はじめに
Pythonによるベイズモデルの実装をきちんと学ぼうと思い,森賀新・木田悠歩・須山敦志 著 「Pythonではじめるベイズ機械学習入門」を読むことにした。
本記事は,第3章「回帰モデル」のうち線形回帰モデルに関する読書メモである。
- 本書の紹介ページ
3.1 線形回帰モデル : 線形単回帰モデル
3.1.1. モデル概要
本節では,まず線形回帰モデルについて説明している。
ここで,線形とは係数パラメータと特徴量ベクトル
の関係が線形関係,という意味であり,
が曲線(例えば多項式)であれば,曲線がフィッティングされる。
ベイズ線形単回帰モデルでは,係数パラメタに事前分布を設定する。
3.1.2. 実装
サンプルコードの動作確認しながら,挙動を確認した。
github.com
データの準備
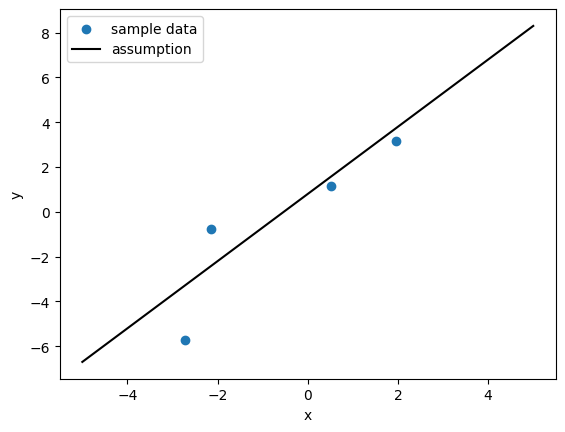
学習に用いたデータを図示すると以下のようになる。回帰係数の真の値は,である。
PyMCライブラリのインポート
本書ではpymc3で説明しているが,2024年12月現在,動作確認はpymcで行なった。
- サンプルコード
#import pymc3 as pm import pymc as pm
モデルの定義
PyMCにおいて,モデルの定義は以下のように記述する。このコードにおいて,の事前分布は
としている。
- サンプルコード
# モデルの定義 with pm.Model() as model: # 説明変数 x = pm.Data("x", x_data) # 推論パラメータの事前分布 w1 = pm.Normal('w1', mu=0.0, sigma=10.0) w2 = pm.Normal('w2', mu=0.0, sigma=10.0) # 尤度関数 y = pm.Normal('y', mu=w1*x+w2, sigma=1.0, observed=y_data)
MCMCによる事後分布からのサンプリング
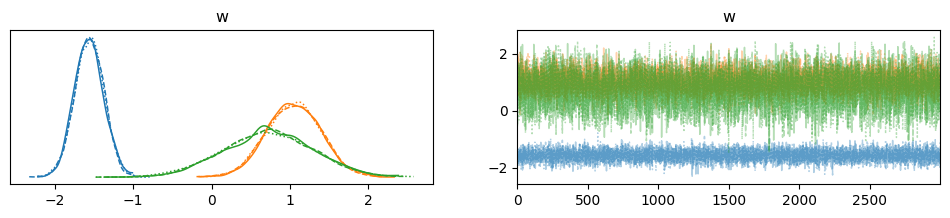
PyMCを用いて,MCMC(具体的にはNUTS)による事後分布からのサンプリングを行なった。チェーン数は3としている。チェーン数3回分のサンプルの分布とトレースプロットは下図の通りである。
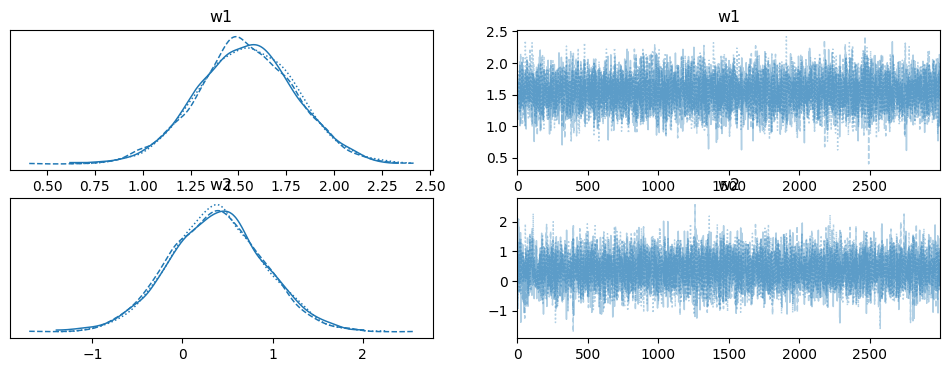
3回とも定常分布に落ち着いているように見える。
次に,事後分布の可視化を行なった。
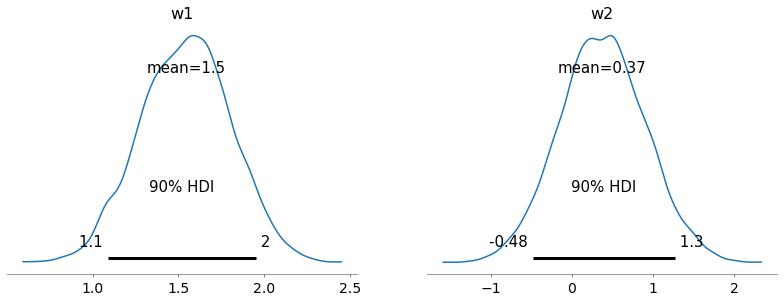
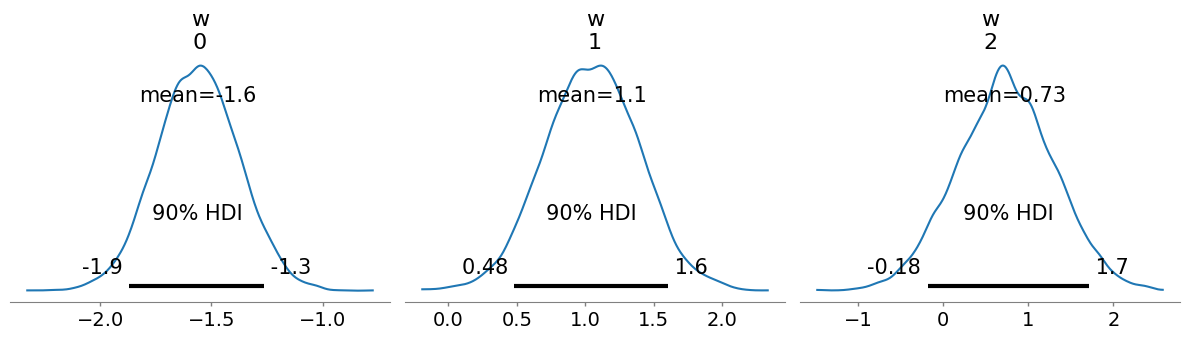
係数パラメータの推定値のサンプル平均はそれぞれ
であった。真値である
からは外れているように見えるが,事後分布の90%信用区間の間には収まっていた。
サンプル数がであり,サンプル数が十分に確保できていなかったためであると考えられる。
予測分布の算出
サンプルコードにしたがい,新たなデータを与えて,予測分布の算出を試みたが上手くいかなかった。
- コード
# 検証用データ x_new = np.linspace(-5, 5, 10) with model: # 検証用データを推論したモデルに入力 pm.set_data({"x": x_new}) # 予測分布からサンプリング pred = pm.sample_posterior_predictive(trace, random_seed=1) y_pred_samples = pred['y']
- 出力
(中略) ValueError: shape mismatch: objects cannot be broadcast to a single shape. Mismatch is between arg 0 with shape (4,) and arg 1 with shape (10,). (中略)
どうやら,学習用データが4点分で,検証用データが10点分なので,形状が合わなかったようである。そのため,以下のように修正した。
- コード
# 検証用データ x_new = np.linspace(-5, 5, 10) # 新しいモデルを作成 with pm.Model() as pred_model: # 説明変数 x = pm.Data("x", x_new) # 検証用データで初期化 # 事前分布 (学習済みモデルから) # Convert xarray DataArray to NumPy array using .values w1 = pm.Normal('w1', mu=trace.posterior['w1'].mean().values, sigma=trace.posterior['w1'].std().values) w2 = pm.Normal('w2', mu=trace.posterior['w2'].mean().values, sigma=trace.posterior['w2'].std().values) # 尤度関数 (観測値なし) y = pm.Normal('y', mu=w1*x+w2, sigma=1.0) # 予測分布からサンプリング pred = pm.sample_posterior_predictive(trace, var_names=['y'], random_seed=1) y_pred_samples = pred.posterior_predictive['y']
上記のように,MCMCサンプルの結果(trace)から,などの情報を取り出し,新たにモデルを作成して,そのうえで予測分布からサンプリングを行なった。
このy_pred_samplesという変数は,(チェーン数, サンプル数, 検証用データの点数)という次元を持っていた。
- コード
print(y_pred_samples.shape)
- 出力
(3, 3000, 10)
そのため,描画は最初のチェーンの情報のみを取り出すようにした。
- コード
# 予測分布からのサンプルをプロット for i in range(1000): plt.plot(x_new, y_pred_samples[0,:][i], lw=1, alpha=0.01, color='g', zorder=i) plt.scatter(x=x_data, y=y_data, marker='o', label='sample data', zorder=i+2) plt.xlabel('x');plt.ylabel('y');plt.xlim(-5,5) plt.legend();
- 出力
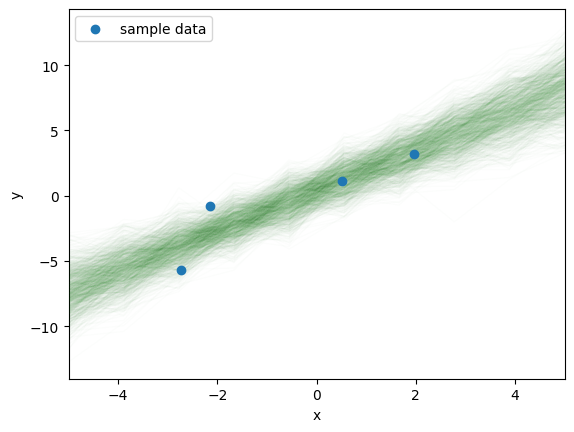
この図の意味を改めて確認する。
# 予測分布からサンプリング pred = pm.sample_posterior_predictive(trace, var_names=['y'], random_seed=1)
の部分では,10個分の入力 = np.linspace(-5, 5, 10)について,10個分の出力
を,
という式によって得ている。
1セット分のを用いた,
と
の折れ線グラフを作成すると,下図のようになる。
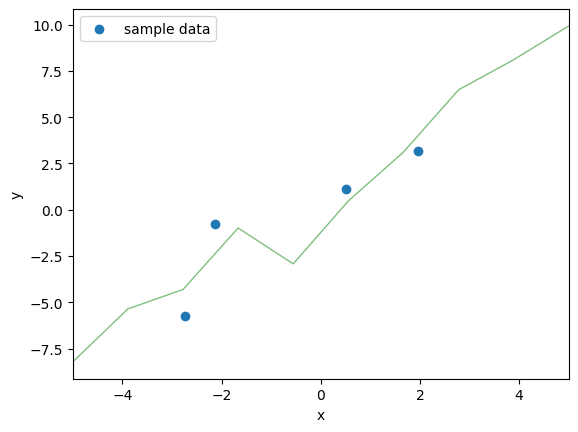
ここで回帰係数ともに乱数なので,同じ入力
に対して,出力
はばらつく,すなわち分布を持つことになる。
10セット分のを用いた,
と
の折れ線グラフを作成すると,下図のようになる。
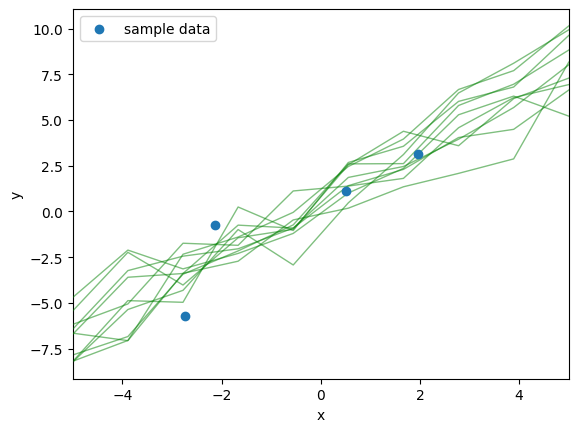
このセット数を増やしていくと,予測分布からサンプリングのプロットが得られる。
3.2 線形回帰モデル : 線形重回帰モデル
3.2.2. 実装
サンプルコードの動作確認しながら,挙動を確認した。
github.com
データの準備
データは人工データを用いる。回帰係数の真の値は,である。
モデルの定義
PyMCにおいて,モデルの定義は以下のように記述する。このコードにおいて,の事前分布は
としている。
- サンプルコード
# モデルの定義 with pm.Model() as model: # 説明変数 x = pm.Data("x", x_data_add_bias) # 推論パラメータの事前分布 w = pm.Normal('w', mu=0.0, sigma=10.0, shape=3) # 尤度関数(ravelでshapeを(4,1)から(4,)に変換) y = pm.Normal('y', mu=w.dot(x.T), sigma=1.0, observed=y_data.ravel())
まとめと感想
ベイズ線形回帰についてコードを動かしながら学んだ。
サンプルコードは,本書のPyMC3と2024年12月版のPyMCで差があったので,公式サイトから最新の情報を反映しながら動作確認を行なった。
本記事を最後まで読んでくださり,どうもありがとうございました。