はじめに
Pythonによるベイズモデルの実装をきちんと学ぼうと思い,森賀新・木田悠歩・須山敦志 著 「Pythonではじめるベイズ機械学習入門」を読むことにした。
本記事は,第4章「潜在変数モデル」のうち隠れマルコフモデルに関する読書メモである。
- 本書の紹介ページ
4.4 隠れマルコフモデル
隠れマルコフモデル(Hidden Markov Model)は,時系列データのモデリングに用いられる潜在変数モデルである。
状態空間モデルとの違いは,状態空間モデルでは潜在変数が連続変数であったが,隠れマルコフモデルは離散変数の場合に相当する。
4.4.1 モデル概要
本節では,隠れマルコフモデルのデータ生成過程について説明している。
潜在変数には1次マルコフ性,すなわち,時点
の値は時点
の値にのみ依存して決まる,という性質があるとする。
潜在変数の推移の確率を表すものが,遷移確率行列(Transition Probability Matrix) である。潜在変数
が取りうる値が
通りあれば,
は
の行列であり,
となる。例えば以下の例では,
となる。
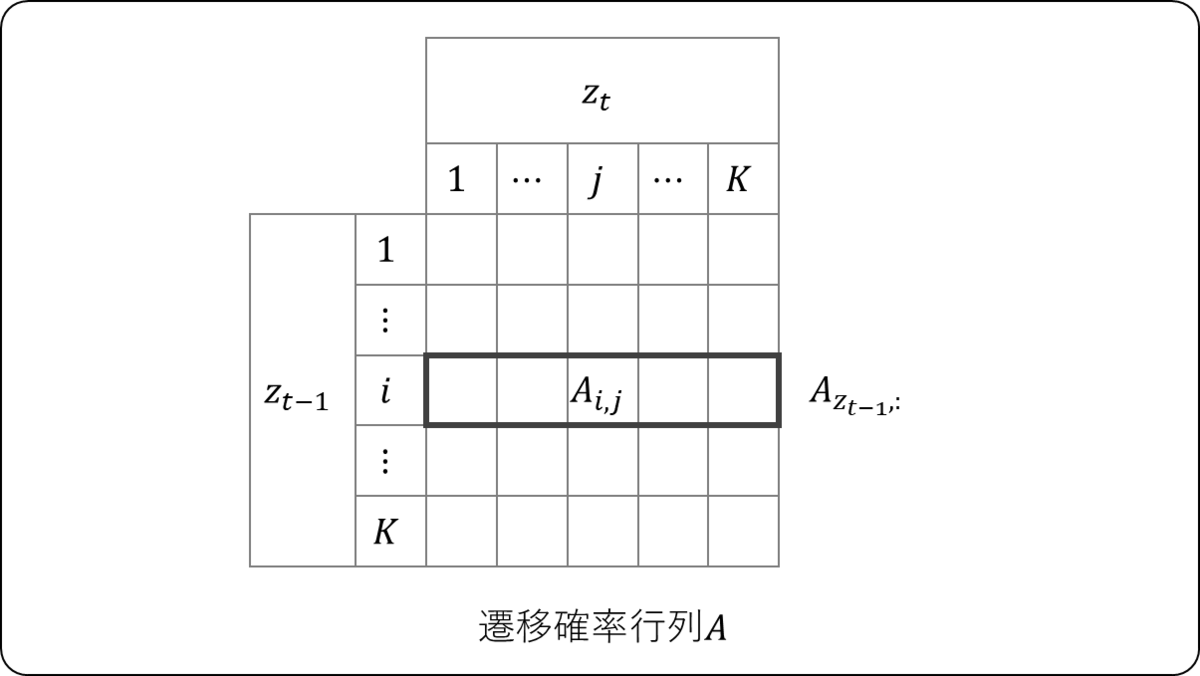
この遷移確率は,カテゴリ分布に従う。
なおは,行列
の
(
)行目を表している。これは各要素が0以上かつよその和が1の実数値ベクトルなので,事前分布はディリクレ分布を設定する。
また最初の時点の潜在変数は初期確率
に従うとする。
の事前分布もディリクレ分布とする。
続いて,潜在変数が与えられた下で,観測データを生成する観測分布を定義する。今回の問題設定では,観測分布はポアソン分布とする。
ポアソン分布のパラメータは正の実数値なので,今回は事前分布としてガンマ分布を設定する。
グラフィカルモデルは下図のようになる。
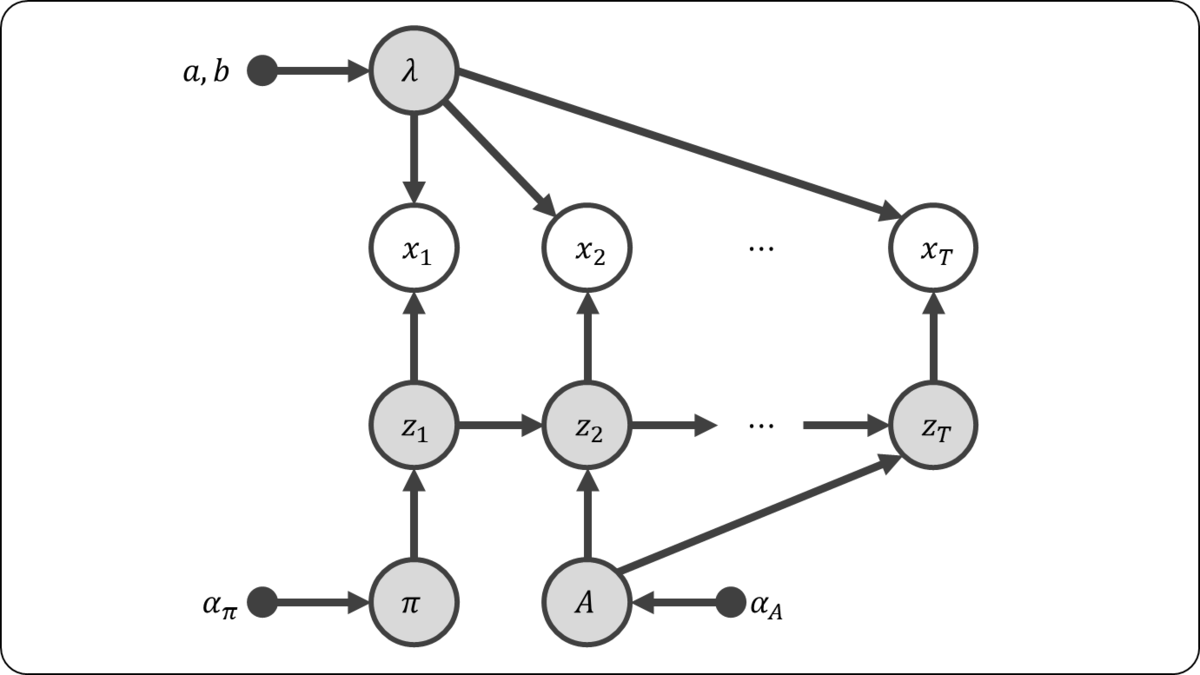
モデルの式は以下のようになる。
- 尤度関数
- 事前分布
今回の問題設定における推論対象は,潜在変数,パラメータ
である。
そのために事後分布を求めることになるが,C.M. ビショップ 著 「パターン認識と機械学習 下」を読むとそれなりにボリュームがあったので,本記事ではスキップする。
4.4.2 実装
サンプルコードを動かしながら,挙動を確認した。
github.com
パッケージのインポート
パッケージのインポートを試みた結果,エラーが生じた。サンプルコードでは,インポートするパッケージのバージョンを指定しているのだが,そのためGoogle Colab上の他のパッケージとの整合が取れなくなっていたようである。
そのため,ソースコードを以下のように修正した。
- コード(修正前)
#@title install packages !pip install japanize-matplotlib==1.1.3 !pip install arviz==0.11.4 !pip install tensorflow_probability==0.14.1 !pip install tensorflow==2.7.0 !pip install watermark
- コード(修正後)
#@title install packages
!pip install japanize-matplotlib
!pip install arviz
!pip install tensorflow_probability
!pip install tensorflow
!pip install watermark
なお,今回の試行において用いたパッケージのバージョンは以下の通りである。
- コード
%load_ext watermark %watermark --iversions
- 出力
numpy : 1.26.4 matplotlib : 3.8.0 seaborn : 0.13.2 arviz : 0.20.0 japanize_matplotlib : 1.1.3 tensorflow_probability: 0.24.0 tensorflow : 2.17.1
データの準備
用いるデータはシミュレーションデータである。問題設定として,スロットマシーンを考える。スロットマシーンの当たり回数が観測データ,その裏で変化しているスロットマシーンのモードが潜在変数である。
潜在変数が取りうる値(状態)は,
の3通りである。また,観測データはポアソン分布に従う。
当たり回数とモードの時系列グラフは下図のようになる。
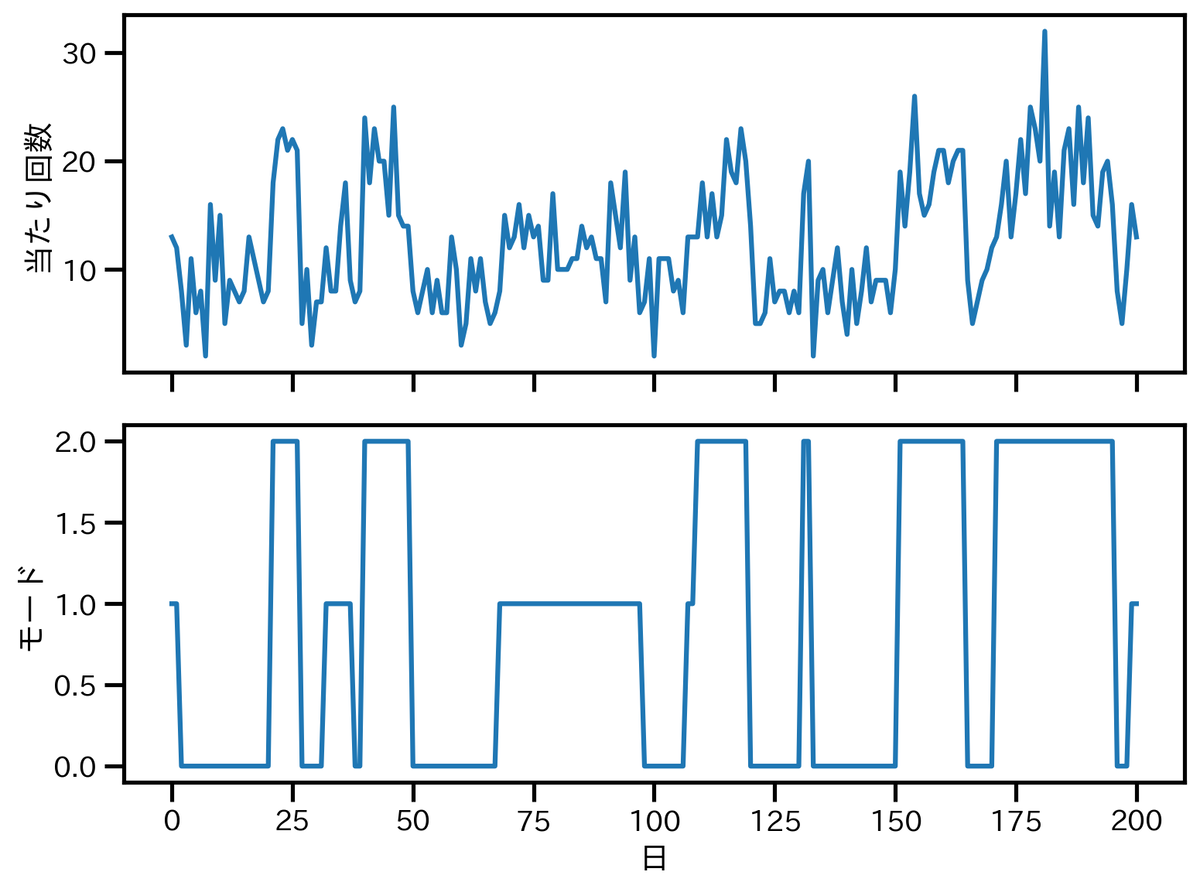
なお,パラメータの真値は以下の通りである。
サンプルコード中では,はinitial_probs,
はtransition_probs,
はrate とそれぞれ表記されている。
MCMCによる事後分布のサンプリング
今回の問題設定では,が離散変数である。そのため,潜在変数の取りうるパターンを列挙して足し合わせることで,潜在変数を消去する(周辺化)。
TFPのHiddenMarkovModelクラスでは,これを実装している。
推定したいパラメータをTensorFlow上で扱いやすくするために,bijectorと呼ばれる関数を用いて変換する。bijectorは,微分可能な1対1の関数を表す。
(initial_probs)および
(transition_probs)は,それぞれ
および
という制約があるので,ソフトマックス関数を使って変換する。
また(rate)には,正の値である,という制約があるので,ソフトプラス関数を用いる。

さらに,複数のチェーンでサンプリングを実行した場合,潜在変数の割り当てが入れ替わること(ラベルスイッチング)があるので,パラメータの3つの成分が昇順になるように制約を与える。
各パラメータの分布とトレースプロットは下図の通りである。
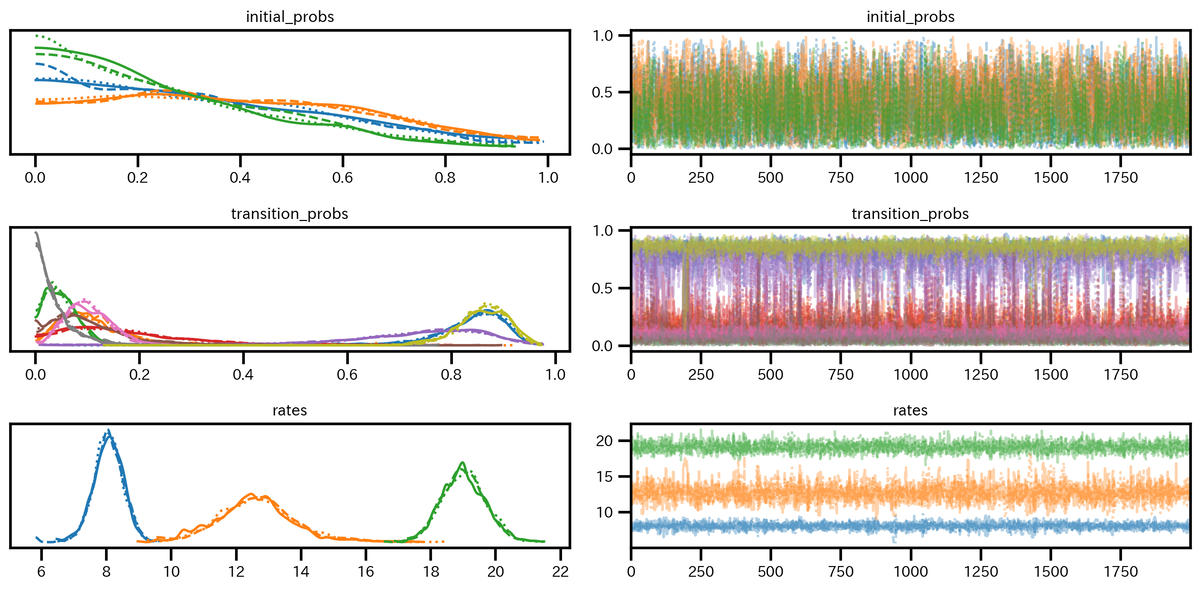
トレーズプロットはいずれのチェーンも安定した変動パターンであることが確認できた。
潜在変数の推論
MCMCサンプリングにあたり,潜在変数を周辺化して消去しているため,MCMCでは潜在変数を直接推論できなくなる。
ただし,HiddenMarkovModelクラスのposterior_marginals関数を用いると,全時点の観測値と各パラメータ(まとめてと記載)が与えられたもとでの潜在変数の事後分布
またHiddenMarkovModelクラスのposterior_mode関数を用いると,潜在変数の尤もらしい系列
を得ることができる。
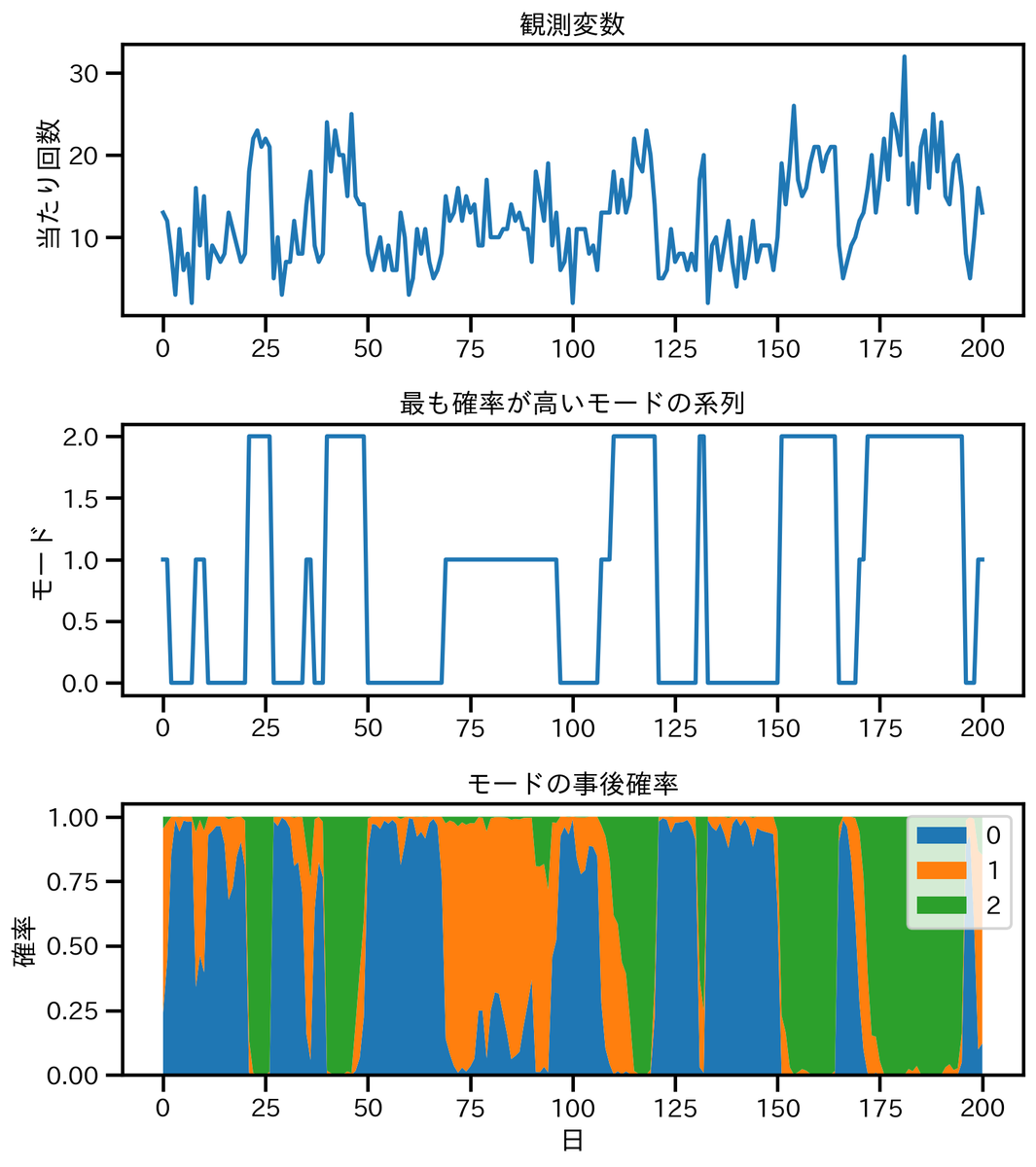
MCMCで求めた各パラメータの事後分布の平均を用いて隠れマルコフモデルを定義し,最も確率が高い潜在変数の系列と,各時点の潜在変数の事後分布の積み上げグラフを描くと下図のようになる。
まとめと感想
潜在変数モデルのうち,隠れマルコフモデルの実装方法について学んだ。
隠れマルコフモデルは,各時点において取りうる状態が複数あるので,数式上の表記は複雑であるが,コードで実装するとかなりシンプルになることが分かった。
またTensorFlowで実装するために,softmax関数やsoftplus関数を用いるテクニックも紹介されており,実践するうえで参考になると感じた。
製造業においても,機械システムのモードが変更していくことがある。モード変更に関する制御履歴が不明の場合でも,隠れマルコフモデルを用いることで推定できそうなので,実践する機会があれば今回の内容を参考にしたい。
本記事を最後まで読んでくださり,どうもありがとうございました。