「確率的機械学習 入門編II」読書メモ一覧 - jiku log
はじめに
持橋大地・鈴木大慈 監訳「確率的機械学習 入門編II」は,世界的に評価の高いK.P.Murphy著 "Probabilistic Machine Learning (Book1)" の和訳であり,確率モデルに基づく機械学習,深層学習といった基礎が丁寧に整理されている。
本記事は,「第20章 次元削減」の多様体学習における,最大分散展開・局所線形埋め込み・ラプラシアン固有写像・t-SNEなどに関する読書メモである。
20.4 多様体学習
20.4.7 最大分散展開(MVU)
カーネル主成分分析では,動径基底関数カーネルなどを用いると,低次元埋め込みにならなかった。
この対策として,最大分散展開(maximum variance unfolding)では,潜在空間の多様体を伸ばすように,埋め込みを学習する。
学習の際には半整定値計画の問題として扱われる。
20.4.8 局所線形埋め込み
局所線形埋め込み(locally linear embedding)は,疎な固有値問題を用いる手法であり,データの局所的な構造により焦点を当てる手法となる。
局所線形埋め込みでは,データ多様体が各点の周りで局所的に線形であると仮定し,次の最適化問題を解くことで再構成重み
を計算する。
●ブログ筆者註 :
特に説明がなかったが,は
の
近傍であると思われる。
低次元埋め込みを求めるための損失関数は,この重みを用いて,
この解は,の,小さい順に取った非ゼロ固有値に対応する固有ベクトルによって与えられる。
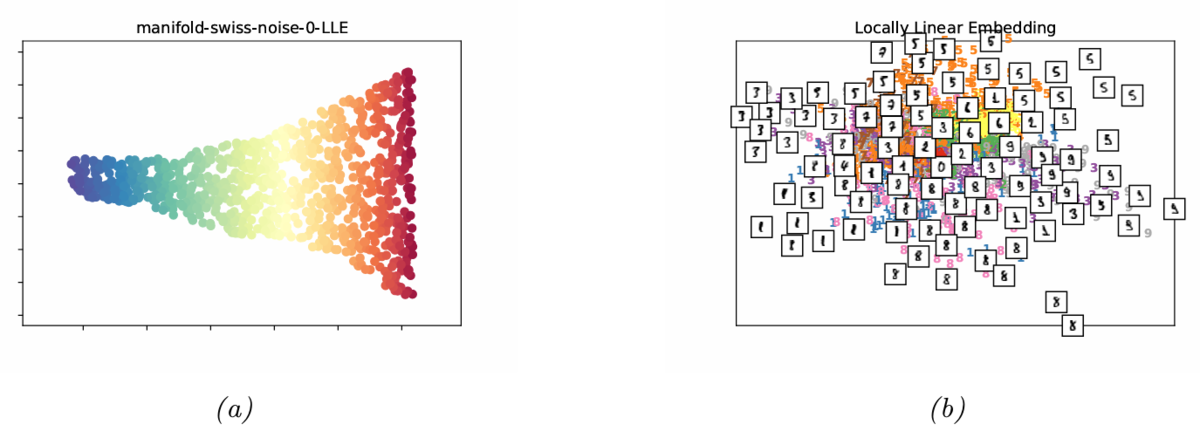
20.4.9 ラプラス固有写像
ラプラス固有写像(Laplacian eigenmap)あるいはスペクトル埋め込みは,各データ点とその近傍の間の重み付き距離が最小化されるように,データの低次元表現を計算する。
グラフラプラス作用素の固有ベクトルを用いた埋め込み計算
ラプラス固有写像では,以下の損失関数を最小化する埋め込みを見つける。
損失関数は,次のように書き直せる。
これを制約条件のもと最小化するのは,一般化固有値問題と等価である。
●ブログ筆者註 :
グラフラプラス作用素(グラフラプラシアン)の説明は,以下の過去記事に記載した。
stern-bow.hatenablog.com
20.4.10 t-SNE
SNE
確率的近傍埋め込み(stochastic neighbor embedding, SNE)は,高次元空間における類似度(条件付き確率)と低次元空間における類似度(条件付き確率)
が近づくように埋め込みを求める。
高次元空間における類似度(条件付き確率)と低次元空間における類似度(条件付き確率)
は,それぞれ
目的関数は,
t分布確率的近傍埋め込み
確率的近傍埋め込みでは,高次元空間では比較的遠くにある点が,低次元の埋め込み空間では近くにまとめられるという問題がおきる。
この対策の1つが,潜在空間の確率分布をより重い裾を持つ分布にするというものである。t-SNEでは,潜在空間の類似度にスチューデントのt分布を用いる。
t-SNEに類似した手法として,UMAP(Uniform Manifold Approximation and Projection)があるが,t-SNEより高速である。
まとめと感想
今回は,「第20章 次元削減」の多様体学習における,最大分散展開・局所線形埋め込み・ラプラシアン固有写像・t-SNEなどについてまとめた。
本節で登場した手法を整理すると,以下のようになる。
| 手法 | 特徴 |
|---|---|
| MDS | 距離保存 |
| Isomap | 測地距離保存 |
| Kernel PCA | カーネル非線形 |
| MVU | 多様体展開 |
| LLE | 局所線形構造 |
| ラプラス固有写像 | グラフラプラシアン |
| t-SNE | 確率近傍 |
これらの多様体学習手法の特徴をよく理解し,使い分けられるようになることが重要である。
本記事を最後まで読んでくださり,どうもありがとうございました。
参考サイト
- 確率的機械学習:入門編 II |朝倉書店
- 『確率的機械学習:入門編』サポートサイト
- 原著関連
- Probabilistic Machine Learning: An Introduction : 原著のサポートページ
- pyprobml/notebooks.md at auto_notebooks_md · probml/pyprobml · GitHub : 原著の図作成用Notebooks一覧