「確率的機械学習 入門編II」読書メモ一覧 - jiku log
はじめに
持橋大地・鈴木大慈 監訳「確率的機械学習 入門編II」は,世界的に評価の高いK.P.Murphy著 "Probabilistic Machine Learning (Book1)" の和訳であり,確率モデルに基づく機械学習,深層学習といった基礎が丁寧に整理されている。
本記事は,「第20章 次元削減」における,因子分析に関する読書メモである。
20.2 因子分析
本節では,PCAの一般化にあたる因子分析(factor analysis)を説明している。これは,確率モデルに基づいているので,より複雑なモデルの構成要素として用いやすい。
20.2.1 生成モデル
因子分析は,以下の線形ガウス潜在変数による生成モデルに対応する。
を積分消去して得られる周辺分布
は,ガウス分布
となる。
さらに,のように単純化すると,
因子データ分析におけるデータ生成過程を以下に示す。
まずは,は1次元のガウス分布である。
この分布から,変数を1つ取り出し,因子負荷行列
を掛けると2次元の点になる。
その結果,2次元のガウス分布となる。
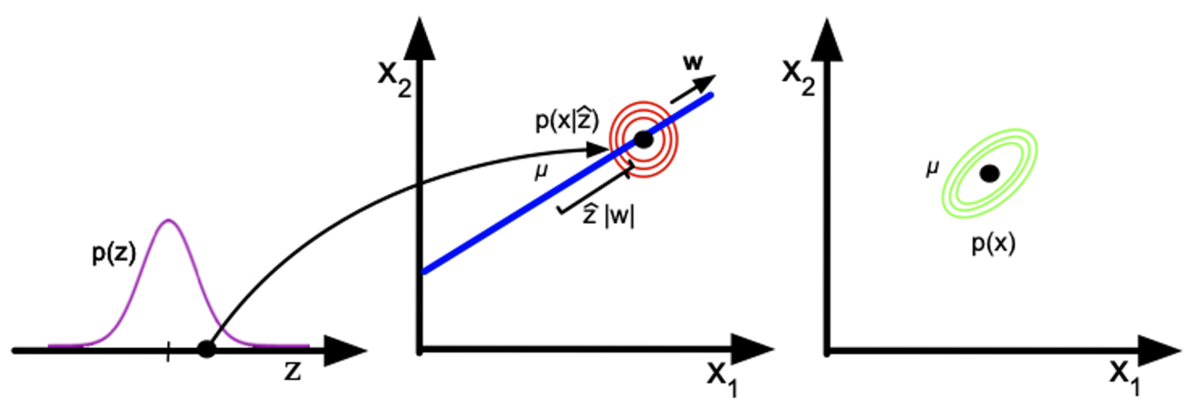
共分散行列Ψの性質
周辺分布はで表されるが,この分散に注目すると,
は対角行列に制限するべきであることが分かる。
なぜなら対角行列に制限しないと,として潜在因子を全く使わなくても,任意の共分散行列を特定できてしまうためである。
20.2.2 確率的主成分分析
因子分析において,
の列ベクトルが正規直交系をなす。
とする。
という場合,このモデルを確率的主成分分析(probabilistic PCA)と呼ぶ。
このとき,データ変数の周辺分布は,
平均・因子負荷行列の最尤推定量
平均および因子負荷行列の最尤推定量は,以下のようになる。
観測分散の最尤推定量
観測分散の最尤推定量は,
事後分布
事後分布であるについて考える。ガウス分布に対するベイズの定理から,
この式において,の極限を取ると,事後平均は
20.2.3 因子分析・確率的主成分分析のEMアルゴリズム
因子分析モデル・確率的主成分分析モデルのパラメータは,EMアルゴリズムを用いて求めることができる。
- Eステップ : パラメータを用いて,埋め込み
の事後分布(ガウス分布なので,平均と共分散行列)を求める。
- Mステップ : 埋め込み
という更新則になる。
ノイズのないの極限において,PPCAのEMアルゴリズムは以下のようになる。
- Eステップ :
(ただし,
)
- Mステップ :
主成分分析においてEMアルゴリズムを使うことのメリットは,
のとき,固有ベクトルを用いる方法よりも,高速に解が求められることがある。
- オンライン化ができる。
- 確率的主成分分析や,因子分析の混合モデルへの拡張ができる。
といったものが挙げられる。
20.2.4 パラメーターの識別不可能性
因子分析において,データの周辺分布における共分散行列は,
ここで,を満たす直交行列を用いて,異なる重み
を用いても,周辺分布の共分散行列は,
そのため,
- 解がスパースになるように事前分布を設定する。
- 有用な情報を得られる回転行列を選択する(バリマックス回転)。
といった対策を用いる。
まとめと感想
今回は,「第20章 次元削減」における,因子分析についてまとめた。
主成分分析と因子分析の違いと共通点
因子分析は,主に心理学分野で用いられる,という印象があるが,統計検定準1級でも用いられる。
いずれの手法も,データと潜在変数を用いるため,「似ているが異なる手法である」と言われることが多い。しかし,数式上の違いについてあまり差を感じることができなかった。
本節のように,確率的主成分分析(PPCA)を導入すると,PPCAは因子分析の特別な例であることが分かり,理解が深まった。
本記事を最後まで読んでくださり,どうもありがとうございました。
参考サイト
- 確率的機械学習:入門編 II |朝倉書店
- 『確率的機械学習:入門編』サポートサイト
- 原著関連
- Probabilistic Machine Learning: An Introduction : 原著のサポートページ
- pyprobml/notebooks.md at auto_notebooks_md · probml/pyprobml · GitHub : 原著の図作成用Notebooks一覧