はじめに
統計検定1級の2019年 統計数理 問3において,連続一様分布(以下,単に「一様分布」と記載する)の問題が出題された。一様分布について,問題集で「一様分布の最尤推定」という問題があり,つまずいたことがあったので,考え方を整理した。
最尤推定
最尤推定は,統計モデルのパラメータ推定手法ではおなじみの方法で,機械学習でも登場する手法である。
パラメータを持つ確率密度関数
について,データ
が与えられているときに,尤度関数
具体的な解き方としては,尤度方程式
一様分布のパラメータの最尤推定
一様分布
あらためて,一様分布の定義を確認する。確率変数が閉区間
上の一様分布にしたがうとは,
の確率密度関数が
\begin{equation}
f_X(x|a, b)=
\begin{cases}
1/(b - a) & \text{if $a \leq x \leq b$,} \\
0 & \text{otherwise}
\end{cases}
\end{equation}
で定義される。
今回は,パラメータがのみの一様分布
\begin{equation}
f_X(x| \theta )=
\begin{cases}
1/ \theta & \text{if $0 \leq x \leq \theta$,} \\
0 & \text{otherwise}
\end{cases}
\end{equation}
を考えよう。
一様分布のパラメータの最尤推定 : 誤った手順
以下の流れは,私が初めてこの問題に対峙した時にしてしまったミスである。
一様分布の定義に沿って,尤度関数を考えると,
パラメータ
ここでミスに気付くのである。これでは,について解くことができない。
データの可視化
一様分布のパラメータの最尤推定に関する正しい手順を解説する前に,パラメータの推定値に当たりをつけてみよう。
データの可視化はデータサイエンスの基本なので,一様分布について,
とした場合の確率密度関数と,この確率密度関数にしたがう乱数を図示してみよう。
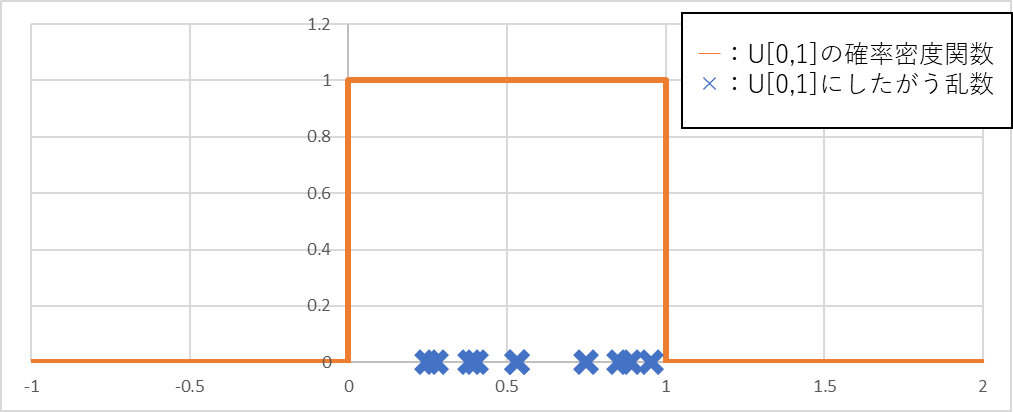
確率密度関数の形を見ると,値がから0に切り替わる点が
である。また乱数は
の範囲で発生するので,「発生した乱数のうち最大値である
が
に近い値になる」,すなわち「
の推定値は,
である」と推察することができる。
一様分布のパラメータの最尤推定 : 正しい手順
先ほど,一様分布の尤度関数を
のように取りうる値の範囲が決まっているからだ。
定義関数
\begin{equation}
I_{[A]}=
\begin{cases}
1 & \text{if $A$ is true,} \\
0 & \text{otherwise}
\end{cases}
\end{equation}
このように表現することで,サンプルの値の範囲の情報や,の値の範囲の情報が盛り込むことができる。
この尤度関数は,値が不連続に変化する定義関数を含んでいるので,微分することができない。そのため尤度方程式を用いることができない。
ただ最尤法を用いたパラメータ推定は,尤度関数を最大化するパラメータを求めることなので,
の範囲は
は単調減少関数
であることに注意すると,上記の尤度関数はで最大値を取る,すなわち最尤推定量は
であることが分かる。
