はじめに
Pythonによるベイズモデルの実装をきちんと学ぼうと思い,森賀新・木田悠歩・須山敦志 著 「Pythonではじめるベイズ機械学習入門」を読むことにした。
本記事は,第4章「潜在変数モデル」のうちベイジアン主成分分析に関する読書メモである。
- 本書の紹介ページ
4.2 行列分解モデル
行列分解モデル(Matrix Factorization Model)は,観測値を表す行列を,より次元の小さい行列の積に分解することである。
ノイズを除外した本質的なデータの特徴を得られることや,欠損値を補完できることがその利点である。
4.2.1 モデル概要 : 主成分分析
主成分分析(Principal Component Analysis)は,多次元データの座標軸を,データの分散が最大になる方向に変換する手法である。
高次元データの次元圧縮などの目的で利用される。
4.2.2 モデル概要 : ベイジアン主成分分析
主成分分析は,「高次元のデータを低次元に圧縮する」という発想であったが,ベイジアン主成分分析(Bayesian PCA)はこれとは逆に,次元の潜在変数
の線形変換にノイズが句分かり,
次元の観測変数
が得られると考える(ここで,
である)。
すなわち,観測されるデータは高次元([tex : D]次元)であるが,実質的な情報は次元の潜在変数により表現できると考える。
個のデータ点からなる観測変数の集合を
,対応する潜在変数の集合を
とする。ただし,
,
とする。
潜在変数は平均が0,分散共分散行列が単位行列であるガウス分布に従うとする。
次に,潜在変数が得られた下での観測変数
について,
と表す。
ベイジアン主成分分析ではさらに,の事前分布を設定する。ただしここでは簡単のため,
に固定し,
の事前分布のみを設定する。
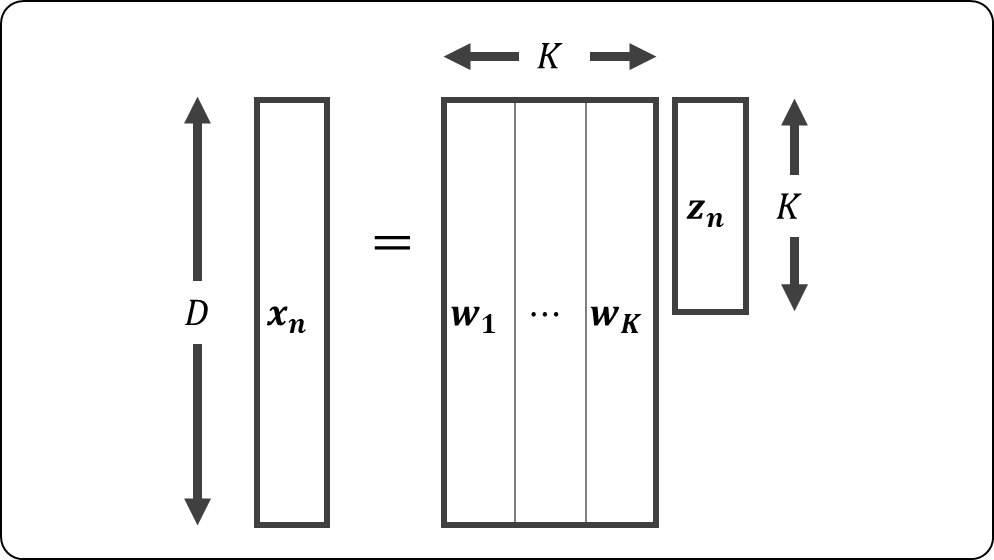
本書のP152では,の列ベクトルを
,事前分布
を,
と説明しているが,の関係は下図のようになり,
となるはずなので,実際は,事前分布
は
となる。
は正の値を取るため,事前分布は半コーシー分布となる。
モデル式をまとめると,以下のようになる。
4.2.3 実装
サンプルコードを動かしながら,挙動を確認した。
github.com
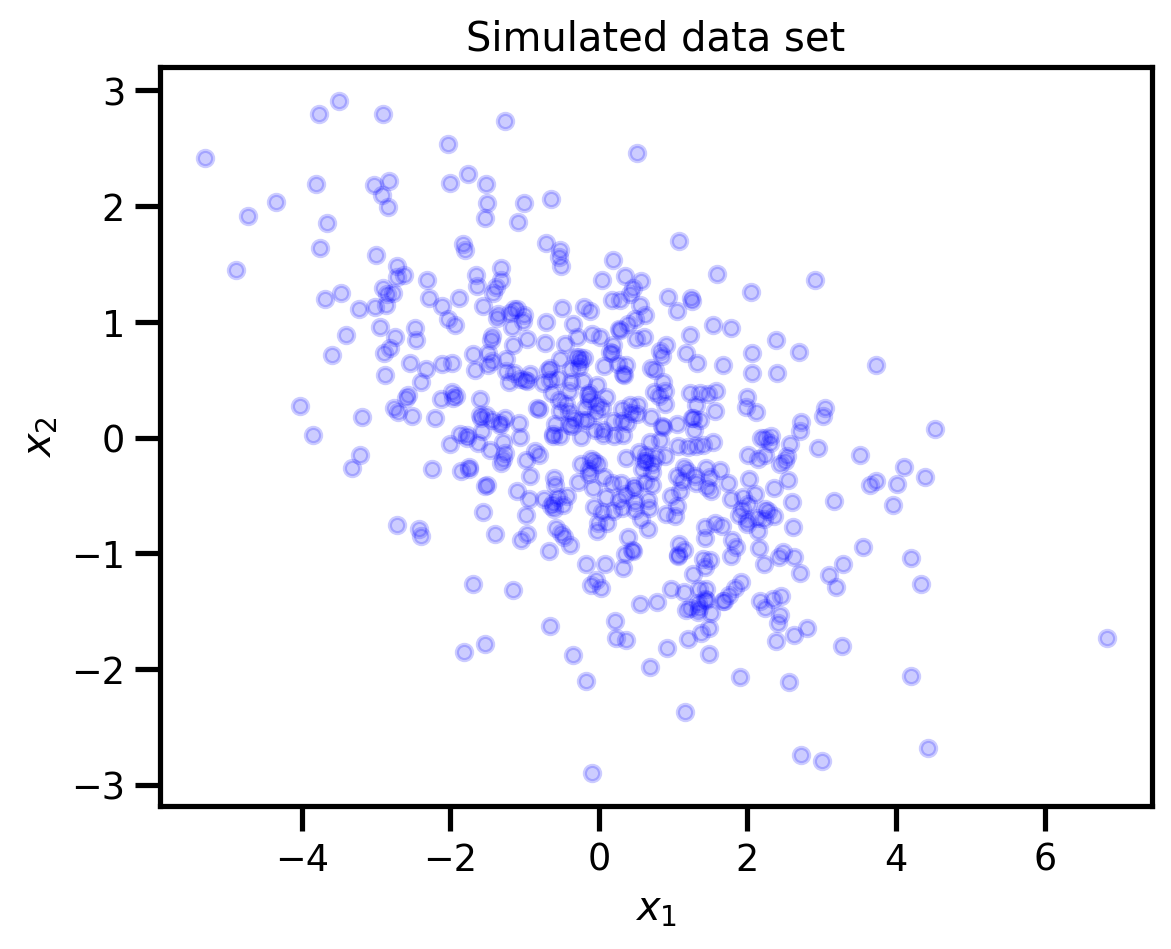
データの準備
以下のような観測データを対象とする。
モデルの定義
4.2.2節で示したようなモデルを定義する。
ただし,観測変数の次元は,潜在変数の次元は
,サンプル数は
,標準偏差の真値は
としている。
また変換行列は2行・1列の行列となる。
推定対象は,変換行列の列ベクトル
の値と,標準偏差
である。
MCMCによる事後分布からのサンプリング
MCMCによるサンプリングを行なう。2024年12月現在,PyMC3ではなくPyMCを使うので,ライブラリのインポート設定は以下のようになる。
#import pymc3 as pm import pymc as pm
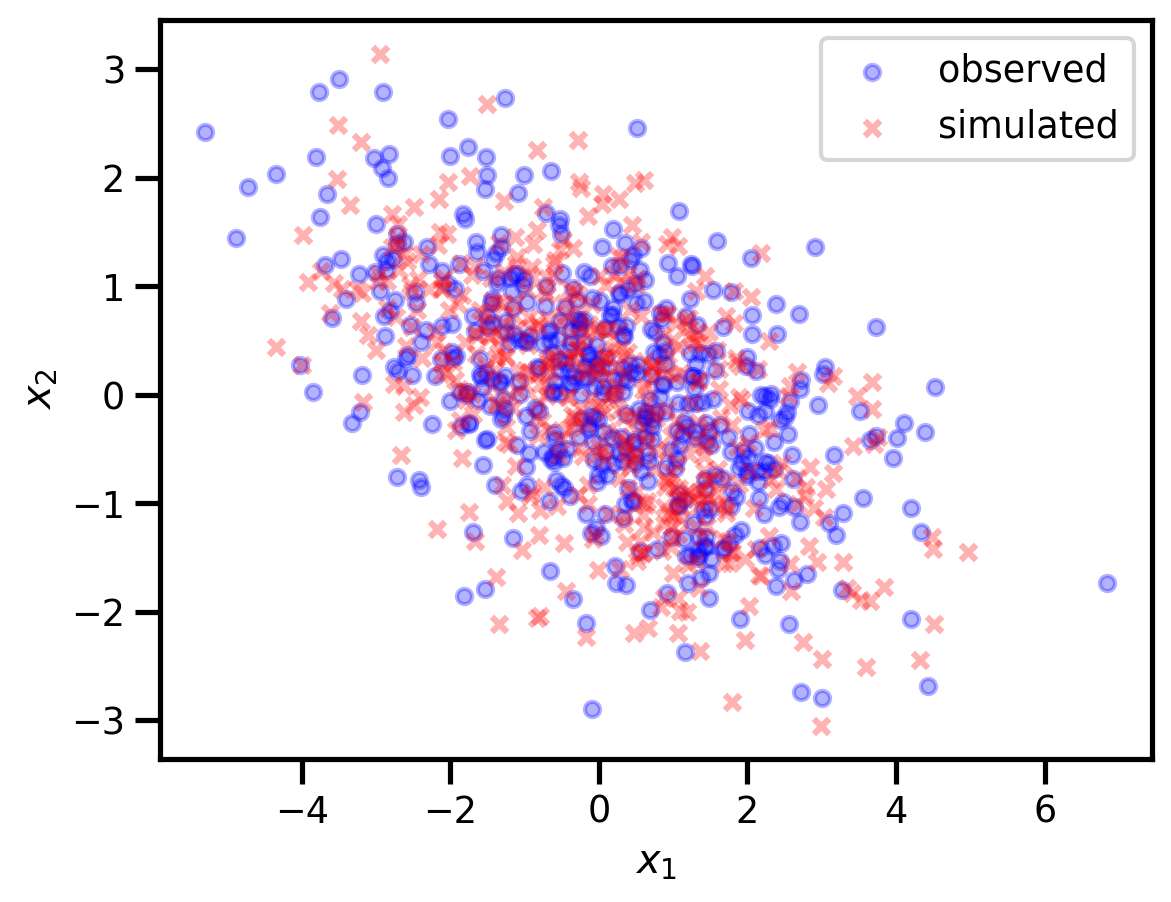
サンプルの分布とトレースプロットは下図の通りである。
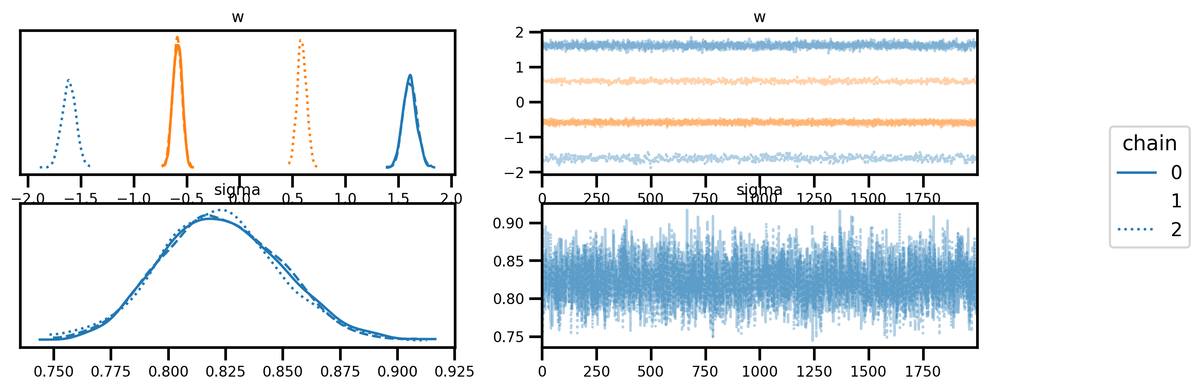
主成分分析における固有値・固有ベクトルの計算において,符号が反転することがある。トレースプロットを確認しても,チェーンによっては値の正負が入れ替わることがあるので,MCMCにおいても同様の現象が確認できた。
予測分布
サンプルコードはそのままでは動かなかったので,以下のように修正した。
- サンプルコード(修正前)
with model: x_post = pm.sample_posterior_predictive(trace, 1, random_seed=42)
- サンプルコード(修正後)
with model: x_post = pm.sample_posterior_predictive(trace, var_names=['x'], random_seed=42)
修正後のコードでは,取り出したい変数を”var_names”引数によって指定する必要がある。
予測分布の生成のコード変更により,描画用コードも変わってくる。
- サンプルコード(修正前)
plt.scatter(x_train[0, :], x_train[1, :], color='blue', s=30, alpha=0.3, label='observed') plt.scatter(x_post['x'][0, 0, :], x_post['x'][0, 1, :], color='red', marker='x', s=30, alpha=0.3, label='simulated') plt.legend() plt.xlabel('$x_1$') plt.ylabel('$x_2$')
- サンプルコード(修正後)
plt.scatter(x_train[0, :], x_train[1, :], color='blue', s=30, alpha=0.3, label='observed') plt.scatter(x_post.posterior_predictive['x'].sel(chain=[0], draw=[0], x_dim_2=[0]), x_post.posterior_predictive['x'].sel(chain=[0], draw=[0], x_dim_2=[1]), color='red', marker='x', s=30, alpha=0.3, label='simulated') plt.legend() plt.xlabel('$x_1$') plt.ylabel('$x_2$')
事後分布を表す変数"x_post.posterior_predictive"は4つの要素から構成され,
- chain : チェーン
- draw : サンプリング結果
- x_dim_2 : データの行番号
- x_dim_3 : データの列番号
のようになっている。
今回は,3つのチェーンのうち1つを取り出すために,0番目の要素を指定している。
また今回は散布図を作成するので,データ(2行・500列)のうち,x軸は0番目の行,y軸は1番目の行に指定してしている。
- 出力