデルを用いることで,これらの問題点を克服する方法を紹介している。
21.4.1 混合ガウスモデル
3.5.1項で紹介した混合ガウスモデル(GMM)は,次の式で定義される。
また,データ点がクラスター
に属する負担率は次のように計算される。
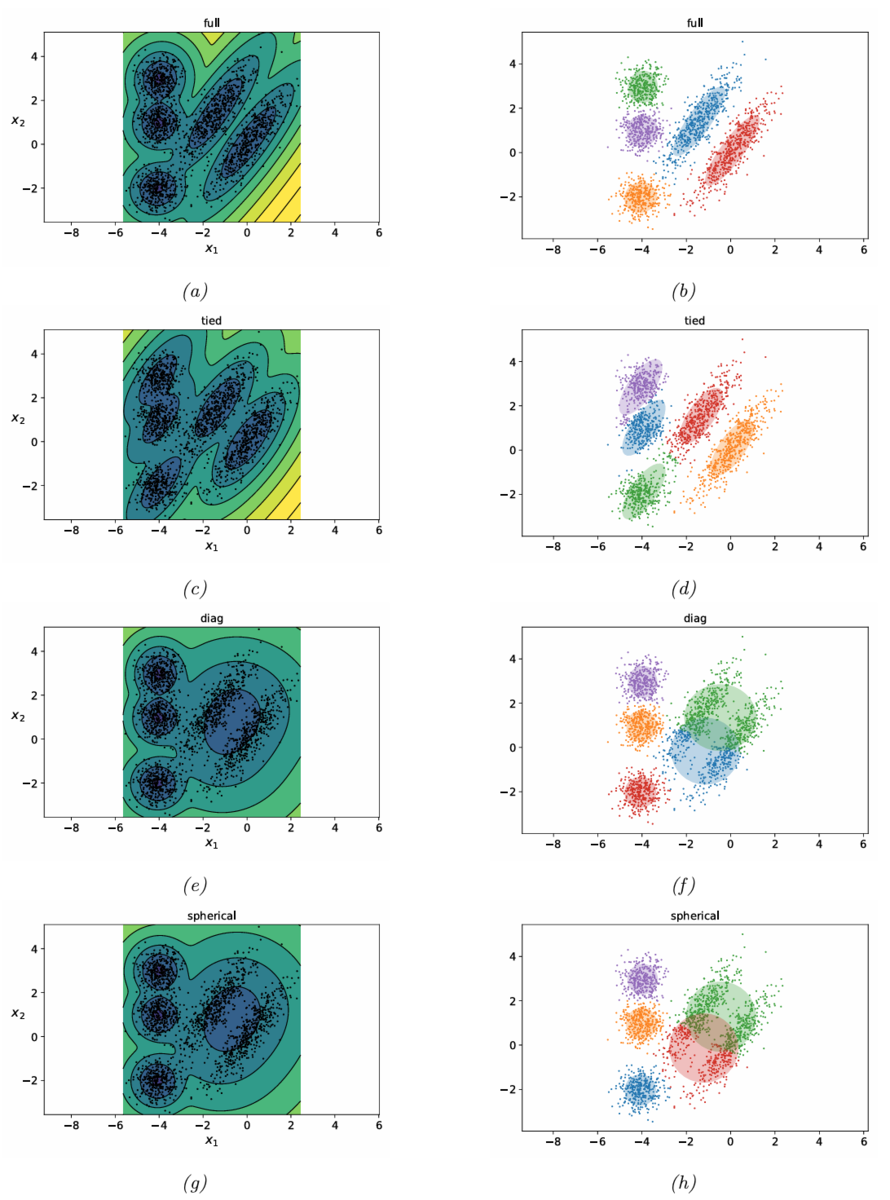
Figure21.14に,2次元データに対してGMMを適用した結果を示す。
(a)・(b)は,クラスターごとに共分散行列を変えるモデルである。
(c)・(d)は,クラスターごとの共分散行列を共有する(同じものを用いる)モデルである。
(e)・(f)は,共分散行列を対角行列に制限したモデルである(そのため,(c)・(d)のように共分散行列の集中楕円が傾いていない)。
(g)・(g)は,共分散行列が超級になるようにしたモデルである。
K平均法とEMアルゴリズム
GMMのパラメータは,EMアルゴリズムによって推定される(ブログ筆者註 : 「確率的機械学習 入門編I」を読む ~第8章 最適化 ⑦バウンド最適化の具体例~ - jiku log 参照)。
K平均法はEMアルゴリズムにおいて,および
とした場合に相当している。
識別不能性とラベル交替
混合モデル内の要素のラベルは,尤度にまったく影響を与えることなく入れ替えることができる。これをラベル交替問題(label switching problem)と呼ぶ。
●ブログ筆者註 :
たとえば,2つの正規分布からなるGMMでは,パラメータはであるが,
は添え字が違うだけなので,同じ分布を表す。
これに対して,例えばパラメータの大きさによって順序付けして区別することは可能であるが,2次元以上では順序を決める明確な方法が無いため有効ではない。
●ブログ筆者註 :
実用上の対策としては,「クラスター番号」と「正解のクラスタリング結果の番号」の意味は無視して評価する,といった方法が考えられる。
ベイズ的モデル選択
クラスター数Kの選択は,周辺化対数尤度の近似値であるWAIC(widely applicable information criterion)などを用いて比較することができる。
21.4.2 混合ベルヌーイモデル
二値のデータをクラスタリングする場合には,混合ベルヌーイモデルを利用する。
このモデルにおけるパラメータは,EMアルゴリズム,確率的勾配降下法,MCMCなどによって推定できる。
まとめと感想
今回は,「第21章 クラスタリング」における,混合モデルについてまとめた。
混合モデルを用いたクラスタリングは確率分布を用いているため,事前分布の設定や,ソフトクラスタリングなど,柔軟なモデリングが可能になる。
GMMの場合,図にも示している通り,共分散行列の設定方法によってクラスタリング結果が変わる。ただし,共分散行列が対角行列であれば逆行列計算の計算量が少なくなるなど,クラスタリングの結果だけでなく計算量にも影響がある。
目的やデータの性質に応じて,適切なモデルを選択できるようになりたい。
また,パラメータ推定はEMアルゴリズムを用いることになる。EMアルゴリズムは汎用的な枠組みであるが,実際にパラメータ推定を行なう際には,問題固有の解き方が発生する。
代表的な混合モデルについては,パラメータ推定方法を把握しておきたい。
本記事を最後まで読んでくださり,どうもありがとうございました。
参考サイト
- 確率的機械学習:入門編 II |朝倉書店
- 『確率的機械学習:入門編』サポートサイト
- 原著関連
- Probabilistic Machine Learning: An Introduction : 原著のサポートページ
- pyprobml/notebooks.md at auto_notebooks_md · probml/pyprobml · GitHub : 原著の図作成用Notebooks一覧