はじめに
データのつながりに着目した新たなデータ分析の手法を学ぶために,黒木裕鷹・保坂大樹 著 「データのつながりを活かす技術〜ネットワーク/グラフデータの機械学習から得られる新視点」を読むことにした。
本記事は,「第5章 ノード埋め込み」における,NetMFに関する読書メモである。
- 本書の紹介ページ
5.3 ノード埋め込み
ノード埋め込みの手法のうち,本章で紹介するものは下表の通りである。
| 手法 | 着目する類似性 | 学習の方針 |
|---|---|---|
| DeepWalk | 近接性 | ランダムウォーク |
| node2vec | 近接性 | 遷移確率を編集したランダムウォーク |
| LINE | 近接性 | ノード分布やエッジ分布の再構成 |
| NetMF | 近接性 | 特定の行列の行列因子分解 |
| struc2vec | 構造的類似性 | 多層ネットワークからのランダムウォーク |
NetMF
DeepWalkやnode2vec,LINEなどとは異なるアプローチのアルゴリズムを統一的に解釈できる枠組みとして,本項ではNetMF(Network Embedding as Matrix Factorization)を紹介している。
Jiezhong Qiu et al. "Network Embedding as Matrix Factorization: Unifying DeepWalk, LINE, PTE, and node2vec"
arxiv.org
行列因子分解としての再解釈
行列因子分解は,大きな行列を小さい行列の積に分解する手法である。NetMFの枠組みでは,これまでに紹介した分散表現の学習アルゴリズムは,それぞれ暗黙的に「ある行列を行列因子分解している」とみなせる。
たとえばDeepWalkは,以下の行列の行列因子分解と等価であるということが示されている。ただし,
: 隣接行列
: 次数行列
: ウィンドウサイズ
: ネガティブサンプリングのサンプルサイズ
である。
行列因子分解という共通の枠組みの統一して考えることで,いくつかの利点が得られる。
- 元の手法よりも高い性能が期待できる。
- 元のアルゴリズムではサンプリングを行なっているため,最適化したい関数と実際に行なわれる学習処理にギャップがあるが,行列因子分解を用いるとこのギャップがなくなり,性能向上が見込める。
- アルゴリズムを行列形式で理論的に解析できるようになる。
- 複数の行列を分解したときに得られる埋め込み表現の差分を定量化できるため,近似アルゴリズムが検討しやすくなる。
一方で,大きなネットワークを処理する場合に,分解の対象となる行列も大きくなり計算時間が必要になる,というというデメリットも存在する。
伝統的なネットワーク解析手法とのつながり
本項では,ノード埋め込みの一種として捉えられる次元削減手法であるスペクトル埋め込み(spectral embedding)を紹介している。
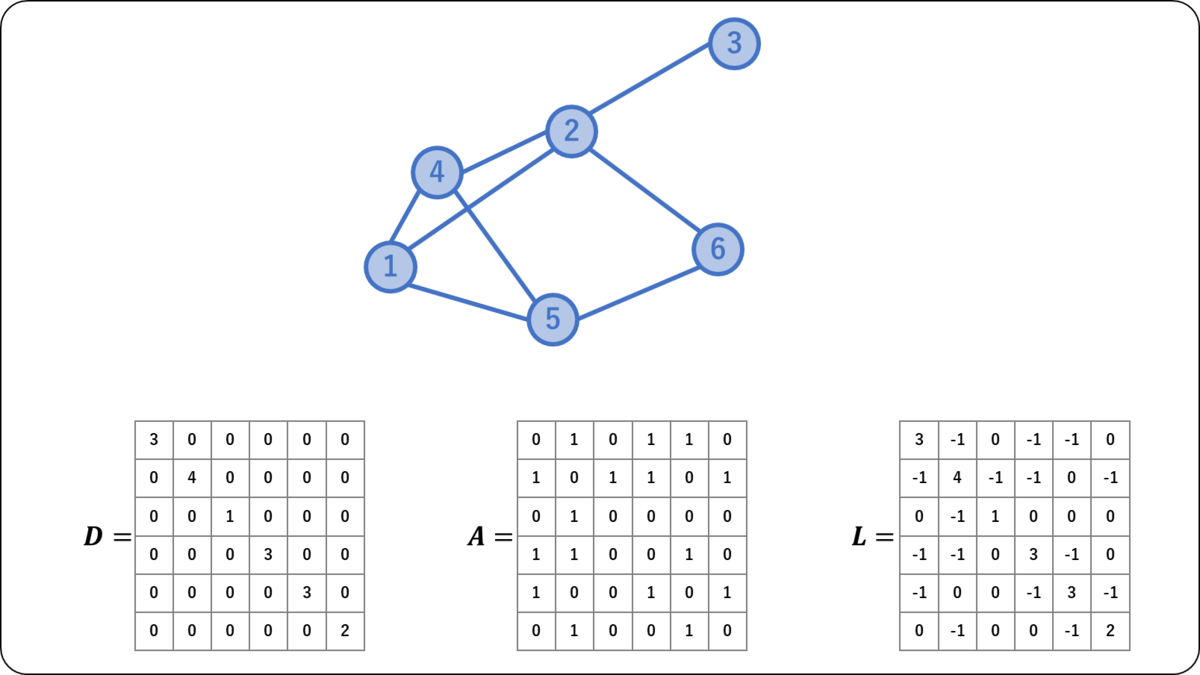
ネットワークデータを行列で表す方法のうち,代表的なものにグラフラプラシアン(graph Laplacian)が挙げられる。グラフラプラシアンは,次数行列と隣接行列
を用いて計算される。
また,各ノードの次数で正規化した式で定義されることもある。
グラフラプラシアンの例を挙げる。
グラフラプラシアンの性質
ノードに紐づく何らかの特徴量のベクトル (各ノード
に対応する成分を
とする)を,グラフラプラシアンを用いて変換してみる。
成分を確認する。ただし,は,ノード
の次数である。
少し丁寧に確認してみる。
- 1行目
行目の成分を取り出す。
- 1行目→2行目
は
に接続するノードの集合であることを用いて書き換えている。
- 2行目→3行目
- 次数行列
成分は,隣接行列
なので,次数行列・隣接行列を用いない表現に書き換えている。
- 次数行列
したがって,グラフラプラシアンによる1次変換は,隣接するノードとの特徴量の差を捉えることができる。
同様に,グラフラプラシアンによる2次形式を考える。ノード数はであるので,
であることを用いると,
となる。グラフラプラシアンの2次形式は,隣接ノードとの特徴量の差の2乗を足し合わせたものであり,ネットワーク上における特徴量の滑らかさを表す。
グラフラプラシアンの固有値分解
グラフラプラシアンに固有値分解を行なって得られる固有値,固有ベクトル
について考える。
の2次形式は非負であるので,
は半正定値行列であり,固有値も非負となる。
また任意のネットワークは連結成分ごとにブロック対角化できるので,0である固有値の数はネットワークの連結成分数と等しくなる。
今回例に挙げているネットワークの連結成分数は1であるため,0である固有値も1つだけ存在する。
また今回例に挙げているネットワークのグラフラプラシアンにおける固有値・固有ベクトルを実際に計算してみると,
- 固有値が大きいと,対応する固有ベクトルの値はノードによってプラスになったりマイナスになったり,値の変動が大きい。
- 固有値が小さいと,対応する固有ベクトルの値の変動は小さい。
ということが分かる。
すなわち,固有値が小さいと固有ベクトルの値の変動が小さく,低周波成分に相当し,逆に固有値が大きいと高周波成分に相当する。
この考え方は,グラフフーリエ変換(Graph Fourier Transform; GFT)としての解釈につながる。
ネットワーク上の特徴量(信号)ベクトルに対するグラフフーリエ変換は,
で表される。ただしは固有ベクトルを並べた行列である。
また逆変換は
で定義される。このようにネットワーク上の特徴量(信号)ベクトルを表現する際に,高周波成分・低周波成分のみを用いれば,ネットワーク上のハイパスフィルタ・ローパスフィルタを考えることができる。
固有ベクトルをとしたときに,ノード
に対する埋め込みベクトル
は以下のように得ることができる。
このようにしてベクトルをえる手法のことをスペクトル埋め込み(spectral embedding)と呼ぶ。スペクトル埋め込みは,ネットワーク構造を反映した低次元のベクトルが得られることから,ノード埋め込みの一種として捉えられる。
まとめと感想
今回は,「第5章 ノード埋め込み」における,NetMFについてまとめた。
グラフラプラシアンの存在は知っていたが,で定義する理由がよくわからなかった。ただ,2次形式を計算するとに半正定値行列になることが分かるなど,扱いやすい性質があることが理解できた。
またグラフフーリエ変換についても,固有値分解を用いることによって,ネットワーク構造を反映した低次元のベクトルが得られるといった興味深い性質があることが理解できた。
一見して関係が薄いように思えていたが,ネットワークと線形代数,信号解析には深いつながりがあり興味深かった。
本記事を最後まで読んでくださり,どうもありがとうございました。