はじめに
Pythonによるベイズモデルの実装をきちんと学ぼうと思い,森賀新・木田悠歩・須山敦志 著 「Pythonではじめるベイズ機械学習入門」を読むことにした。
本記事は,第4章「潜在変数モデル」のうち隠れトピックモデルに関する読書メモである。
- 本書の紹介ページ
4.5 トピックモデル
トピックモデル(Topic Model)は,テキストデータの潜在的な意味すなわちトピックの解析に用いられる。
4.5.1 モデル概要
トピックモデルでは,文書の生成過程の背後に,トピックと呼ばれる潜在変数が存在すると仮定する。
たとえば,トピックとして「スポーツ」「芸能」「政治」「文化」の4つのトピックがあるとする。1つの文書の背後には,複数のトピックが存在すると考える。
1つの文書における各トピックの割合をトピック比率(Topic Proportion)と呼ぶ。
トピックモデルには様々なモデルがあるが,本書では最も基本的なモデルの1つである潜在ディリクレ配分(Latent Dirichlet Allocation; LDA)について説明している。
以下では具体的なトピックモデルの確率モデルを考える。なお,文書の数を[tex; D],トピック数を,語彙数を
とする。なお「語彙」とは,すべての文書から取り出させれる単語の集合なので,「語彙数」とは文書全体に登場する単語の種類の数,と言える。
トピックと文書の関係
1つの文書は,複数のトピックを持ち,トピック比率を
と表す。
トピック比率の成分はかつ
を満たす。
このようなトピック比率を生成する確率分布として,ディリクレ分布が用いられる。
文章中の書く単語は種類のトピックのうち1つから生成されると考える。
文書における
番目の単語
がどのトピックから生成されたかを示すトピック割り当て(Topic Assignment)
を導入する。
このようなトピック割り当てを生成する確率分布として,カテゴリ分布が用いられる。
ただしは文書
を構成する単語の数である。
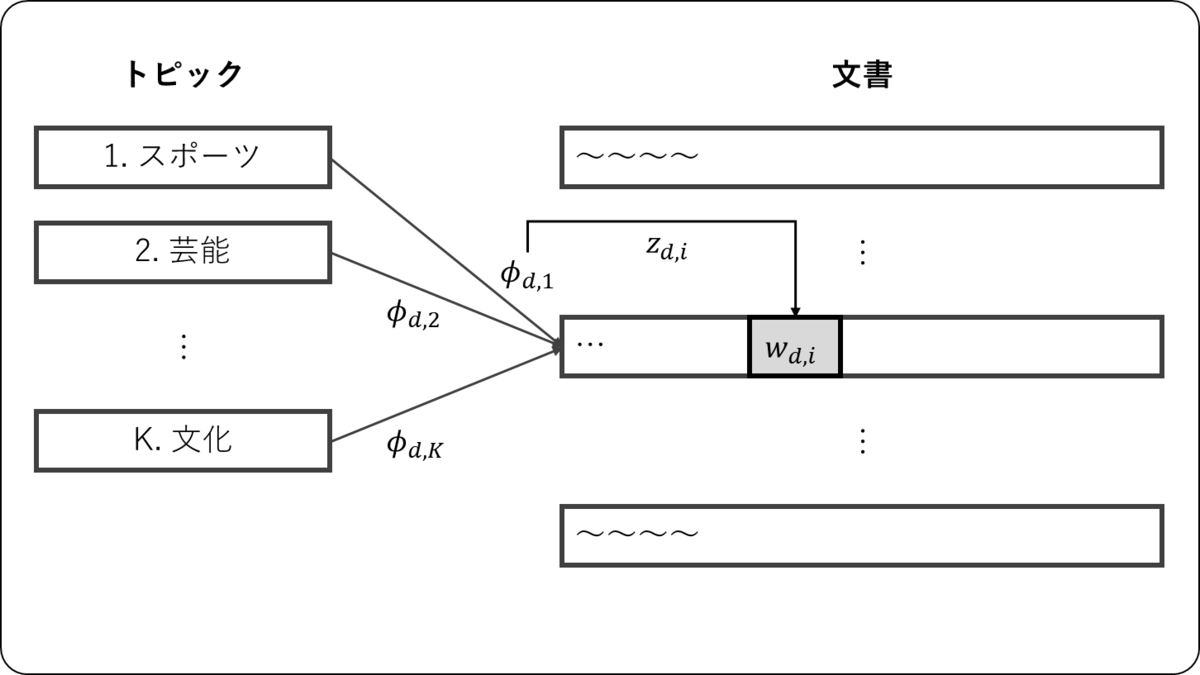
トピックと単語の関係
単語にはの番号が振られているものと仮定する。
番目の単語
が
で指定されたトピックから生成される。そのため,
と同じく
もカテゴリ分布から生成されると考えることができる。
LDAでは,単語の出現確率がトピックにより異なると仮定しており,トピックにおける単語の出現比率は
で表される。ただし,
かつ
を満たす。
またの事前分布は
と同じくディリクレ分布とする。
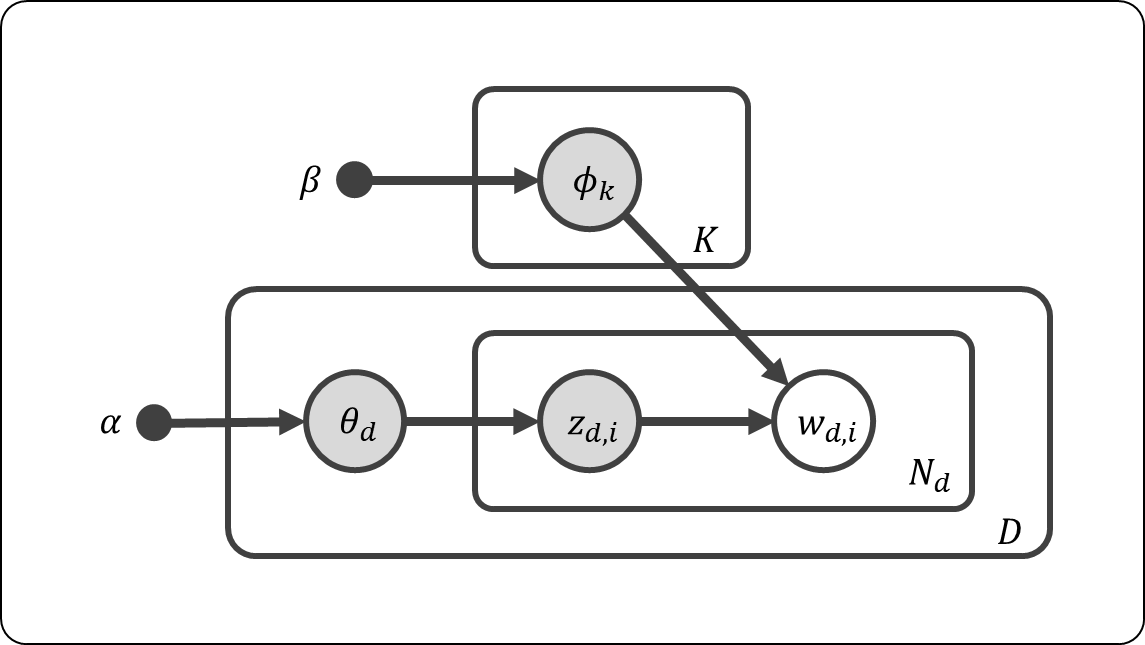
以上でモデルが定義できた。グラフィカルモデルで表すと,下図のようになる。
4.5.2 実装
サンプルコードを動かしながら,挙動を確認した。
github.com
データの準備
用いるデータは人工データである。実際のテキストデータを用いると,実際のテキストデータのトピックが不明なので,推論結果の評価が難しくなるためである。
モデル式に従って人工データを生成する。
- トピック数 : 4
- 語彙数 : 30
- 文書数 : 20
- 文書中の平均単語数 : 60
このようにして作成した1つ目の文書は以下のようになる。
- 出力
[27, 1, 11, 25, 15, 9, 11, 18, 11, 18, 17, 22, 7, 19, 1, 17, 29, 9, ...(※省略)]
このように,単語IDの数字で表されるので,この後の可視化では単語IDと単語を紐づける辞書を用いて,数字を単語の文字列に置き換えている。
各トピックにおける単語の出現確率は下図のようになる。トピックは順に「スポーツ」「政治」「エンタメ」「テクノロジー」といったように解釈される。
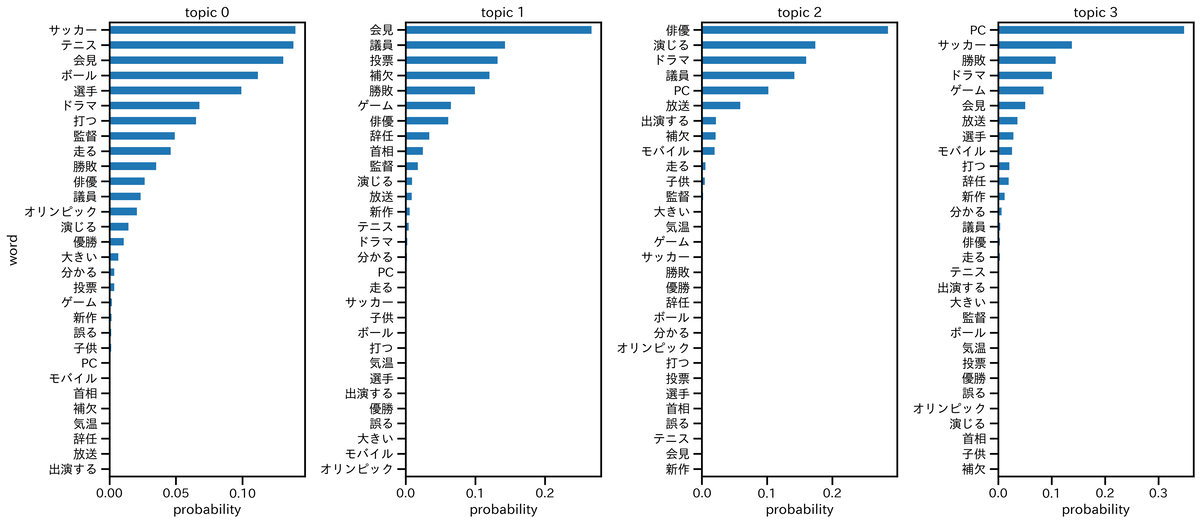
なお,topic0~topic3に現れる30個の単語はすべて同じである。ただしトピックによって,単語の出現確率が異なっている。
MCMCによる事後分布のサンプリング
今回はTFPを用いてLDAを実装し,HMCにより推論を行なう。LDAには離散の潜在変数が含まれるので,第4.4節と同様に潜在変数を周辺化して推論を行なう。
バーンインの期間は500,サンプルサイズは1000である。
単語の出現確率について,MCMCの推論結果とパラメータの真値を比較する。ただし,今回の問題設定ではトピックの順番に必然性がないため,トピックが正しく推論出来ていてもトピックの順番が一緒とは限らない。
そのため,真のパラメータと推論結果のユークリッド距離を算出し,ユークリッド距離が近い(小さい)トピック同士を対応付けることとする。
真のパラメータはは,データの生成過程で算出している。
推論結果については,コードでは以下のように得ている。
np.mean(phi.numpy(), axis=0)
サンプルが1000サンプル得られているので,推論結果の配列の形状は(1000, 4, 30),すなわち(サンプル数, トピック数, 語彙数)となっている。そのためサンプルについて平均を取り,(トピック数, 語彙数)という形状を持つ配列に変換する。
トピック間の距離の行列は下図のようになる。
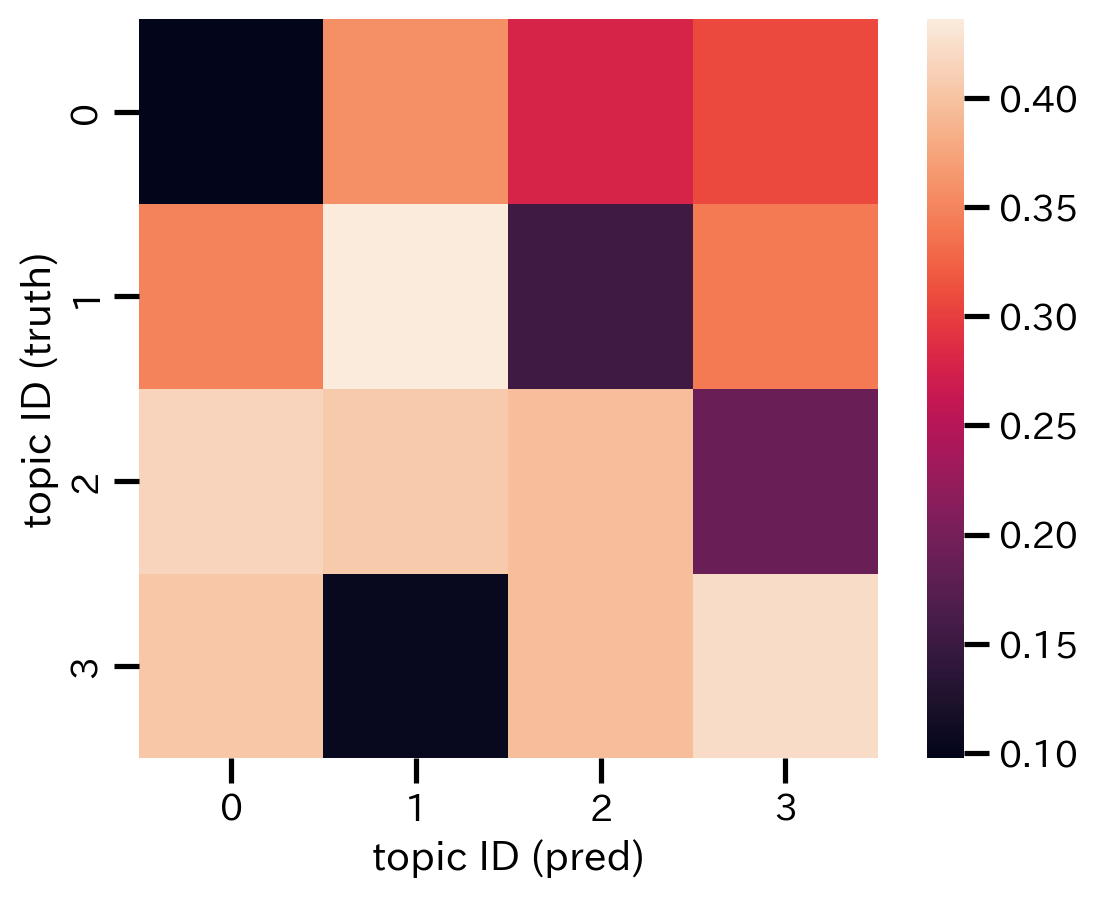
トピック間の距離に応じて並べ替えをした結果が下図のようになる。
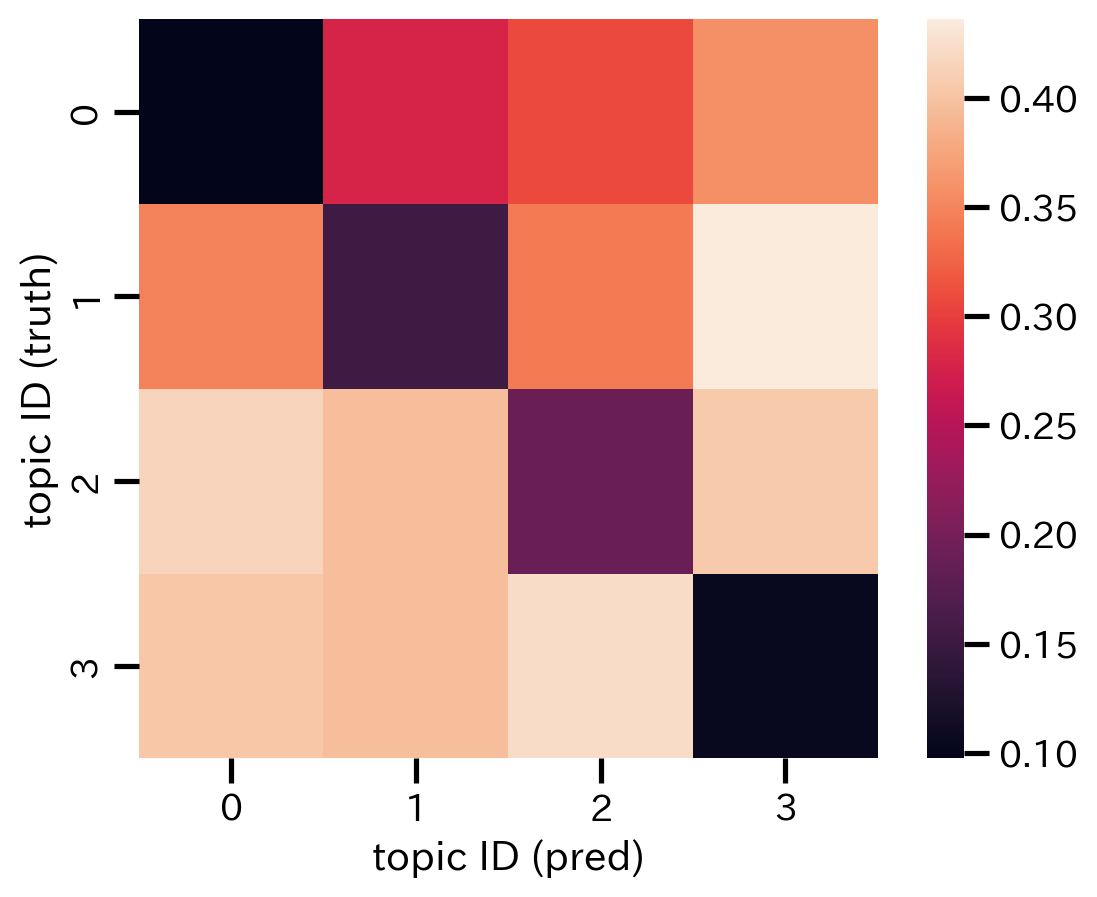
なお,相関行列と異なり,距離の近さ(小ささ)に応じて並べ替えているので,対角成分の値が小さくなっていることに注意する。
並べ替えを行なったうえで,トピックごとの単語の分布について,推論結果(青い■)と真値(オレンジの×)を可視化したものが下図である。

推論結果(青い■)と真値(オレンジの×)の位置が概ね一致していることが確認できる。
次に,文章ごと(文書0~文書19)のトピック比率を可視化したものが下図である。
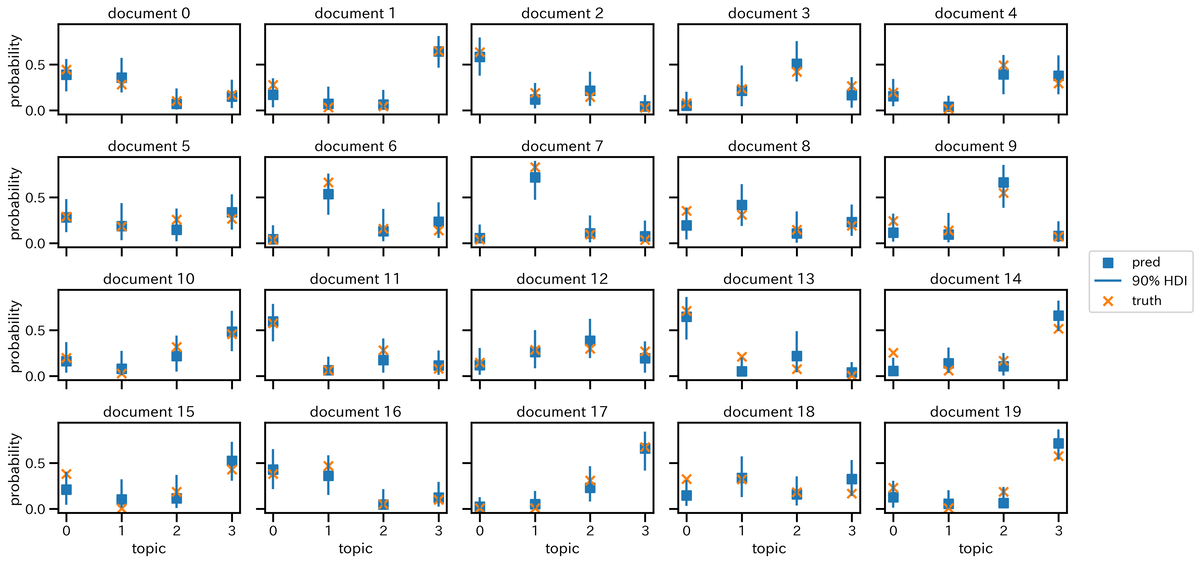
こちらも,推論結果(青い■)と真値(オレンジの×)の位置が概ね一致していることが確認できる。
なお,実際のテキストデータは語彙数・文書数ともに大きくなるので,MCMCよりも高速に推論ができる変分推論法などが用いられる。
まとめと感想
潜在変数モデルのうち,トピックモデルの実装方法について学んだ。
文書をグループに分けようとしたとき,クラスタリングを使うことができるが,LDAは「1つの文書に複数のトピックが存在している」ということを表現できるモデルであるため,実際のテキスト分類をするうえでも実用性が高いと感じた。
今回は小規模な人工データを扱ったが,語彙数・文書数ともに大きくなる実際のテキストデータにも適用してみたいと感じた。
本記事を最後まで読んでくださり,どうもありがとうございました。