はじめに
本書は,岩波書店「統計科学のフロンティア」シリーズ(全12巻)の第4巻である。初版発行は2004年であり,当時最先端だった統計科学の話題を,第一人者の先生方がコンパクトにまとめているというものである。
第4巻「階層ベイズモデルとその周辺―時系列・画像・認知への応用―」は3部+補論の構成となっており,以下のような章立てになっている。
- 第I部 事前情報を利用した複雑な系の解析 (石黒真木夫)
- 第II部 非線形ダイナミカルシステムの再構成と予測 (松本隆)
- 第III部 視覚計算とマルコフ確率場 (乾敏郎)
- 補論 帰納推論と経験ベイズ法―逆問題の処理をめぐって― (田邉國士)
本記事は,第II部 非線形ダイナミカルシステムの再構成と予測の読書メモである。
本書・第II部の興味深かった点
本書・第II部のテーマは,非線形ダイナミカルシステム(ノイズを含む非線形な時系列モデル)を,ニューラルネットワークでモデリングし,階層ベイズモデルの枠組みでデータに当てはめる,というものである。
本書において,興味深かった点は以下の3点である。
- 1. モデル選択も含めて階層ベイズモデルの枠組みで行なっている。
時系列モデルを,ニューラルネットワークを用いて推定するので,時間遅れや,中間層の素子数
といったハイパーパラメータが出てくる。
このハイパーパラメータについて,グリッドサーチを用いることなく,「モデル周辺尤度」という枠組みを用いてベイズモデルの枠組みで完結させている。

- 2. 事後分布を様々な近似を用いて求めている。
ベイズ統計で難しいのは,事後分布や予測分布を求めることである。本書でも予測分布を求めることがテーマの1つであるが,予測分布を2次近似やMAP推定量を駆使することで近似的に求める方法を説明している。
これにより,予測分布の平均値を求める方法を説明している。
ベイズ統計学の強みは,予測値を点で求めるのではなく,幅を持った分布で求めることができる点である。事後分布を求める方法として,マルコフ連鎖モンテカルロ法(MCMC)の1種であるハミルトニアン・モンテカルロ法を用いる方法を紹介している。
第1章 問題提起と導入
本章では,分析対象とする非線形ダイナミカルシステムについて説明している。
ダイナミカルシステム
ダイナミカルシステムとは,ある時点の値
が,過去の値
によって決まるシステムのことである。
本書では,このうち離散系について説明する。
関数が線形であれば,将来値である
の挙動(解軌道)を予測することは扱いやすいが,非線形の場合,たとえば
のようなものでも解軌道は複雑になることが知られている。
また,上記のように入力を含まない系を自律ダイナミカルシステム,入力を含むシステム
を非自律ダイナミカルシステムと呼ぶ。
第2章 ニューラルネットワーク
本書では,非線形な関数として,ニューラルネットワークを用いる。ニューラルネットワークモデルを用いる際に検討することは以下の3つである。
- 関数族
を選ぶ
- ニューラルネットワークは,シグモイド関数や動径基底関数といった非線形な基底関数の組合せからなる。分析者は,この関数族を選ぶ。
- パラメータ
を調整する
- データにフィットするように,パラメータの学習を行なう。
- パラメータ
を選ぶ
- これは,ニューラルネットワークにおける中間層の素子数などに相当するが,これを選択する。
第3章 ダイナミカルシステムの学習と予測
本節では,ダイナミカルシステムの予測を,ベイズ統計の枠組みとしてとらえて,ニューラルネットワークの学習(再構成)と予測を行なうための方法を説明している。
なお,非線形ダイナミカルにおける不確定性(システム雑音,初期値,観測雑音)のうち,システム雑音のみを対象とする(すなわち,初期値は観測可能で,状態量もそのまま観測できる,とする)。

3.1 モデル定式化
非線形ダイナミカルシステムを対象に行ないたいことは,過去の時系列データが与えられたときに,将来値
を予測することである。
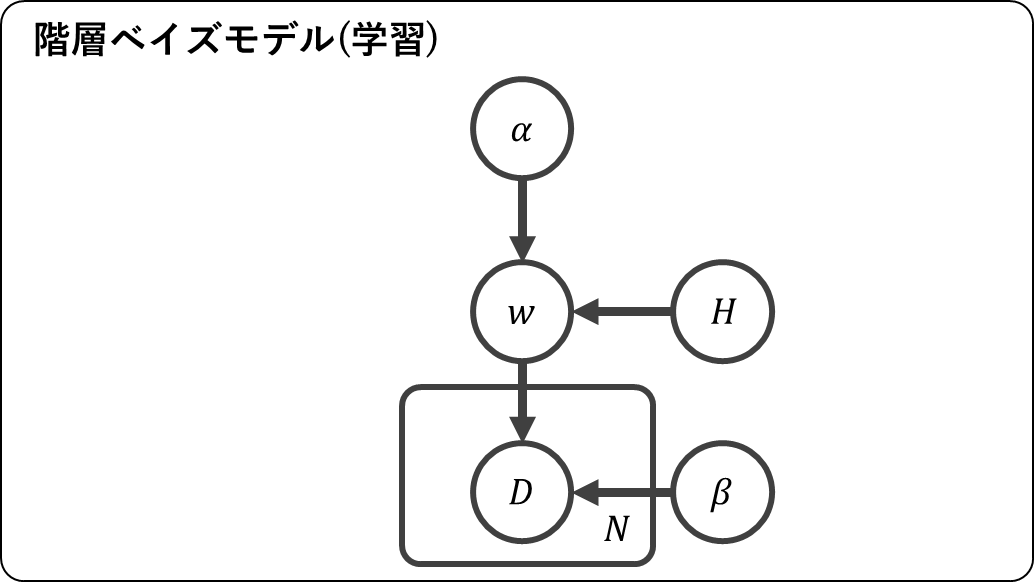
非線形ダイナミカルシステムを統計モデルに落とし込むと,下図のようになる。
この統計モデルの各要素の詳細を説明する。
(i)アーキテクチャ
ユーザが決めておくモデルの構成要素であり,
- ニューラルネットの基底関数
(シグモイド関数,動径基底関数など)
- 時系列モデルの時間遅れ
- ニューラルネットワークの隠れ層の素子数
などである。
なお機械学習の枠組みでは,これらの最適化はグリッドサーチで行なわれるが,本書ではモデル周辺尤度という概念を導入し,ベイジアンモデリングの枠組みで最適化を行なう。
(iii)事前分布など
階層ベイズモデルを扱うので,パラメータにも事前分布を設ける。パラメータ
を
個の部分ベクトルに分割し,
とし,各部分ベクトルパラメータが正規分布に従うと仮定する。
通常のベイズ線形回帰では,パラメータの事前分布に設けるパラメータは単一のものとしている(すなわち
)。
このように,の値に応じて事前分布のパラメータ
を変えることによって,予測に寄与しない
に対応する
は値が大きくなり,正規分布の分散が小さくなって,値が0に集中する。
すなわちスパース回帰と同様に,不要なパラメータが除去される効果が得られる(関連度自動決定(Automatic Relevance Determination; ARD))。
また,自体の事前分布や,尤度に出てくる精度
については無情報なので,一様分布またはガンマ分布を考える。
アーキテクチャに関する事前分布にも同様に一様分布を設定する。アーキテクチャに関する事前分布は,例えば
のように
の値を何パターンか用意しておき,それらについてデータの当てはめを行なうことを考えると,これらのモデルの選び方には差をつけずに選択をするので,一様分布になると考えられる。
3.3 予測アルゴリズム
パラメータの事後分布
上記のモデルにおいて,推定するべきパラメータは以下の5つである。
- 連続パラメータ
- ニューラルネットワークのパラメータ
- 事前分布のパラメータ
- システムノイズの精度
- ニューラルネットワークのパラメータ
- 離散パラメータ (まとめて
と表現する)
- 時系列モデルの時間遅れ(マルコフ過程の次数)
- ニューラルネットワークの中間素子数
- 時系列モデルの時間遅れ(マルコフ過程の次数)
事後分布は,ベイズ公式から以下のように得られる(グラフィカルモデルも参照のこと).
事後確率最大化によるパラメータ推定
連続パラメータは,事後確率最大化によって求める。このように求められたMAP推定量を
と表現する。
モデル周辺尤度によるハイパーパラメータの選択
離散パラメータなどをまとめて
と表現する。
も事後確率最大化によって求める,というのが本書の特徴の1つである。
であるので,
となる。
ここで,
であり,これはモデルに関する周辺尤度とみなせる。
実際は,この積分計算をするのが大変である。そこで,の分布がそれぞれ
に集中していると仮定すると,もはや
は分布ではなく定数
とみなせるようになり,積分が外れる。また
は一様分布であると仮定しているので,
のように近似することができる。
予測分布
新たなデータが得られた時の予測分布
は,以下のようになる。
ややこしく見えるが,よくある予測分布の導出であり,パラメータを復活させて,離散パラメータは総和をとることで,連続パラメータは積分することで消去している。
グラフィカルモデルは,以下のようになる。

第4章 具体的問題
本節では,第3章までに定式化した予測手法を,以下の具体的問題に適用している。
- ノイズを含むカオス的時系列予測(エノン系・レスラー系)
- 空調負荷予測
空調負荷予測については,空気調和・衛生工学会により実施された「熱負荷予測コンテスト」のデータを用いている。データセットは見つけられなかったが,コンテストの結果は以下に紹介されているものと考えられる。
本書に関するまとめと感想
モデル選択も含めて階層ベイズモデルの枠組みで行なっていることが参考になった
本書は「階層ベイズモデル」がテーマであるが,非線形ダイナミカルシステム(非線形時系列モデル)をベイズ統計の枠組みで説明しきっている点が面白かった。
また事後分布についても,第3章では近似を用いて評価している点も参考になった。最近では,ベイジアンモデリングのソフトウェアが充実しているので,モデリングさえしっかりすれば実装はできるのであろうが,理論的な解析をしようとしたときにこのような近似は役立つのでは,と感じている。
実装にチャレンジしたい
今回のテーマは,ニューラルネットワークモデルに予測分布を与えるという内容である。これまで学んだ書籍は,基本的に線形モデルが多かったので,ベイズ統計と深層学習の融合分野やその実装については,須山敦志 著「ベイズ深層学習」などを参考にしたい。
また実装についても,森賀新/木田悠歩/須山敦志 著「Pythonではじめるベイズ機械学習入門」などを参考にしていきたい。
本記事を最後まで読んでくださり,どうもありがとうございました。
*1:ただし,実際はヘッセ行列が出てくるので,パラメータの次元数が大きくなりすぎると計算量は大きくなる