はじめに
データを使って仮説の生成と検証を行なうための方法であるベイズ最適化を学ぶために,今村秀明・松井孝太 著「ベイズ最適化 ー適応的実験計画の基礎と実践ー」を読むことにした。
本記事は,「第4章 Optunaによるベイズ最適化の実装方法」における,BoTorchSamplerの発展的な使い方に関する読書メモである。
- 本書の紹介ページ
4.5 BoTorchSamplerの発展的な使い方
本節では,BoTorchSamplerの発展的な使い方,すなわち獲得関数の実装方法と,獲得関数の最適化アルゴリズムの変更方法について説明している。
獲得関数の実装
本項では,BoTorchSamplerのカスタマイズの例として,トンプソン抽出獲得関数の実装方法を説明している。
トンプソン抽出獲得関数は,各トライアルにおいて,事後分布にしたがう関数を1つサンプリングし,その関数の最小値を達成する点を次の探索点として返す獲得関数であった。すなわち,
である。
トンプソン抽出獲得関数において,関数のサンプリングを実現するには以下の2つの方法があった。
- 探索空間を離散化して正規分布からのサンプリングに帰着する素朴な方法
- ガウス過程の疎スペクトル近似に基づく方法
本項では,前者の探索空間を離散化する方法を紹介している。実装方法は以下のthompson_sampling.pyにて紹介されている。
github.com
ライブラリの追加インポート
上記のサンプルコードをGoogle Colab上で動かすにあたり,追加でoptuna-integration[botorch]をインストールする必要があった。
!pip install optuna-integration[botorch]
トンプソンサンプリングの実装
トンプソンサンプリングは,ThompsonSamplingクラスで実装している。このクラスは,botorch.acquisition.analytic.AnalyticAcquisitionFunctionを継承して実装する。
トンプソンサンプリングでは空間を離散化するが,獲得関数値をその都度計算するのは計算に時間がかかる。そのため,離散化した探索空間X(ベクトル量)に対して,ベクトルのサンプリングおよび次の探索点の探索まで行っている。
(前略) ... for i in range(n_dim): grids_for_each_dim.append(torch.linspace(bounds[0, i], bounds[1, i], delta)) X = torch.cartesian_prod(*grids_for_each_dim) posterior = self.model.posterior( X=X, posterior_transform=self.posterior_transform ) Y = posterior.rsample() self.candidates = X[torch.argmax(Y)] ... (以下略)
candidates_func の実装
candidates_funcの実装は,第4.4節と同様である。
目的関数
目的関数は,
に,小さなノイズを加えた値である。この目的関数の最小値は,である。
結果の可視化
Optunaには,可視化機能として,optuna.visualization.plot_optimization_history関数を利用する。
- 計算結果
/tmp/ipykernel_3410/2797212826.py:1: ExperimentalWarning: BoTorchSampler is experimental (supported from v2.4.0). The interface can change in the future.
sampler = optuna.integration.BoTorchSampler(candidates_func=candidates_func)
[I 2025-02-09 12:38:06,408] A new study created in memory with name: no-name-bb28b64e-b41a-4401-82a6-75963b0e4d8b
[I 2025-02-09 12:38:06,417] Trial 0 finished with value: 0.12925650791719182 and parameters: {'x': 0.8295398684803761, 'y': 0.5205501725271076}. Best is trial 0 with value: 0.12925650791719182.
[I 2025-02-09 12:38:06,419] Trial 1 finished with value: 0.492531322266805 and parameters: {'x': 0.029836539801229245, 'y': 0.40377172889462987}. Best is trial 0 with value: 0.12925650791719182.
...
(中略)
...
[I 2025-02-09 12:38:34,367] Trial 49 finished with value: -0.9966348660107163 and parameters: {'x': 0.9999999999999999, 'y': 0.6896551847457886}. Best is trial 28 with value: -1.001571328343285.
Best value: -1.001571328343285 (params: {'x': 0.9655172228813171, 'y': 0.7586206793785095})
- 描画結果
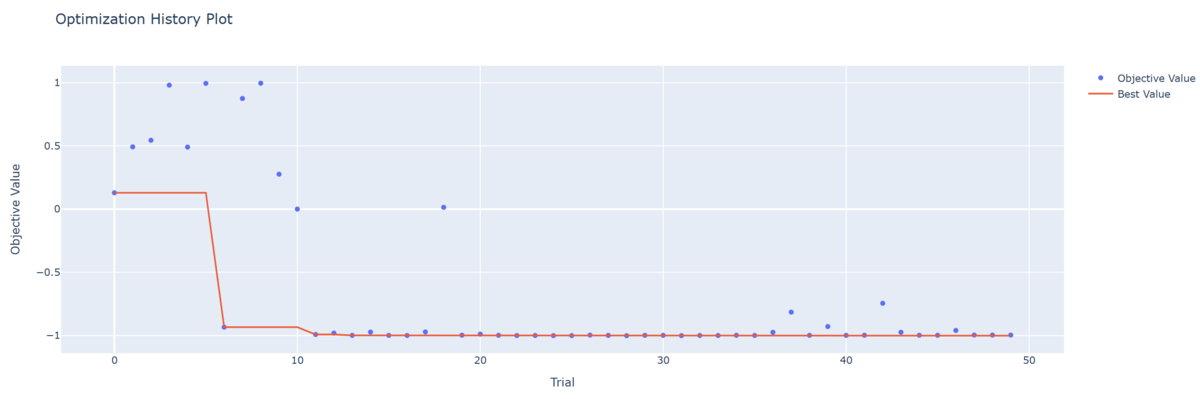
Trial 1の結果を確認すると,Trial 1における目的関数値とそれを実現する入力,およびTrial 1までの最小の目的関数値とそれを実現する入力が出力されていることが分かる。
グラフにおいては,各Trialにおける目的関数値は青い丸で,各Trialまでの最小の目的関数値は赤線で表現されている。またトライアルを続けた結果,最小の目的関数値であるに近い値が得られていることが確認できる。
獲得関数の最大化アルゴリズムの変更
本項では,獲得関数を最大化する際のアルゴリズムをカスタマイズする方法を説明している。実装方法は以下のoptimize_acqf_by_torch.pyにて紹介されている。
github.com
獲得関数の最大化には,BoTorchのbotorch.optim.optimize_acqf関数が用いられているが,内部ではL-BFGS法が用いられている。本項ではこれを,勾配ベースの手法であるAdamに置き換えている。
各種の初期設定
Adamでは,局所最適解にはまる可能性があるので,異なる初期値で計算を行なう回数であるn_startを決めている。
またAdamの計算を止めるために,収束条件を判定することで停止することもできるが,今回の例では繰り返し回数の上限値n_iterを決めている。
探索点の初期化
ベイズ最適化においては,多くの獲得関数は広い範囲で0という値をとり,またこの点における勾配においても0である場合がある。そのため初期の探索点をランダムに選ぶと,獲得関数の最大化が難しくなるおそれがある。
そのためBoTorchでは,初期化用のユーティリティが準備されている。
Xraw = torch.rand(100 * n_restarts, 1, n_dim) Yraw = acqf(Xraw) X = initialize_q_batch_nonneg(Xraw, Yraw, n_restarts) X.requires_grad_(True)
Adamのオプティマイザ
Adamのオプティマイザを定義して,最大化を行なう。
optimizer = torch.optim.Adam([X], lr=0.01) for i in range(n_iter): optimizer.zero_grad() losses = -acqf(X) loss = losses.sum() loss.backward() optimizer.step() for i in range(n_dim): X.data[..., i].clamp_(0, 1)
Pytorchのオプティマイザは最小化を仮定するため,ロスの計算においてはマイナスをつけている。
目的関数
目的関数は,
に,小さなノイズを加えた値である。この目的関数の最小値は,である。
結果の可視化
結果の可視化については,各Trialにおける目的関数値が青い丸で,各Trialまでの目的関数値の最小値が赤線で表示されている。
- 計算結果
(中略)
...
Best value: 0.018108471447790105 (params: {'x': 0.021770000457763672, 'y': -0.1404327154159546})
- 描画結果
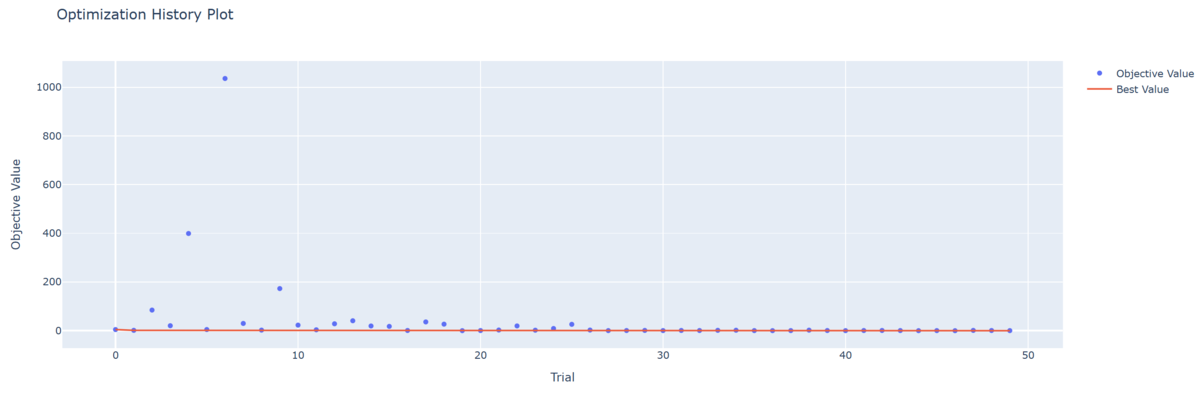
計算結果は,目的関数の最小値であるに近い値が得られていることが確認できた。
まとめと感想
今回は,「第4章 Optunaによるベイズ最適化の実装方法」のうち,BoTorchSamplerの発展的な使い方について学んだ。
カスタマイズをする場合,BoTorchのクラスを継承したり,PyTorchを用いたりすることができるので,カスタマイズはしやすいと感じた。
ただ,最適化の目的が,獲得関数は最大化である一方で,PyTorchの最適化は最小化を目指すので,最適化の取り扱いについては注意が必要である。
本記事を最後まで読んでくださり,どうもありがとうございました。