はじめに
藤原 幸一 著「スモールデータ解析と機械学習」は,サンプル数が少ない状況でのモデル構築や予測精度の確保,統計的な不確実性の扱い方など,現場で直面する悩みに直結する理論と実践がコンパクトにまとまっている。製造業のデータ解析において「少ないデータだから仕方ない」と諦めるのではなく,「少ないからこそできる工夫」を身につけるためにこの本を読み,その学びをブログで共有しようと思う。
本記事は,「第2章 相関関係と主成分分析」の読書メモである。
第2章 相関関係と主成分分析
相関関係は2変数間の関係をあらわすものであり,本書を通じて重要な概念である。主成分分析は,サンプル数に比べて測定変数が多いときに次元削減を行なうための手法である。
本章では,2変数間の関係である相関係数の説明から始まり,多変数間の関係を分析する主成分分析の説明を行なっている。
2.3 相関関係≠因果関係
相関関係と類似した言葉として,因果関係が挙げられる。これらの違いは以下の通りである。
- 相関関係 : 単に変数間の線形性という意味である
- 因果関係 : 2つの出来事が原因と結果という関係である
因果関係について,少なくとも以下の3つの条件が成立しないと,イベントがイベント
の原因であるとは言えない。
は
に先行して発生しなければならない
スモールデータの場合,入手できたデータには偏りがあると考えるのが無難である。また偏っているため,相関があるように見えてもそれは擬似相関である可能性もある。
そのため,データの背後に存在するメカニズムを考察することが重要である。
2.5 主成分分析(PCA)とは
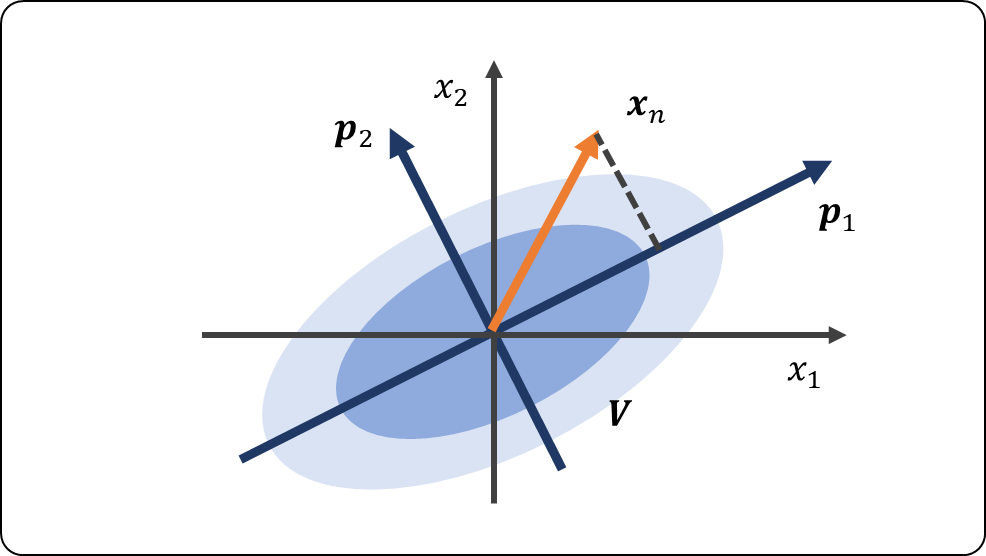
主成分分析は,多変数の間の相関関係を抽出する方法である。主成分分析は,データの特徴(データの分散)をもっともよく表現するように新しく直交する軸を取り出す。
この「データの特徴(データの分散)をもっともよく表現するように新しく直交する軸を取り出す」ということについて,数式で考える。
まず回目の測定で得られたサンプルを
とし,
個分のサンプルを縦に並べたデータの行列を
とする。ただしこのデータは,平均が0になるように中心化されているとする。
サンプルをある軸
に射影したものは,
となる。これをデータ行列全体に適用すると,
このベクトル
この分散を最大化するようにを求めればよいが,
のノルムを大きくすればいくらでも分散は大きくなるので,
という制約を加える。
最終的に第1主成分を求めるための最大化問題は,
制約付き最大化問題なので,ラグランジュ乗数を導入してラグランジュの未定乗数法を用いると,
第1主成分の導出の流れを整理すると以下のようになる。
- データ
について,共分散行列
を計算する
- 共分散行列
- 最大固有値に対応する固有ベクトルを第1主成分とする
なおこの主成分を表すベクトルを,特にローディングベクトルと表現する。
主成分分析は第1主成分から求めることになるが,第2主成分以降は2番目に大きい固有値に対応する固有ベクトルをローディングベクトルとすればよい。
2.12 PCAと特異値分解
行列を特異値分解すると,
行列に主成分分析を適用し,上位
個の固有値に対応する固有ベクトルを並べた行列
と,行列
に特異値分解を適用し,上位
個の特異値に対応する右特異ベクトルを並べた行列
の間には,
という関係がある。
まとめと感想
今回は,「第2章 相関関係と主成分分析」についてまとめた。
主成分分析は異常検知などでも利用できるため,製造業におけるデータ分析で最もよく使われる分析手法の1つだろう。導出の際には,制約付き最適化問題や固有値問題が出てくるので,数理的な知識に関する良い復習問題になる。
製造業の現場データは,サンプル数が少ないのに測定項目が多い「典型的なスモールデータ構造」になりやすい。本章で説明されている「相関と因果の混同を避ける姿勢」と「次元削減による特徴抽出」は,まさにそうした現場で有効な考え方だと感じた。
例えば品質管理における不良解析では,外観検査や寸法測定など多数の変数が絡み合い,どれが本質的な要因かが分かりにくい。このときPCAを用いることで,本質的な変動要因(共通因子)を数軸に圧縮し,因果解析や工程改善の糸口をつかみやすくなる。また特異値分解との関係を理解しておくことで,PythonやRなどのライブラリ実装を裏付けを持って使えるのも大きな利点だ。
一方で,PCAはあくまで「分散をよく表す軸」を見つける手法であり,必ずしも因果的な重要度を保証しない。本章の「データ背後のメカニズムを考える」という指摘は,単なる統計処理に終わらせず,現場知識と組み合わせる重要性を改めて示していると考えられる。
本記事を最後まで読んでくださり,どうもありがとうございました。
*1:本書ではこのように紹介されているが,正確には,「左特異ベクトルからなる直交行列」といった表現が妥当だと考えられる。