はじめに
Pythonによるベイズモデルの実装をきちんと学ぼうと思い,森賀新・木田悠歩・須山敦志 著 「Pythonではじめるベイズ機械学習入門」を読むことにした。
本記事は,第2章「確率的プログラミング言語(PPL)」のうちPyroに関する読書メモである。
- 本書の紹介ページ
2.4 Pyroの概要
Pyro はUber AIにより開発されたPPLである。特徴は以下の通りである。
- 深層学習とベイジアンモデリングの長所を統合している。
- 推論計算方法には,HMC法を改善したNUTSを含む,いくつかの一般的な確率論的推論アルゴリズムが実装されている。
- 特に,勾配に基づく確率的変分推論法(Stochastic Variational Inference Method; SVI)が実装されている。
Pyroによるモデリング
Pyroによるモデリングは以下のサンプルコードを参照した。
github.com
事前分布はなので,これは一様分布と同じになる。
近似推論は,変分推論法を用いる。パラメータの定義域が
なので,近似分布にはベータ分布
を用いている。
なお,事前分布がベータ分布で,尤度関数がベルヌーイ分布の積,すなわち二項分布
のとき,事後分布はベータ分布
となる。
よって,今回の問題設定における真の事後分布はを代入して
となる。
サンプルコードを実行した後に,推定された事後分布のパラメータを出力した。
- コード
print('variational posterior alpha: {:.3f}'.format(alpha_q)) print('variational posterior beta: {:.3f}'.format(beta_q))
- 出力
variational posterior alpha: 6.048 variational posterior beta: 4.367
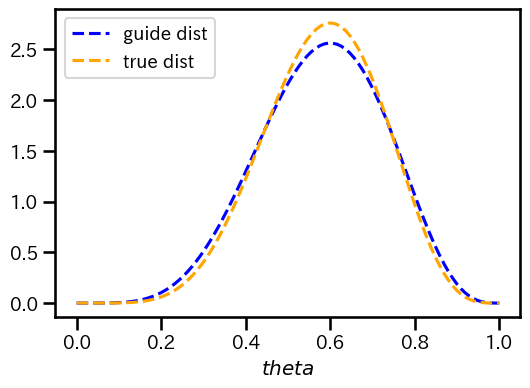
この結果から,と推定されており,真のパラメータである
からは若干ずれているようにも考えられる。
なお,真の事後分布と近似分布の事後分布における平均と標準偏差を比較すると以下のようになる。
- コード
# 近似分布の平均と標準偏差 alpha_q = pyro.param('alpha_q').detach().numpy() beta_q = pyro.param('beta_q').detach().numpy() variational_posterior = stats.beta(alpha_q, beta_q) print('variational posterior mean: {:.3f}'.format(variational_posterior.mean())) print('variational posterior std: {:.3f}'.format(variational_posterior.std())) # 真の事後分布の平均と標準偏差 alpha_t = 1 + torch.sum(y) beta_t = 1 + 10 - torch.sum(y) true_posterior = stats.beta(alpha_t, beta_t) print('true posterior mean: {:.3f}'.format(true_posterior.mean())) print('true posterior std: {:.3f}'.format(true_posterior.std()))
- 出力
variational posterior mean: 0.581 variational posterior std: 0.146 true posterior mean: 0.583 true posterior std: 0.137
事後分布の平均は,となるので,推論結果の平均値(variational posterior mean)=0.581は比較的良い精度で推定されていることが分かる。
真の事後分布と近似分布の概形は以下のようになる。
まとめと感想
PyMCのサンプルコードを扱ったときは,MCMCを用いた。今回Pyroを扱い,近似推論法として変分推論法を用いた。MCMCが上手く扱えない場合(たとえば計算時間がかかりすぎる場合など)においては変分推論法が有用であることもあると考えられるので,変分推論法のサンプルコードに触れられたのは参考になった。
推定された事後分布のパラメータはと推定されており,真のパラメータである
からは若干ずれていた。一方で,真の事後分布の平均・分散と,近似分布の平均・分散はかなり近しい値であった。
この理由を理解するには,ELBOの手順や損失関数などを詳細に確認する必要があると考えられる。
本記事を最後まで読んでくださり,どうもありがとうございました。