「確率的機械学習 入門編II」読書メモ一覧 - jiku log
はじめに
持橋大地・鈴木大慈 監訳「確率的機械学習 入門編II」は,世界的に評価の高いK.P.Murphy著 "Probabilistic Machine Learning (Book1)" の和訳であり,確率モデルに基づく機械学習,深層学習といった基礎が丁寧に整理されている。
本記事は,「第20章 次元削減」の多様体学習における,MDS・Isomap・KPCAなどに関する読書メモである。
20.4 多様体学習
本節では,高次元データセットの背後にある,低次元構造を復元する問題を考える。このような問題は,多様体学習(manifold learning)や非線形次元削減と呼ばれる。
自己符号化器などとの主な違いは,ノンパラメトリックな手法であること,すなわち訓練集合データの埋め込みを計算することが目的で,学習データ以外の汎化が扱えないという点である。
20.4.1 多様体とは?
大まかに言うと,多様体とは,局所的にユークリッド空間となるような空間のことである。
最も簡単な例は地球の表面であり,これは局所的には平面(2次元空間)であるが,3次元空間に埋め込まれたものである。
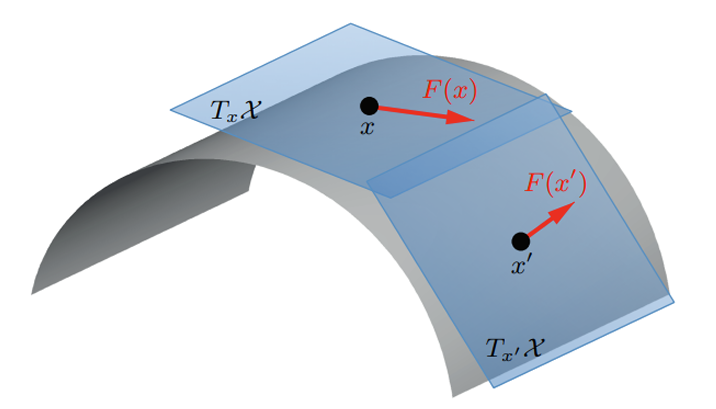
20.4.2 多様体仮説
多様体仮説(manifold hypothesis)とは,「高次元のデータ集合は,低次元の多様体上に載っている」という仮説である。
例えば,Figure 20.29の(a)は,数字の「6」を表す画像であり,(b)のようなランダムな点の集合とは全く異なっている。(a)において,画素は互いに独立ではなく,数字の6の形という低次元の構造から生成されている。
(a)の画像を少しずつ回転させて新たな画像を生成し,それを次元削減して2次元に埋め込んだものが(c)である。
この場合,数字の画像の集合(360枚)は,2次元に埋め込まれていることが分かる。このように,画像データの全体的次元(ambient dimensionality)は高次元でも,データの内在的次元(intrinsic dimensionality)は2次元であると言える。

20.4.3 多様体学習へのアプローチ
データから多様体を学習する方法としては,
- 多次元尺度構成法(MDS)
- Isomap
- カーネル主成分分析
- 最大分散展開(MVU)
- 局所線形埋め込み(LLE)
- ラプラシアン固有写像
- t-SNE
などがある。それぞれ,多様体の性質に関する異なる仮定を置いているため,異なる計算特性を持っている。
20.4.4 多次元尺度構成法(MDS)
多次元尺度構成法(multi-dimensional scaling, MDS)は,多様体学習のうち最もシンプルなアプローチである。
MDSでは,点間の距離を出来るだけ保つように低次元に配置するという目的で多様体学習を行なう。
MDSにおいて,データは中心化されているとする。すなわちデータ行列に対して,全てのサンプルから平均を引いたデータ行列
を作成し,埋め込みの歪み(strain)
距離としてユークリッド距離を用いる方法は,古典的多次元尺度構成法(classical MDS)と呼ばれるが,これはPCAによる次元削減と等価である。
なおMDSは,元のデータそのものは分からなくても,データ間の距離が分かっているときにも利用可能である。
計量的多次元尺度構成法
古典的多次元尺度構成法は,距離尺度としてユークリッド距離を用いる。これを一般化して,以下のようなストレス関数を定義すると,任意の相違度を扱うことができる。
この最適化問題は,勾配降下法やSMACOFと呼ばれる上界最適化アルゴリズムが用いられる。
非計量的多次元尺度構成法
点間の距離を用いる代わりに,点の類似度のランキングだけを一致させることが考えられる。こおとき,距離を順位に単調に変換する関数
を用いて,以下の損失関数を定義する。
この目的関数は,
を固定して,関数
を回帰によって最適化する。
- この
という反復によって最適化される。
サモン写像
計量的多次元尺度構成法は,大きな距離を一致させることを重視する。一方で,局所的な構造を捉えるためには,小さな距離を重視することが重要である。
小さな距離を重視するためには,小さな距離で割ることで重み付する,以下の損失関数が考えられる。
ただしこの方法は,目的関数が非凸になることや,小さな距離を捉えることに重点を置き過ぎているといった問題点がある。
20.4.5 Isomap
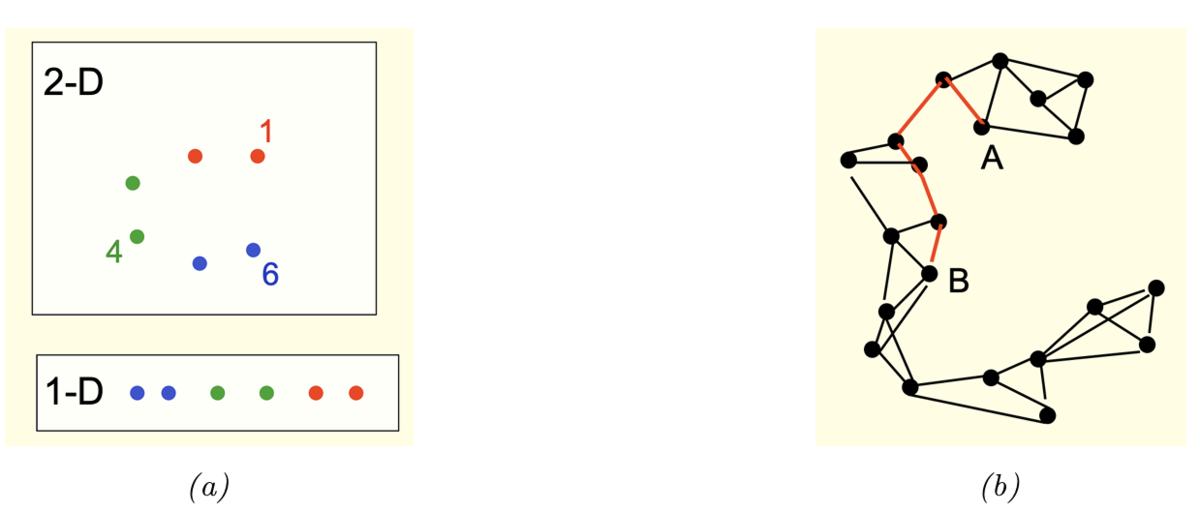
高次元のデータによっては,多様体上では距離が遠くても,近くにあるように見えることがある。
例えばFigure 20.32(a)について,1次元では点1-点4間の距離よりも,点1-点6間の距離の方が大きいが,2次元では距離の大きさが逆転する。
これに対処する方法が,データの近傍グラフを構成し,データ間の多様体距離を,そのグラフに沿った距離で近似するという方法である(Figure 20.32(b)参照)。
この手法はIsomapと呼ばれる。
20.4.6 カーネル主成分分析
主成分分析(および古典的多次元尺度構成法)では,全てのデータ間の内積行列を用いていた。
これを非線形な距離尺度で置き換えるために,とするのがカーネル主成分分析(kernel PCA)である。
カーネルPCAを用いると非線形化ができるが,動径基底関数カーネルを用いると,これは無限次元の特徴量空間への写像に対応しているため,特徴量空間を削減するのではなく,拡張してしまう。そのため,次元削減にはあまり有用な手法ではなくなる。
Figure 20.30に,次元削減のテストデータを示す。
(a)はスイスロールと呼ばれるデータセットで,3次元のデータであるが,潜在空間は2次元である。
(b)は手書き数字画像データである。
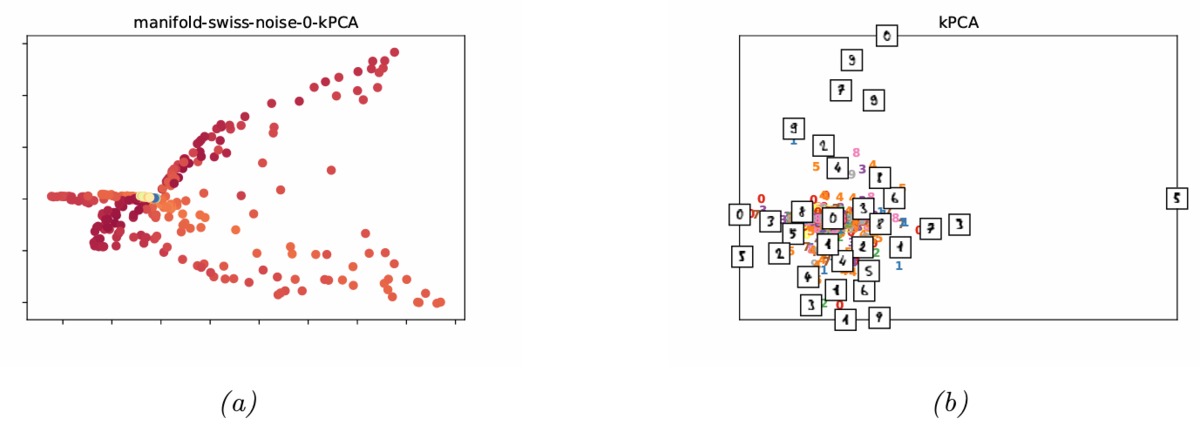
Figure 20.36にカーネルPCAをこれらのデータセットに適用した例を示す。
(a)は,もともとは2次元の潜在空間上で色が徐々に変化するようなデータであるが,カーネルPCAによる次元削減結果ではこのような特徴が表れていない。
(b)も,文字の形状ごとに近くに配置されることが期待されるが,このようには配置されていない。

まとめと感想
今回は,「第20章 次元削減」の多様体学習における,MDS・Isomap・KPCAなどについてまとめた。
多様体仮説は製造業データにおいても自然な仮説
多様体仮説は,「高次元のデータは,低次元の多様体上に張り付いている」という仮説であった。これは,製造業で扱うデータのうち,例えばプラントデータなどにあてはまる。
これは,
- 入力・出力関係を持つシステムのデータであるため,入力と出力の間に相関がある。
- センサが故障した時の対策として,センサを冗長に取り付けていることがあり,似たようなデータが計測される。
といった理由からである。
多様体学習の手法は,多様体の性質にさまざまな仮説を置いている。実データに対して多様体学習を適用する際には,どの仮説が妥当であるか検討する必要があるため,手法ごとの特徴は把握するようにしておきたい。
本記事を最後まで読んでくださり,どうもありがとうございました。
参考サイト
- 確率的機械学習:入門編 II |朝倉書店
- 『確率的機械学習:入門編』サポートサイト
- 原著関連
- Probabilistic Machine Learning: An Introduction : 原著のサポートページ
- pyprobml/notebooks.md at auto_notebooks_md · probml/pyprobml · GitHub : 原著の図作成用Notebooks一覧