はじめに
東京大学教養学部統計学教室編「自然科学の統計学」は,1992年発行のやや古典的な文献であるが,自然科学に関わる統計学的テーマが簡潔にまとめられている。数理統計学の復習も兼ねて,本書を読むこととした。
ただ,基本的なことは他書で学んできたのと,本書自体がかなり細かく説明されているので,本書内の内容や数式を細かく追うというより,実務や統計検定の受験において有用そうなことを選んでまとめてみたい。
本記事は,「第4章 最尤法」における,最尤推定量の最適性に関する読書メモである。
4.4 最尤推定量の最適性
本節では,最尤推定量が持つ各種性質について紹介している。この性質は,以下の3つである。
- 一致性 : 最尤推定量は(正則条件の下で)真の値
に確率収束する。
- 漸近有効性 : 最尤推定量の分散は,
が大きいときに有効である(クラメール・ラオの下限に等しくなる)。
- 漸近正規性 : 最尤推定量がしたがう漸近分布は,正規分布にしたがう。
本記事では特に,漸近有効性・漸近正規性について説明する。
漸近分布の導出
一致性より,が大きいときに,最尤推定量
は真の値
に近づく。次に興味があるのは,
- 真の値の周りでのばらつきを知りたい。
- 区間推定・検定の問題を考える際に,期待値・分散だけでなく標本分布を知りたい。
ということである。
分散や標本分布について,順を追って説明する。
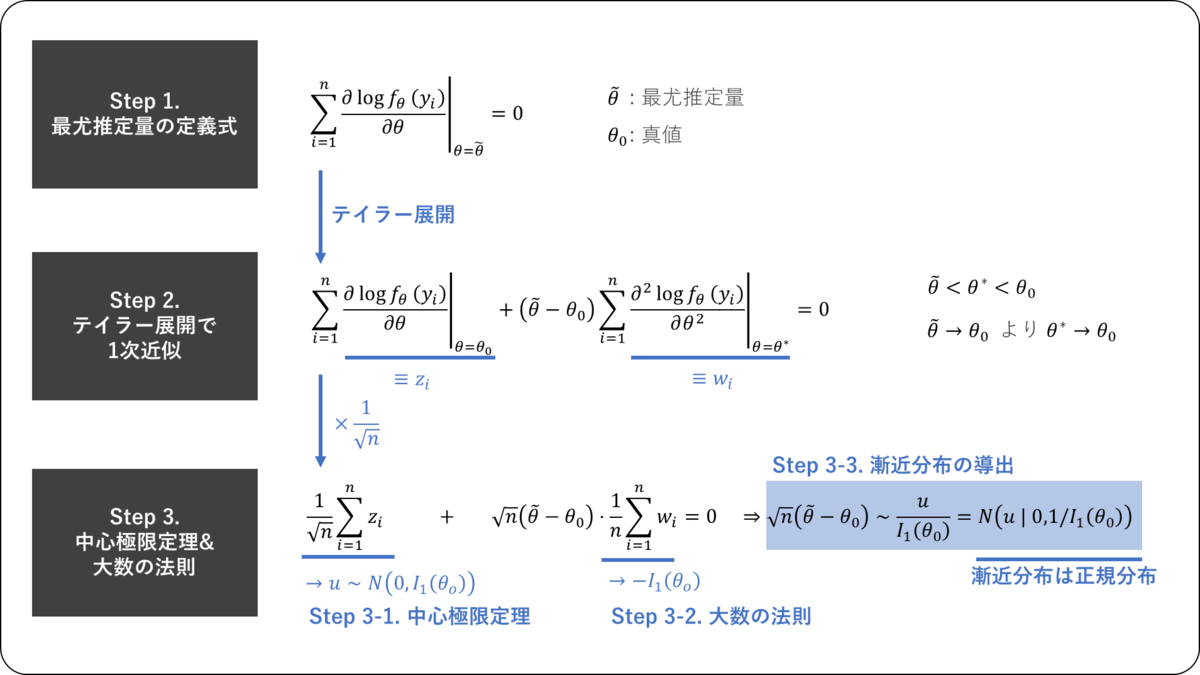
Step 2. テイラー展開で1次近似
尤度方程式の左辺をの関数とみなし,これを
の周りでテイラー展開すると,
を大きくすると,
(最尤推定量)は
(真値)に一致するので,
も
に一致する。
Step 3. 中心極限定理&大数の法則
が大きくなったときに,対数尤度の1階微分・2階微分の漸近的な性質を調べる。そのために,以下の
を導入する。
次に,後々の解析のために,Step 2. の式をで割る。
Step 3-1. 中心極限定理の利用(対数尤度の1階微分の解析)
対数尤度の1階微分の解析を行なうために,中心極限定理を用いる。
中心極限定理は,確率変数が互いに独立かつ同一の確率分布に従う確率変数列で,
のとき,
中心極限定理を書き換えると,
は対数尤度の1階微分であるため,
これらと中心極限定理を用いると,のとき,
まとめと感想
今回は,「第4章 最尤法」における,最尤推定量の最適性についてまとめた。
漸近正規性の導出は,尤度方程式のテイラー展開を起点に,中心極限定理と大数の法則を組み合わせて,最尤推定量の極限分布を得る流れとなっている。この過程をステップごとに追うことで,最尤推定量がなぜ「漸近的に正規分布に従うのか」が論理的に理解できる。そしてその分散がフィッシャー情報量の逆数となり,クラメール・ラオの下限を達成することで「漸近有効性」が保証される。
ここで重要なのは、最尤推定が「ただ便利な推定方法」なのではなく,数学的に最適性を備えた推定量である,という位置づけである。サンプルサイズが有限のときには必ずしも最適ではないが,大標本の極限においては一貫して信頼できる性質をもつ点が,理論・実務の両面で強力な裏付けとなる。
統計検定1級対策としては,この「漸近正規性」と「漸近有効性」を論証するための典型的な流れ(テイラー展開 → 中心極限定理 → 大数の法則 → フィッシャー情報量の導入)を理解しておくことが非常に重要である。特に,で割ることで中心極限定理を使えるようにする,といったテクニックは,他の漸近分布を考えるうえでも有用であろう。
本記事を最後まで読んでくださり,どうもありがとうございました。