「確率的機械学習 入門編II」読書メモ一覧 - jiku log
はじめに
持橋大地・鈴木大慈 監訳「確率的機械学習 入門編II」は,世界的に評価の高いK.P.Murphy著 "Probabilistic Machine Learning (Book1)" の和訳であり,確率モデルに基づく機械学習,深層学習といった基礎が丁寧に整理されている。
本記事は,「第20章 次元削減」の因子分析における,非線形因子分析などに関する読書メモである。
20.2 因子分析
20.2.5 非線形因子分析
因子分析は,観測データに関する周辺分布を求める際に,
- 潜在変数
の分布
- 潜在変数から観測データへの写像
を掛け合わせて,潜在変数を積分消去して求める。このとき,全ての分布が正規分布であるため,周辺分布は解析的に求めることができる。
この写像は,線形変換によって観測データがモデル化できると仮定していた。
この仮定を緩和する方法の1つは,写像としてニューラルネットワークのような非線形モデルとすることである。このとき周辺分布は以下のようになる。
これは,非線形因子分析(nonlinear factor analysis)と呼ばれる。非線形因子分析モデルの事後分布や最尤推定値は,厳密的に計算することができない。そのため,近似として変分自己符号化器などが用いられる。
20.2.6 混合因子分析
因子分析のモデルは,観測データが低次元ガウス分布にしたがう因子の線形変換でモデル化できる,と仮定していた。
この仮定を緩和するもう1つの方法は,局所的に線形的なモデルの組合せで表現するということである。
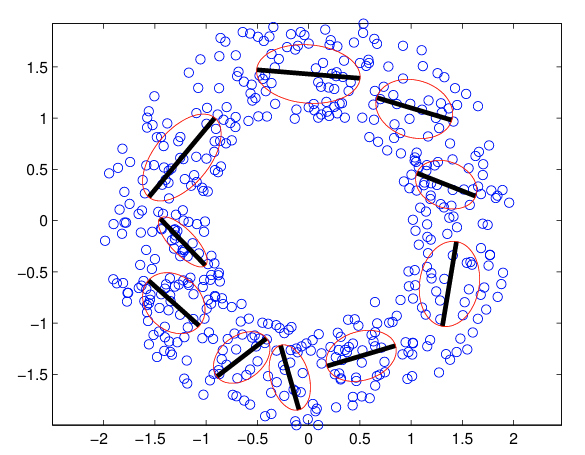
これは,個の正規分布モデルを組合わせたモデルとなる。
これは,混合因子分析(mixture of factor analysis)モデルと呼ばれる。
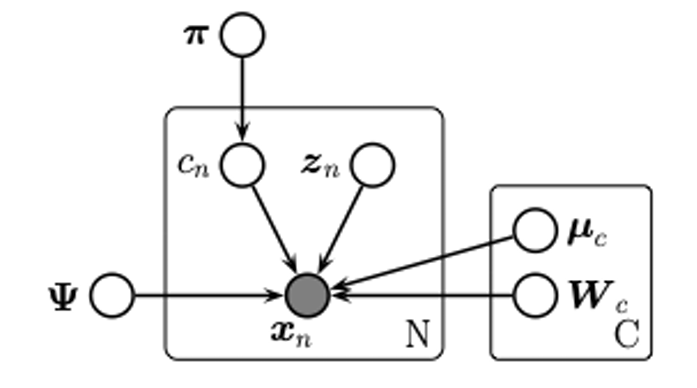
特別な場合として,を考えると,これは確率的主成分分析モデルの混合モデルとなる。
20.2.7 指数型分布族による因子分析
これまでのモデルは,観測データが実数値であるとしていたが,潜在変数から観測データの写像を変えることで,二値データやカテゴリー値の観測データをモデル化できる。
一般的には,出力分布(尤度)をガウス分布から,以下のような指数型分布族に変換すればよい。
パラメータ推定には,変分EMアルゴリズムなどを用いる。
二値主成分分析
尤度としてベルヌーイ分布を考える。
主成分分析の使い道として,ノイズ除去が挙げられる。すなわち,確率的主成分分析では,結果再構成されたにノイズのが乗っているというモデル化がされるが,ノイズ部分を除けば,ノイズ除去ができる。
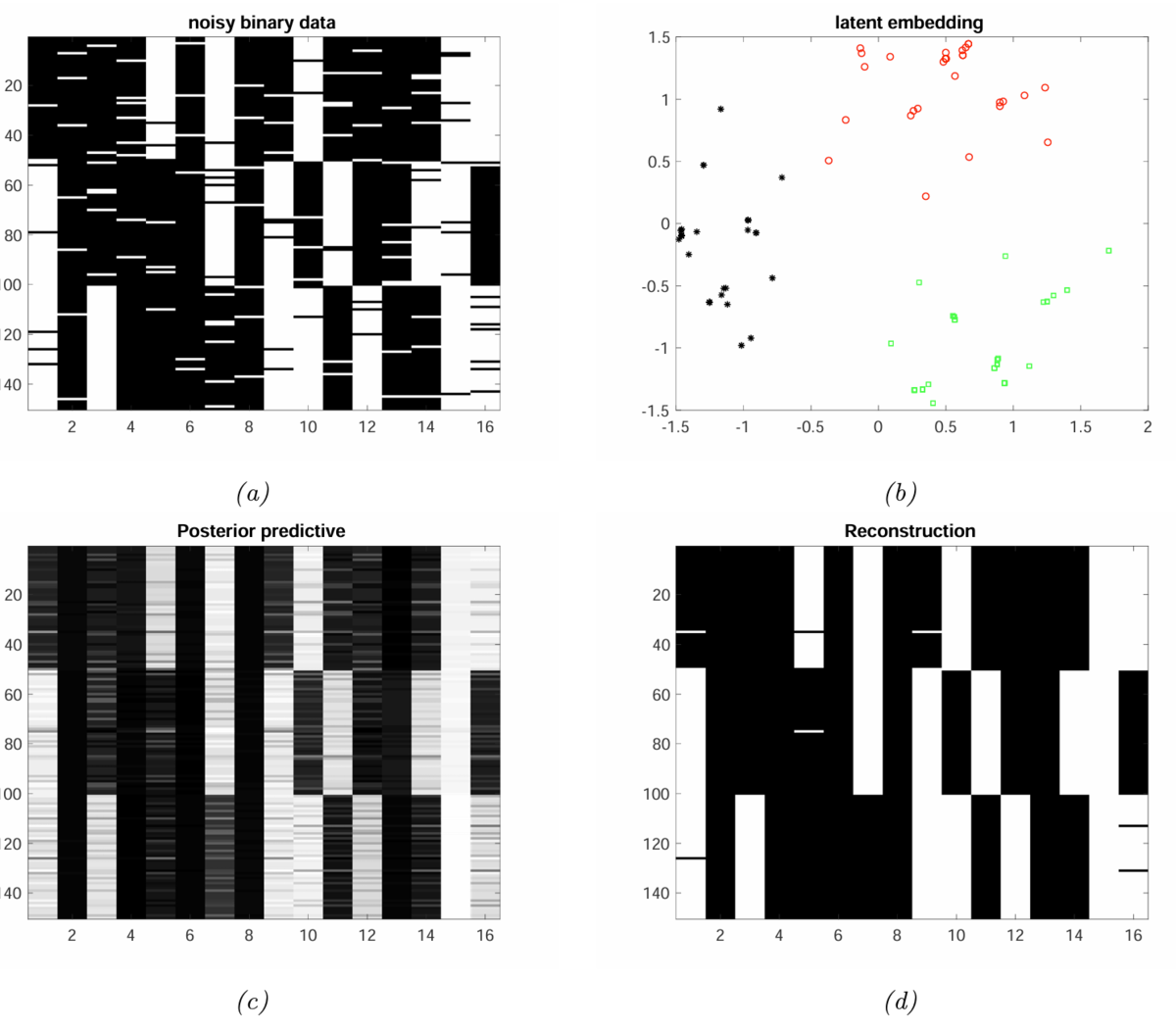
Figure20.13に,二値主成分分析によるノイズ除去の例を示す。
まず左上の(a)は,観測データセットである。このデータの説明は以下の通りである。
- 横方向が,データ
の次元(
)を示し,縦方向がデータ数
を示す。
- データの各次元の値は0または1であり,元のデータの一部がビット反転を起こしている。
- このデータは,
の値が①1~50,②51~100,③101~150 の3つのクラスタに分かれているように見える。
右上の(b)は,観測データが「3つのクラスタに分かれているように見える」ことを確認するために,潜在空間のデータの平均値
をプロットしたものである。
射影先のデータが,3つのクラスタをなしていることが見て取れる。
左下の(c)は,観測データの事後予測分布の最大値を示している。観測データはバイナリ値であるが,事後予測分布の最大値は連続値となっている。
右下の(d)は,事後予測分布の最大値に対して,閾値0.5で分けた結果である(0.5より小さければ0,大きければ1とする)。(a)と比べて,ノイズが除去されて,クラスタ構造がより明確に確認できる。
20.2.8 ペアデータのための因子分析モデル
本項では,対応関係のある2種類の観測変数と
が与えられている場合の,線形ガウス因子モデルについて説明する。
このような状況は,例えば「画像と音声」のような異なるモダリティや,複数のセンサデータに対応する。
教師あり主成分分析
教師あり主成分分析(supervised PCA)は,2種類の観測変数が共通の低次元表現を持つというモデルである。
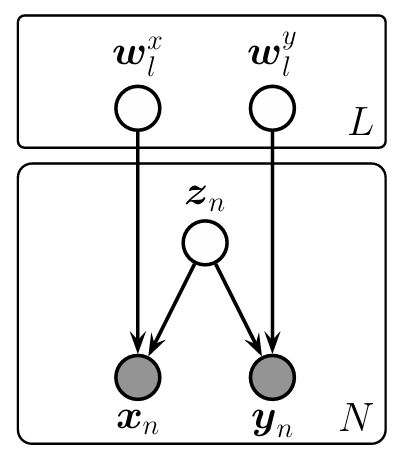
を積分消去することで,
が得られる。
がスカラーであれば,
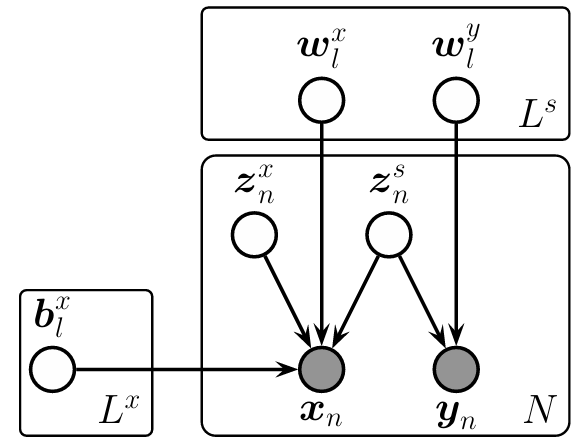
部分的最小二乗法
教師ありタスクの予測性能の改善方法として,入力にのみ独自のノイズ源が入るようにモデル化することである。
なぜなら,の変動は,必ずしもすべてが
の変動に寄与するわけではないためである。
このような部分的最小二乗法(partial least squares, PLS)のモデルは以下のようになる。
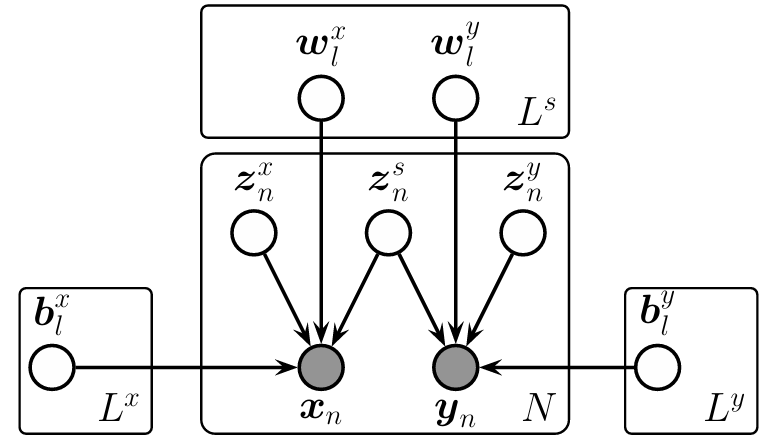
正準相関分析
と
に,それぞれ独自のノイズ源を設定したモデルは正準相関分析(canonical correlation analysis, CCA)モデルである。
まとめと感想
今回は,「第20章 次元削減」の因子分析における,非線形因子分析などについてまとめた。
非線形化の2パターン:非線形モデルと局所線形モデル
前節で導入した因子分析モデルは,線形ガウスモデルに基づくものであった。実用においては,これらを非線形化したいというモチベーションは当然湧いてくるわけであり,本書では
- ニューラルネットワークのような非線形モデルを用いる手法
- データがクラスタ構造を持つと仮定して,複数の局所線形モデルを用いる方法
を紹介していた。
これらのモデルは,データの局所的な性質を考えた時に線形であると仮定できれば局所線形モデルを用いることになり,またそうでないようなより複雑なモデルであれば非線形モデルを用いるのがよいと考えられる。
代表的手法の確率モデル化
ペアデータのための因子分析モデルを紹介していたが,これらは実務でもよく用いられている線形回帰モデルや部分的最小二乗法を確率モデルに拡張したものである,というのは非常に興味深かった。
機械学習モデルにおいては,確率モデルを導入することにより,出力を点ではなく分布で評価できるようになったり,また事前分布を用いることで出力を調整できるようになる。
伝統的な手法においてもこのような拡張ができることは,大きなメリットであると感じた。
本記事を最後まで読んでくださり,どうもありがとうございました。
参考サイト
- 確率的機械学習:入門編 II |朝倉書店
- 『確率的機械学習:入門編』サポートサイト
- 原著関連
- Probabilistic Machine Learning: An Introduction : 原著のサポートページ
- pyprobml/notebooks.md at auto_notebooks_md · probml/pyprobml · GitHub : 原著の図作成用Notebooks一覧