はじめに
データを使って仮説の生成と検証を行なうための方法であるベイズ最適化を学ぶために,今村秀明・松井孝太 著「ベイズ最適化 ー適応的実験計画の基礎と実践ー」を読むことにした。
本記事は,「第2章 ブラックボックス関数のベイズモデリング」における,ベイズ線形回帰モデルに関する読書メモである。
- 本書の紹介ページ
- 補足資料
『ベイズ最適化―適応的実験計画の基礎と実践―』補足資料 (2023.8.28 ダウンロード)
- 関連コード
第2章 ブラックボックス関数のベイズモデリング
2.1 ベイズ線形回帰モデル
ベイズ最適化では,関数を近似する際にベイズモデリングを用いる。良く用いられるモデルとして,ベイズ線形回帰モデルとガウス過程回帰モデルが用いられる。
関連記事
ベイズ線形回帰は,森賀新・木田悠歩・須山敦志 著 「Pythonではじめるベイズ機械学習入門」を読んだ際にも出てきた話題であり,読書メモは以下にまとめた。
stern-bow.hatenablog.com
線形回帰モデルの尤度
ベイズ線形回帰では,はじめに線形回帰モデルを尤度関数の形で表す。
線形回帰モデルは,
と表す。ただし,は基底関数である。
上式を確率分布の形で表すと,
となる。
個の観測データ
が得られた時の尤度は,
となる。
ベイズ線形回帰モデル
ベイズ線形回帰モデルは,モデルパラメータに確率分布を設定したモデルである。ベイズ線形回帰モデルにおいて興味があることは,主に以下の2つである。
- 学習データから,モデルパラメータ
の事後分布を推定する
- 新しい入力
が得られたときに,学習結果を用いて出力
の予測分布を算出する
である。
2.について,予測分布のグラフィカルモデルは以下の通りである。
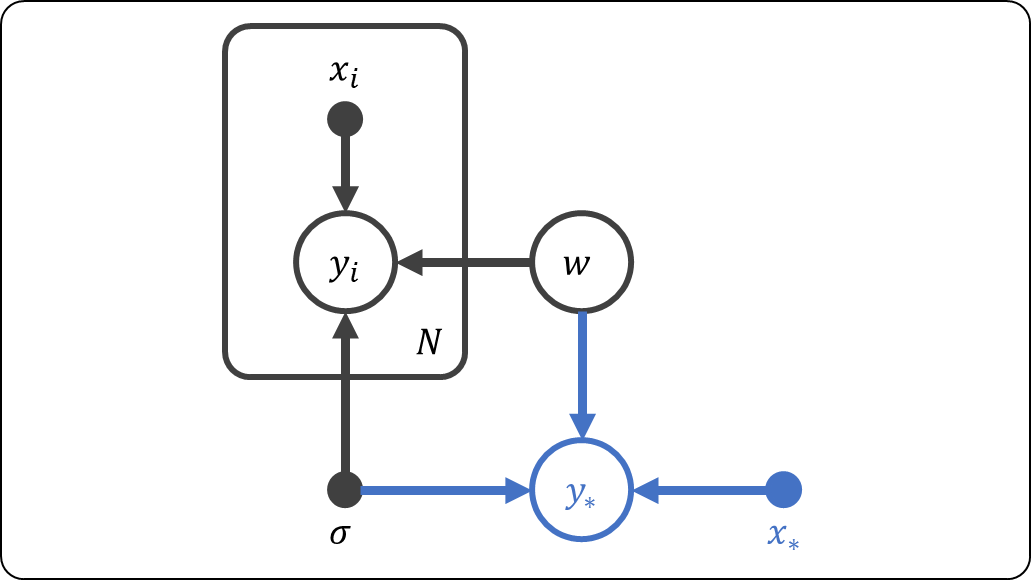
予測分布は,以下の式で表される。
この式は,左辺をを加えて同時分布にして,
を積分消去することで得られるが,各項を分解して考えると意味が理解しやすい。
- モデルパラメータの事後分布
から,乱数
- この
を算出する。
- 上記2つのステップを複数回繰り返して,平均化する。
尤度やモデルパラメータがしたがう分布が正規分布であれば,予測分布も正規分布になる。
数値実験
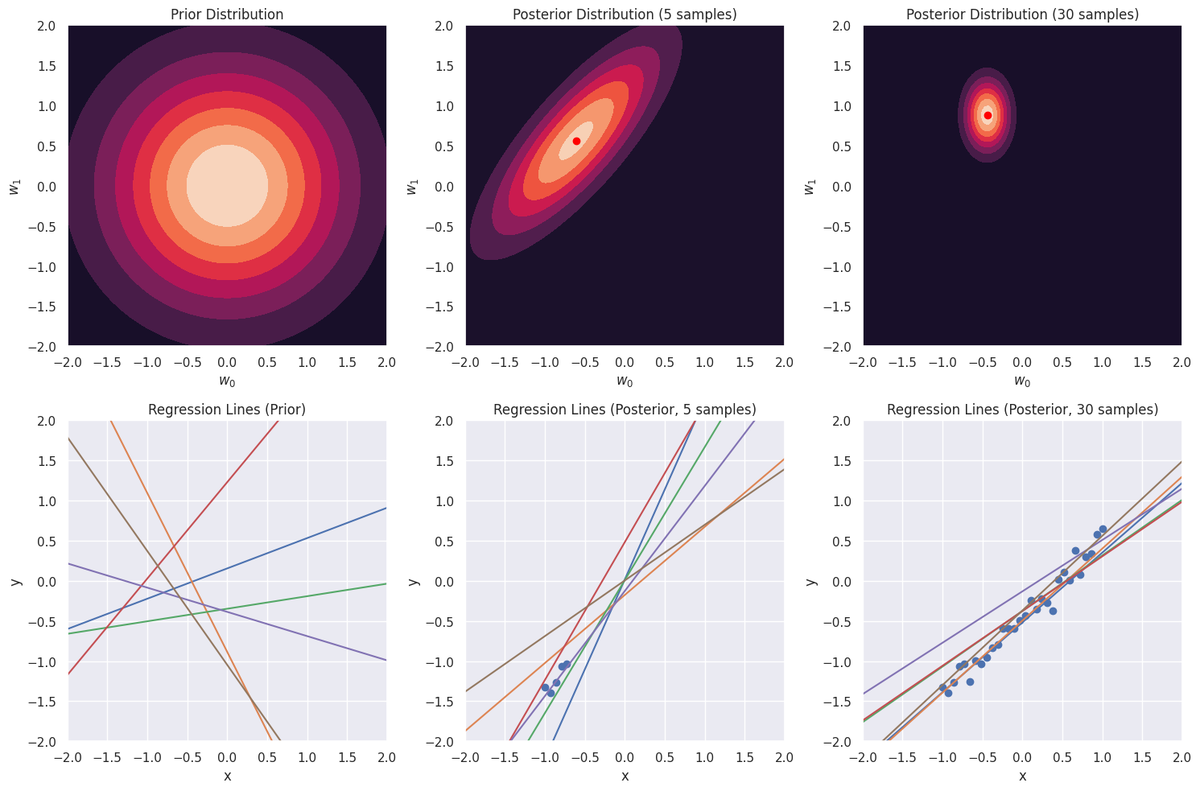
本書P30 図2.4を参考に,ベイズ線形回帰モデルを実装した。
真の関数をとして,観測ノイズを加えた30点のデータを学習用データとした。
学習用データを全く与えない場合(事前分布に相当)と,学習用データを5点サンプルして与えた場合と,学習用データを30点すべて用いた場合で,事後分布と回帰直線を作成した。
- 左上は,モデルパラメータ(切片 :
,傾き :
)に学習用データの情報が含まれないので,どちらも平均が0になっている。
- 左下は,事前分布が生成するモデルパラメータである。平均0,分散共分散行列が
の多変量正規分布にしたがう値がモデルパラメータになっているので,傾きが負になっているものも存在する。
- 中上は,学習用データを5点サンプルして与えた場合のモデルパラメータの事後分布である。分散共分散行列の楕円が事前分布よりは小さくなっている。
- 中下は,学習用データを5点サンプルして与えた場合のモデルパラメータの事後分布から得られたモデルパラメータを用いて作成した回帰直線である。
- 右上は,学習用データ30点をすべて用いた場合のモデルパラメータの事後分布である。分散共分散行列の楕円がさらに小さくなり,値が絞られていることが確認できる。
- 右下は,学習用データ30点をすべて用いた場合のモデルパラメータの事後分布から得られたモデルパラメータを用いて作成した回帰直線である。
学習用データのサンプル数が増えるほど,事後分布の分散が小さくなっていることが確認できる。
上記の分析用pythonコードはこちら。
まとめと感想
今回は,「第2章 ブラックボックス関数のベイズモデリング」のうち, ベイズ線形回帰モデルについて学んだ。
ベイズ最適化においては,サンプル数とモデルの分散の関係が重要になってくると考えられるが,ベイズ線形回帰モデルは,学習用データのサンプル数が増えるとモデルパラメータの分散が小さくなるので,ベイズ最適化のモデルとして用いられることには納得感があった。
次項はガウス過程回帰であるが,モデルの柔軟性などについて比較してみたい。
本記事を最後まで読んでくださり,どうもありがとうございました。