「確率的機械学習 入門編II」読書メモ一覧 - jiku log
はじめに
持橋大地・鈴木大慈 監訳「確率的機械学習 入門編II」は,世界的に評価の高いK.P.Murphy著 "Probabilistic Machine Learning (Book1)" の和訳であり,確率モデルに基づく機械学習,深層学習といった基礎が丁寧に整理されている。
本記事は,「第18章 木,森,バギング,ブースティング」における,ブースティングに関する読書メモである。
18.5 ブースティング
木のアンサンブルは,
ブースティング(boosting)は,逐次的に加法的モデルをフィットさせる手法である。
それぞれのモデルが二値分類器であるとして,
を学習データにフィットさせる。
は,重み付きデータにフィットさせる。
- このような手続きを
回繰り返す。
という手順で行なう。
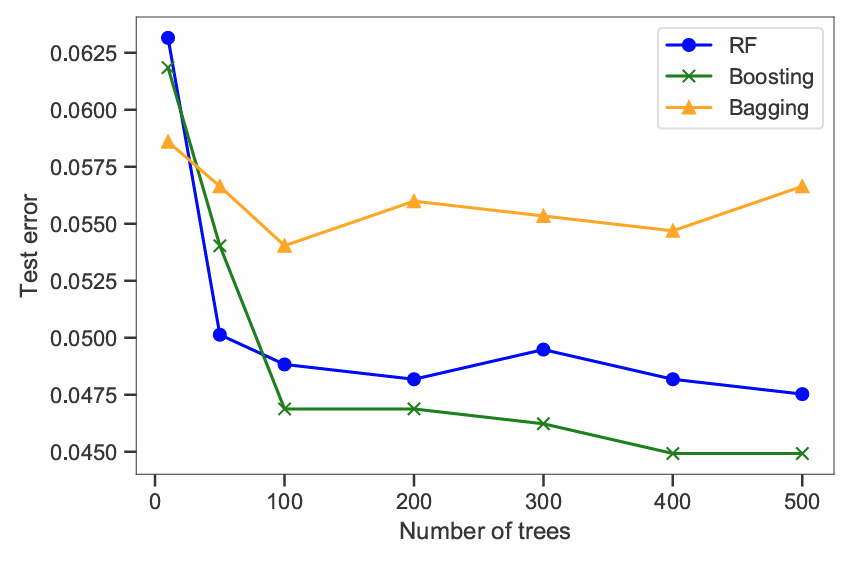
下図に,スパム電子メールデータセットの分類問題の例を示す。
横軸は用いた木の本数,縦軸はテストデータの予測誤差である。手法は,バギング・ランダムフォレスト・ブースティングを使用している。
これらの手法のうち,ブースティングが最もテスト誤差が小さい。
18.5.1 段階的加法モデル
本項では,段階的加法モデル(forward stagewise additive model)を導入する。
これは段目において,
このとき損失は,1つ前で得られた分類器
また,は以下のように定める。
18.5.2 二乗損失と最小二乗ブースティング
本項では,回帰問題の損失で与えられる損失について考える。
データに対応する
段目の損失関数は次の通りとなる。
この方法は,最小二乗ブースティングと呼ばれる。
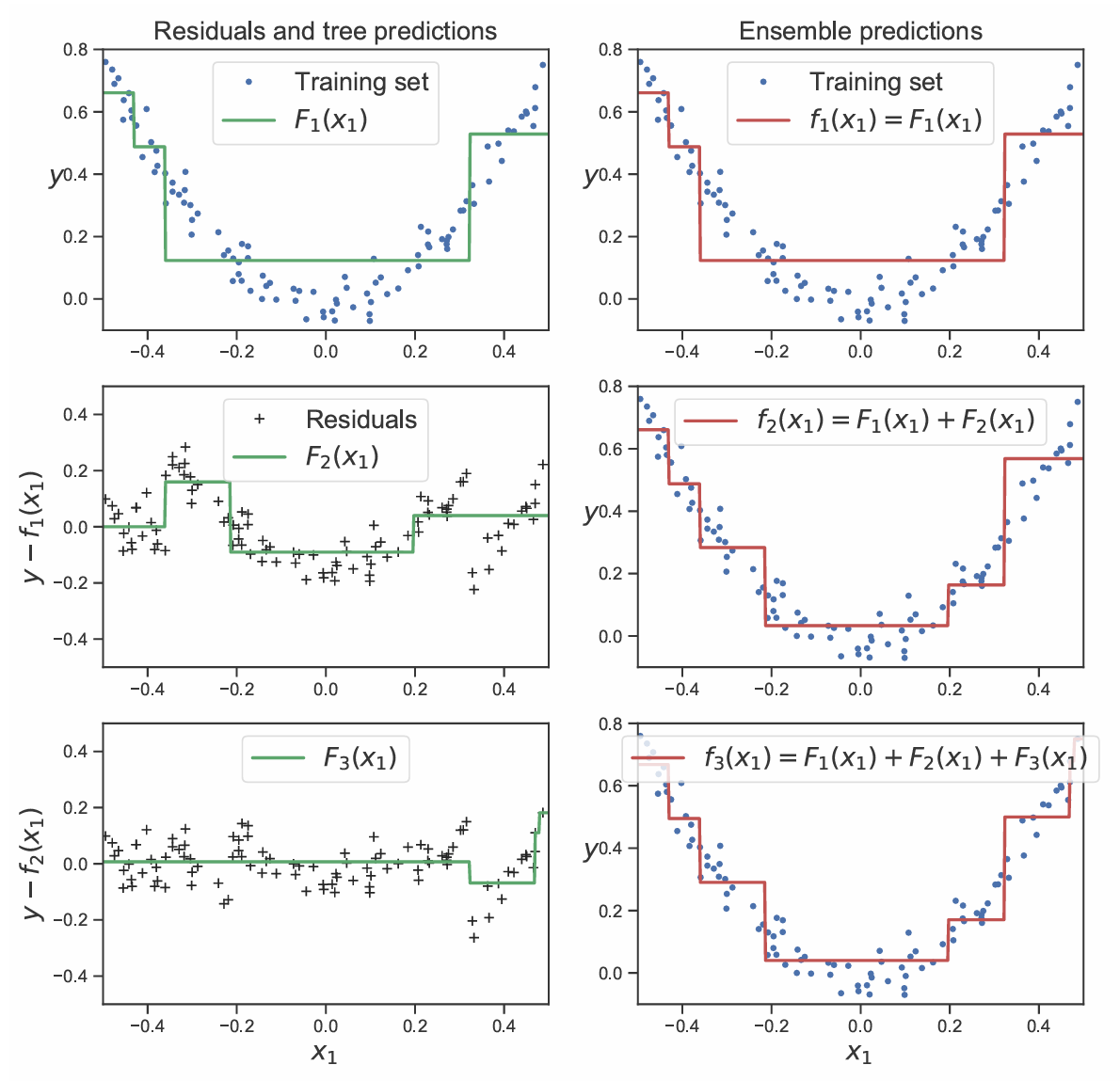
下図に,ブースティングによる回帰を行なった例を示す。左側が残差,右側が予測結果を示す。
図に示すように,残差が徐々に低減されて言っていることが分かる。
18.5.3 指数損失とアダブースト
二値分類,すなわちの予測を行なうことを考える。
指数損失
弱学習器は,以下の予測の計算を行なうとする。
この式より,負の対数尤度は以下のようになる。
また,別の損失として,指数損失を考えることもできる。
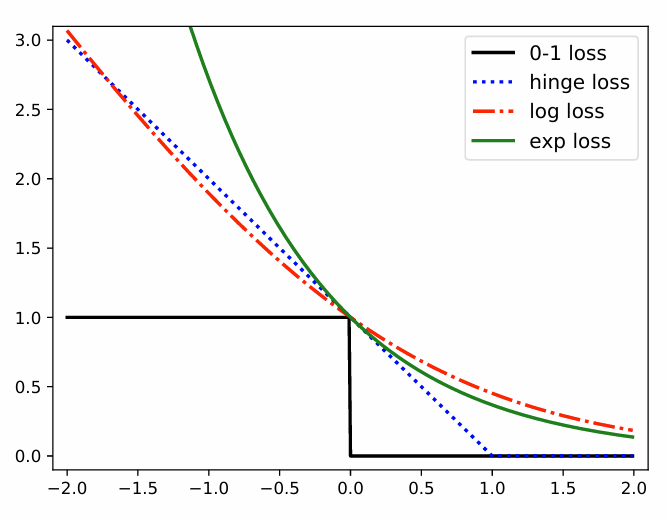
対数損失・指数損失を含む各種損失を下図に示す。縦軸は損失の大きさ,横軸はマージンである。
対数損失も指数損失も,既に正しく分類できている領域(マージンが正の領域)は損失が小さいことがわかる。
ブースティングにおいては,指数損失の方が最適化しやすい。
アダブースト
指数損失を使った場合,二値分類のラベルを返すアルゴリズムは離散アダブースト,確率値を返すようなアルゴリズムは実数アダブーストと呼ばれる。
実数アダブーストにおける損失関数は以下のようになる。
また誤分類されたデータの重みは,指数的に大きくなる。
二値分類向けのアルゴリズムはアダブーストM1(Adaboost.M1)と呼ばれ,以下のようなアルゴリズムになる。

なお,多値分類に拡張したアルゴリズムは,SAMMEと呼ばれている。
18.5.4 ロジットブースト
指数損失を用いる場合,誤分類された学習データに大きな重みを与える。そのため,誤ってラベル付けされた外れ値には非常に敏感になる。
そのため,指数損失ではなく対数損失を用いる方法が提案されており,この手法はロジットブーストと呼ばれる。
ロジットブーストにおける損失は,以下のようになる。
まとめと感想
今回は,「第18章 木,森,バギング,ブースティング」における,ブースティングについてまとめた。
ブースティングは,単に弱学習器の多数決を取るのではなく,誤ったところを重点的に改善していくという点が,なかなか興味深かった。
人間の場合でも,資格試験の勉強をしているときに,誤った箇所を重点的に復習するため,とても理にかなった考え方だと感じた。
またアダブーストの場合,指数損失を用いているというのが特徴的だった。外れ値に対して敏感になるという弱点があるにせよ,計算が楽になるというのは実装上のメリットである。
損失関数についても,問題に応じて適切なものを選べるようにしたい。
本記事を最後まで読んでくださり,どうもありがとうございました。
参考サイト
- 確率的機械学習:入門編 II |朝倉書店
- 『確率的機械学習:入門編』サポートサイト
- 原著関連
- Probabilistic Machine Learning: An Introduction : 原著のサポートページ
- pyprobml/notebooks.md at auto_notebooks_md · probml/pyprobml · GitHub : 原著の図作成用Notebooks一覧