「確率的機械学習 入門編II」読書メモ一覧 - jiku log
はじめに
持橋大地・鈴木大慈 監訳「確率的機械学習 入門編II」は,世界的に評価の高いK.P.Murphy著 "Probabilistic Machine Learning (Book1)" の和訳であり,確率モデルに基づく機械学習,深層学習といった基礎が丁寧に整理されている。
本記事は,「第21章 クラスタリング」における,K平均法に関する読書メモである。
21.3 K平均法クラスタリング
階層的凝集クラスタリングの欠点とK平均法における対策
21.2節で紹介した階層的凝集クラスタリング(HAC)の欠点と,本節で紹介するK平均法(K-means)の利点を下表にまとめた。
| HAC | K-means | |
|---|---|---|
| 1. 計算量 | |
|
| 2. 類似度 | 類似度行列を事前に計算する必要がある。 | 類似度行列は不要である(ユークリッド距離を用いる)。 |
| 3. 最適化 | HACはアルゴリズムでしかなく,損失関数が不明。 そのためクラスタリング結果の良さが評価できない。 |
コスト関数が定義でき,最適化問題として定式化される。 |
21.3.1 アルゴリズム
をクラスター中心とする。クラスタリングでは,データ
に対して,以下のように最も近いクラスター中心のクラスター番号を割り当てる。
クラスター中心は,各クラスターに含まれるデータの平均として計算できる。
このアルゴリズムは,歪み(distortion)と呼ばれる,以下緒のコスト関数の最小化問題とみなせる。
さらに
21.3.2 具体例
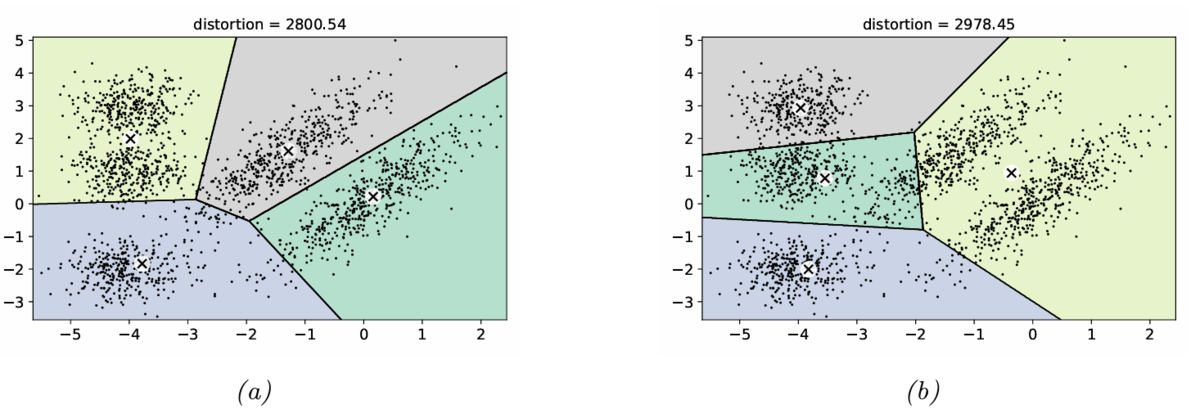
Figure21.7に,2次元平面上の点に対するクラスタリング結果を示す。
K平均法は,クラスター中心によるボロノイ分割であることが分かる。
また(a)と(b)では,(b)の方がクラスタリング結果の品質が悪いが,歪み(distortion)の大きさは(b)の方が大きい。
21.3.3 ベクトル量子化
ベクトル量子化(vector quantization)は,実数ベクトルを圧縮し,対応する離散シンボル
に置き換えることである。
このシンボルは,個の符号表(codebook)
のインデックス番号になっている。
これを用いると,実数ベクトルを圧縮する(encode)処理は,
したがって,符号表の品質を測るコスト関数は,再構成誤差として定義できる。
K平均法はクラスタリングで用いられるが,ベクトル量子化は画像圧縮などで用いられる。
21.3.4 K-means++アルゴリズム
K平均法クラスタリングは,初期値の選び方によって結果が変わる。単純な対策としては,初期値を変えて再計算することだが,計算が遅くなる。
よりよい方法としては,
- 最初の点はランダムに選ぶ。
- 各データ点に一番近いクラスター中心との距離を計算する。
- 距離の二乗に比例した確率で,次のクラスター中心を選ぶ。
という手順でクラスター中心を選ぶことである。これにより,重心から離れた点が次のクラスター重心として選ばれやすくなるため,ひずみを削減することができる。この手法はK-means++法と呼ばれる。
21.3.5 Kメドイドクラスタリング
K平均法クラスタリングでは,クラスターに含まれるデータ点の平均をクラスター中心にする。そのため,クラスター中心が実際のデータに該当する保証がない。
Kメドイド法は,クラスター内において,他のデータ点との非類似度の平均が最も小さいデータ点(メドイド)をクラスター中心に選ぶ方法である。そのため,データ点がクラスター中心になる。
Kメドイド法のメリットとして,外れ値の影響を受けにくいという特徴がある。
21.3.6 高速化法
K平均法クラスタリングでは,クラスター内のデータ点とクラスター中心との距離計算が発生し,これが計算のボトルネックになる。
K平均法クラスタリングの計算時間削減のために,三角不等式を利用して入力とクラスター中心間の距離の上限・下限を追跡することで,冗長な計算を省く方法が提案されている。
21.3.7 クラスター数Kの選択
再構成誤差の利用はNG
K平均法クラスタリングでは,損失関数として再構成誤差が用いられる。そのため,クラスター数Kを変えながら再構成誤差を計算してクラスター数を選ぶことが考えられる。
しかし,クラスター数を増やしながら再構成誤差を計算すると,再構成誤差は単調に減少するため,クラスター数の選択に再構成誤差を用いることは出来ない。
BIC
クラスター数の選択方法として,混合ガウスモデルのように適切な確率モデルを利用することで,データの対数周辺尤度ことが考えられる。
対数周辺尤度の近似として,以下のBICスコアを利用することができる。
シルエット係数
シルエット係数(silhouette coefficient)は,クラスタ間距離とクラスタ内距離に基づく指標である。
シルエット係数は,
: 同じクラスター内の平均距離(小さい方がよい)
を用いて,
シルエット係数は-1から+1までの間を動き,+1に近ければよく分離できていることを示す。一方で-1に近ければ,番目のデータが誤ったクラスターにいることを示す。
全体的な指標としては,平均を取ればよい。
まとめと感想
今回は,「第21章 クラスタリング」における,K平均法についてまとめた。
K平均法は,階層的凝集クラスタリングと並んで最も基本的なクラスタリング手法であるが,K平均法では損失関数が定義できることなど,階層的凝集クラスタリングの欠点に対応した手法であることがよく理解できた。
クラスタリングにおいては,クラスタ数の選択方法が重要になる。本節では,BICやシルエット係数などの選択規準が説明されていた。
もしクラスタリング結果が可視化できる場合は,これらの選択規準と可視化結果を確認し,うまくクラスタリングできているか確認できるようにしていきたい。
本記事を最後まで読んでくださり,どうもありがとうございました。
参考サイト
- 確率的機械学習:入門編 II |朝倉書店
- 『確率的機械学習:入門編』サポートサイト
- 原著関連
- Probabilistic Machine Learning: An Introduction : 原著のサポートページ
- pyprobml/notebooks.md at auto_notebooks_md · probml/pyprobml · GitHub : 原著の図作成用Notebooks一覧