はじめに
データを使って仮説の生成と検証を行なうための方法であるベイズ最適化を学ぶために,今村秀明・松井孝太 著「ベイズ最適化 ー適応的実験計画の基礎と実践ー」を読むことにした。
本記事は,「第4章 Optunaによるベイズ最適化の実装方法」における,最適化結果の保存と最適化結果の分析に関する読書メモである。
- 本書の紹介ページ
4.6 Optunaの発展的な使い方
本節では,Optunaの発展的な使い方,すなわち高度な分析や状況に合わせた最適化,発展的な問題設定を扱う方法について説明している。
4.6.1 最適化結果の保存
本項では,Optunaの最適化結果の保存方法や再実行方法について説明してる。実装方法は,以下のoptuna_rdb.pyにて紹介されている。
github.com
Optunaの最適化の結果を永続的に保存するためには,外部の関係データベース(RDB)に保存することができる。Pythonでは,デフォルトでSQLite(https://www.sqlite.org/)が利用できるので,これを用いて結果を保存する。
study = optuna.create_study(
storage="sqlite:///test.db",
study_name="test",
load_if_exists=True,
)
プログラムの実行後には,"test.db"というファイルが生成されていることが確認できた。

4.6.2 最適化結果の分析
前項では,最適化の結果を保存したが,本項では保存した最適化の結果を呼び出し,さらに分析するための方法を紹介している。実装方法は,以下のoptuna_visualization.ipynbで紹介している。
github.com
test.dbが生成されている前提のもと,以下のコマンドを実行することで最適化結果を読み込む。
study = optuna.load_study(study_name="test", storage="sqlite:///test.db")
その後,Optunaの各種可視化機能を実行している。
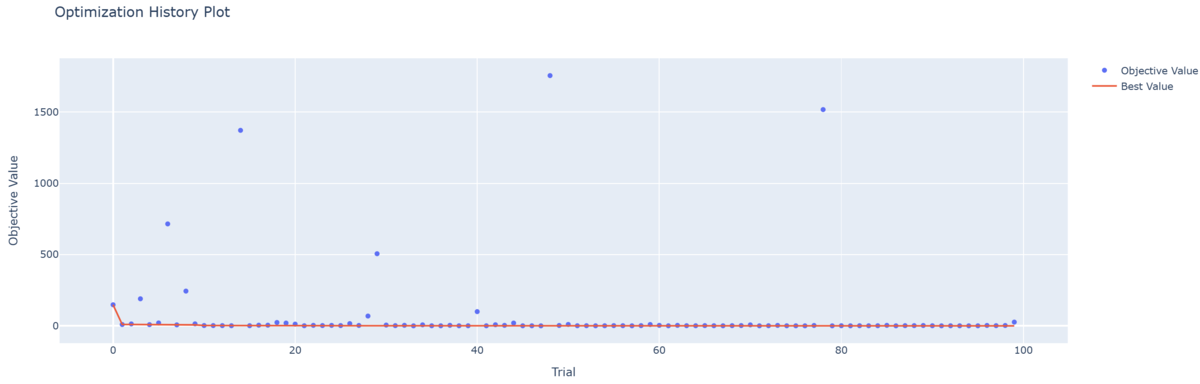
- 最適化履歴のプロット
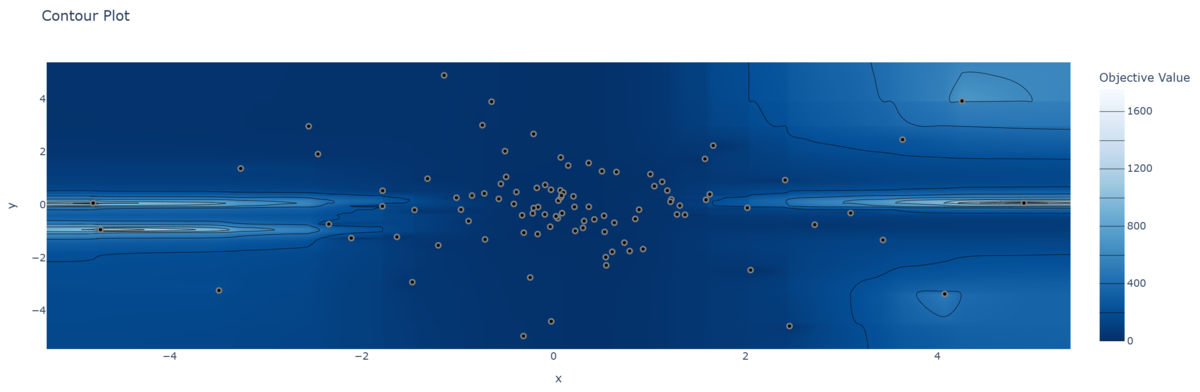
- 等高線プロット
- 横軸・縦軸にそれぞれ目的関数の探索点の各次元を取り,色の濃さは目的関数値を示す。
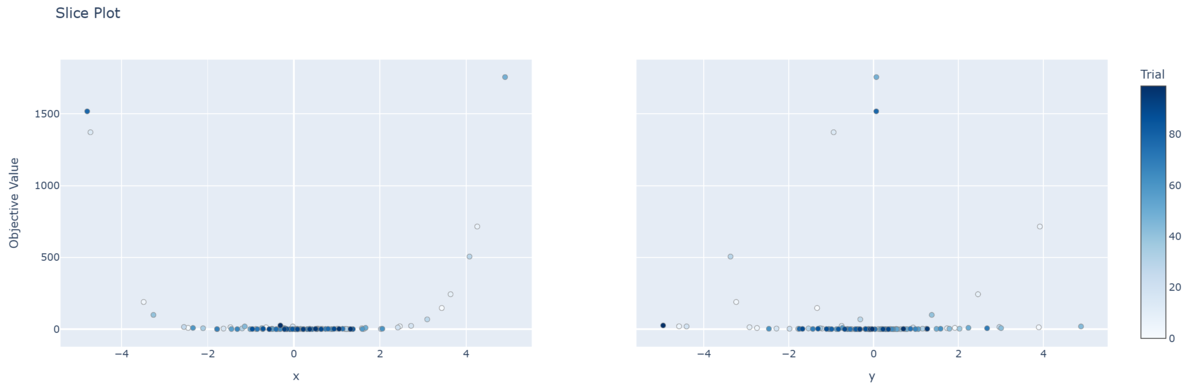
- スライスプロット
- 横軸に各次元(左図は
軸,右図は
軸),縦軸に目的関数値を取っている。
ともに,
付近に値が集中している。
- 横軸に各次元(左図は
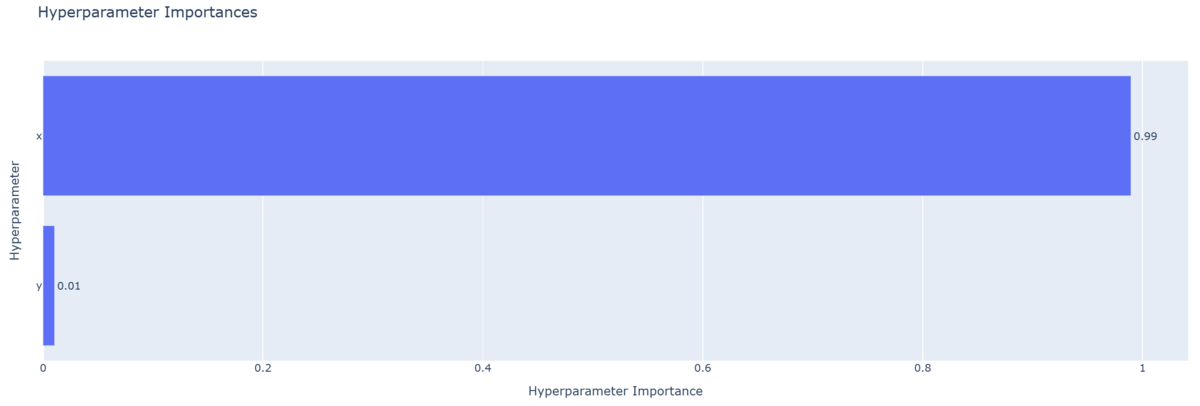
- パラメータ重要度プロット
- パラメータ重要度プロットは,各次元の重要度を示す。
- 下図では,
- スライスプロットでは
付近に値が集中しているので,
- 並行座標プロット
- 横軸には探索点の各次元および目的関数値が,縦軸にはそれぞれの値が示されている。また,色の濃さは目的関数値である。
付近に値が集中していることが分かる。
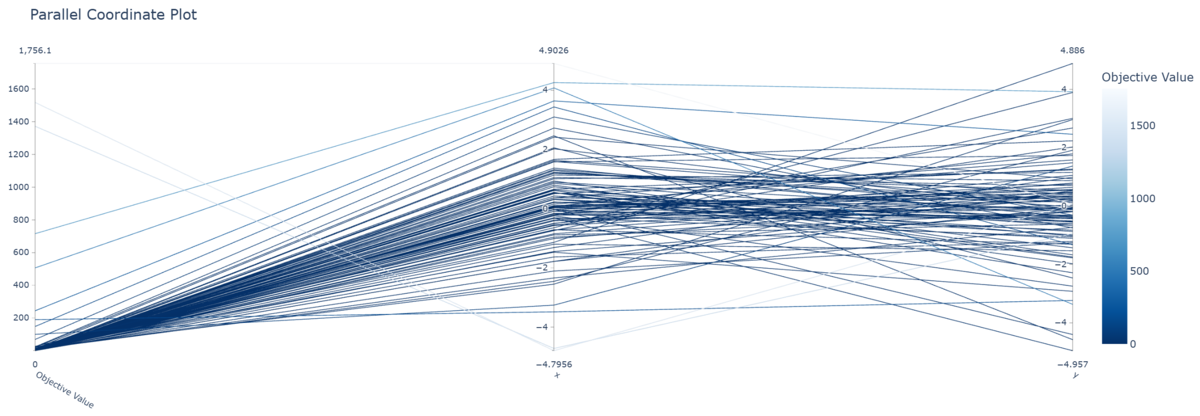
これらの考察を受けて,の範囲を
から
に狭め,また
の範囲も
に狭めて探索を行なった。
その結果,元の探索範囲よりもよりよい目的関数値が得られることが確認できた。
Best value: 4.732345660237577e-05 (params: {'x': 0.004880096919963927, 'y': -6.366534273427246e-05})
まとめと感想
今回は,「第4章 Optunaによるベイズ最適化の実装方法」のうち,Optunaの発展的な使い方について学んだ。
時間がかかる計算を行なうに当たり,計算結果を保存しておくことは重要である。Optunaのパラメータを保存する際には,SQLiteのDB名やStudy名を指定すれば,細かなスキーマを定義することなく保存できるのはとても便利だと感じた。
また今回の本題ではないが,最適化結果に関する各種可視化手法と,その活用方法についても参考になった。グリッドサーチの時でもそうだが,幅広く探索した後にパラメータの最適解がありそうな箇所に当たりを付けて再度探索することで,よりよいパラメータを探索する,というのはベイズ最適化でも有用であるということが確認できた。
実データの解析の際にも,この手法を試してみたい。
本記事を最後まで読んでくださり,どうもありがとうございました。