はじめに
データのつながりに着目した新たなデータ分析の手法を学ぶために,黒木裕鷹・保坂大樹 著 「データのつながりを活かす技術〜ネットワーク/グラフデータの機械学習から得られる新視点」を読むことにした。
本記事は,「第5章 ノード埋め込み」における,LINEに関する読書メモである。
- 本書の紹介ページ
5.3 ノード埋め込み
ノード埋め込みの手法のうち,本章で紹介するものは下表の通りである。
| 手法 | 着目する類似性 | 学習の方針 |
|---|---|---|
| DeepWalk | 近接性 | ランダムウォーク |
| node2vec | 近接性 | 遷移確率を編集したランダムウォーク |
| LINE | 近接性 | ノード分布やエッジ分布の再構成 |
| NetMF | 近接性 | 特定の行列の行列因子分解 |
| struc2vec | 構造的類似性 | 多層ネットワークからのランダムウォーク |
LINE
LINE (Large-scale Information Network Embedding)はランダムウォークを利用せずにノード埋め込みを学習する方法である。
Jian Tang et al. "LINE: Large-scale Information Network Embedding"
arxiv.org
1次の近接性とは,ノードの直接的なつながりのことである。学生Bと学生Cは直接つながっているので,1次の近接性を持つ。
2次の近接性とは,別のノードを挟んだつながりのことである。学生Aと学生Bは,学生Dまたは学生Eまたは学生Fを介してつながっているので,2次の近接性を持つ。
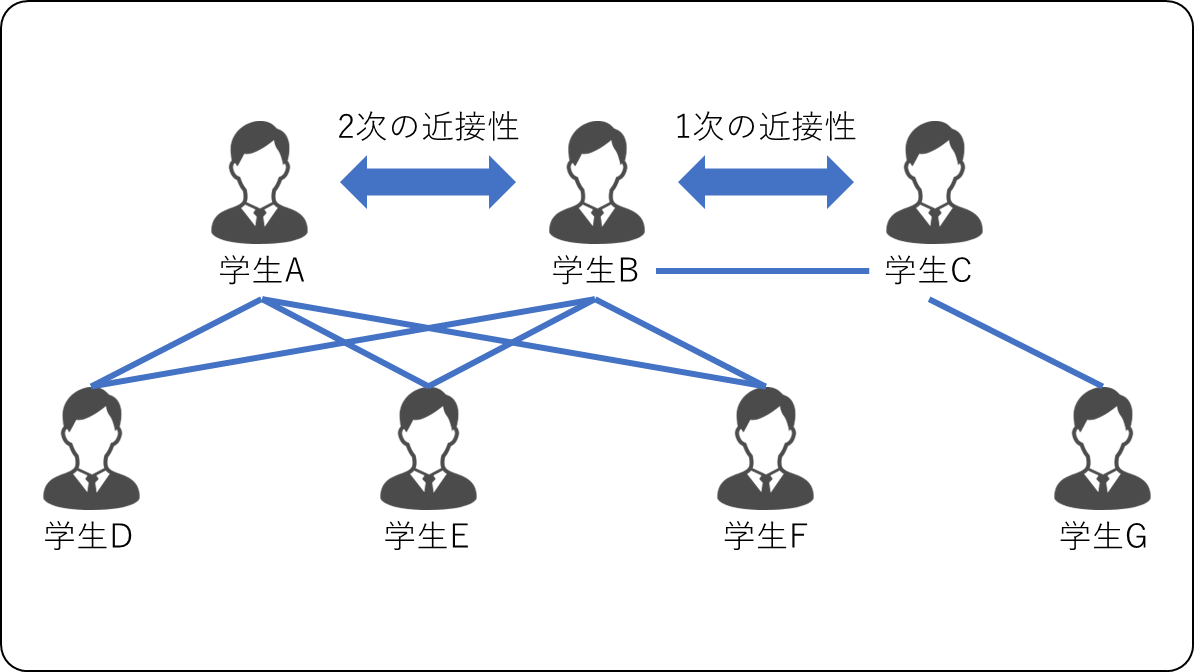
LINEでは,1次の近接性を捉えた分散表現と,2次の近接性を捉えた分散表現を別々に学習する。
1次の近接性を捉えるために,ノードと
間のエッジが観測される確率を,分散表現を用いて以下の式で定義する。
1次の近接性を捉えた分散表現を学習するために,上式で計算される確率を,以下の値に近づけるように分散表現を更新する。
\begin{align}
\hat{p}_1(v, v') =
\begin{cases}
\frac{1}{\lvert E \rvert} & \text{if $(v, v') \in E$}, \\
0 & \text{otherwise} \\
\end{cases}
\end{align}
上記の学習方針あh,ネットワーク上のエッジの分布をノードの分散表現同士の内積によって再構成していると捉えることができる。
2次の近接性を捉えた分散表現を学習するために,ノードの接続ノードとして
が観測される確率を,分散表現を用いて以下の式で定義する。ただし,
は
と接続するノードの集合であり,
は
と接続する任意のノードである。
2次の近接性を捉えた分散表現を学習するために,上式で計算される確率を,以下の値に近づけるように分散表現を更新する。
\begin{align}
\hat{p}_2(v \lvert v') =
\begin{cases}
\frac{1}{\lvert \mathcal{N}(v) \rvert} & \text{if $(v, v') \in E$}, \\
0 & \text{otherwise} \\
\end{cases}
\end{align}
1次の近接性・2次の近接性のそれぞれを捉えるように学習されたベクトルを結合することで,双方の特徴を兼ね備えた分散表現として利用できる。
DeepWalkやnode2vecと異なり,LINEではランダムウォークを利用していないが,2次の近接性を反映した分散学習では,経路長1のランダムウォークをサンプリングする設定と同様の学習をしていることになる。
まとめと感想
今回は,「第5章 ノード埋め込み」における,LINEについてまとめた。
LINEではランダムウォークを用いない代わりに,1次・2次の近接性を用いて分散表現を学習するので,ランダムウォークを用いた手法と比べて,計算量の観点で違いがあるのではと考える。実装する際には,計算量の比較も行なってみたい。
本記事を最後まで読んでくださり,どうもありがとうございました。