「確率的機械学習 入門編II」読書メモ一覧 - jiku log
はじめに
持橋大地・鈴木大慈 監訳「確率的機械学習 入門編II」は,世界的に評価の高いK.P.Murphy著 "Probabilistic Machine Learning (Book1)" の和訳であり,確率モデルに基づく機械学習,深層学習といった基礎が丁寧に整理されている。
本記事は,「第20章 次元削減」の単語埋め込みにおける,word2vecに関する読書メモである。
20.5 単語埋め込み
20.5.2 word2vec
word2vecモデルはよく用いられる埋め込みのモデルであり,浅いニューラルネットワークによって文脈から単語を予測するモデルである。
word2vecには,
- CBOW : 周囲の単語から,1つの単語を予測する。
- スキップグラム : 1つの単語から,周囲の単語を予測する。
の2つのバージョンがある
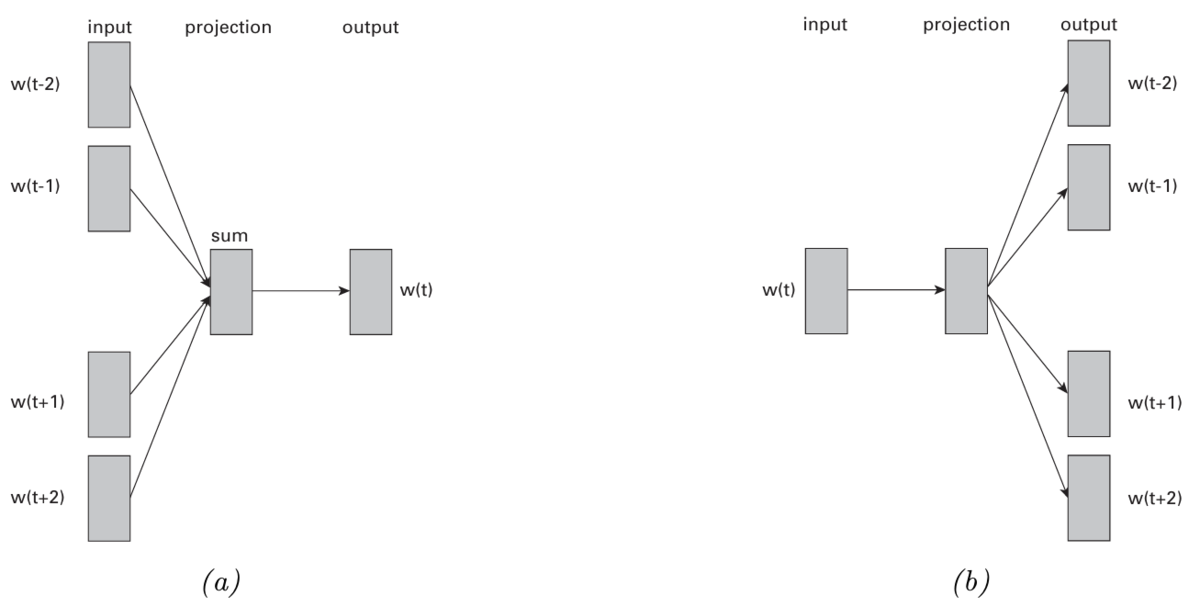
word2vecのCBOWモデル
連続化された単語集合(CBOW)モデルは,単語列の対数尤度を次のようにモデル化する。
word2vecのスキップグラムモデル
スキップグラムモデルは,各単語から文脈を予測するモデルであり,目的関数(負の対数尤度)は以下のようになる。
負例サンプリング
(20.148)式に現れる総和の計算には,すべての単語の集合が現れるが,すべての単語に対する計算はコストが高い。
そのため,個の「文脈語」を用意し,1つを正例,残りを負例とする。負例の出現確率の分布は,は単語の出現頻度の分布(ユニグラム)を3/4乗したものを用いる。
負例サンプリングを用いると,条件付き分布は以下のように近似できる。
: 雑音語(負例の単語)
: 単語ペアがデータ上で実際に共起する事象
: 単語ペアがデータ上で共起しない事象
である。
20.5.3 GloVe
スキップグラムとは別の人気があるモデルとして,GloVe(Global Vector, 大域的ベクトル表現)が挙げられる。
GloVeは,「素の」(負例サンプリングを用いない)スキップグラムよりも高速に最適化できる簡潔な目的関数を持つ。
スキップグラムモデルを改めて確認とすると,損失関数は
スキップグラムモデルは,の正規化計算が重いという問題がある。
GloVeでは,正規化を用いずに,
20.5.4 単語の類推
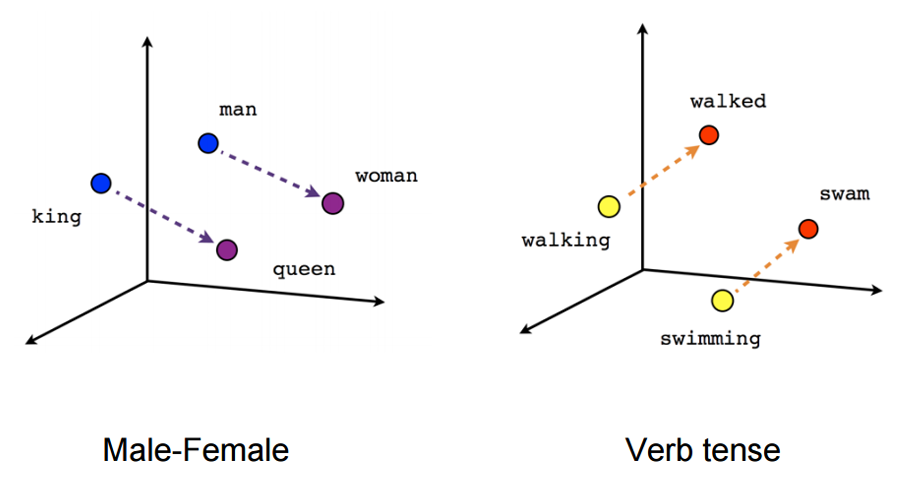
word2vecやGloVeなどの手法によって得られた埋め込みの特筆するべき性質は,ベクトルどうしの単純な足し算によって,意味の関係性が捉えられるように見えるということである。
たとえば,以下のような例が挙げられる。
- "man"→"woman"という位置関係を,"king"に当てはめると,"king"→"queen"という関係が得られる。
- "walking"→"walked"という位置関係を,"swimming"に当てはめると,"swimming"→"swam"という関係が得られる。
20.5.5 RAND-WALK モデル
単語をベクトル化する手法として,1ホット表現よりも単語埋め込みの方が上手く機能する,という説明をするのがRAND-WALKである。
潜在的な文脈ベクトルをとする。「単語は,文脈に沿って出現する」と考えると,単語
の出現頻度は,単語の埋め込み表現
と文脈ベクトルの近さ
に依存する,とモデル化できる。
文脈ベクトルは,ガウス雑音によるゆっくりとしたランダムウォークに沿って変化すると仮定すると,この分配関数は文脈に依存せず,ある定数
に近似的に等しくなることが示される。
さらに,自己相互情報量PMIは,
20.5.6 文脈化単語埋め込み
同じ単語でも,文脈によっては異なる意味を持つことがある(例:果物のappleと,企業のApple)。
静的な単語埋め込みでは,このような違いを捉えることができないが,15.7節で紹介したようなELMoやBERTでは,このような文脈を捉えることができる。
まとめと感想
今回は,「第20章 次元削減」の単語埋め込みにおける,word2vecについてまとめた。
word2vecは,最近ではよく用いられる単語埋め込み手法の基礎的なものであるが,モデルの考え方や計算の工夫(負例サンプリングやGloVeなど)が一通り説明されており,参考になった。
ニューラルネットワークモデルを用いることで非線形なモデル化も可能であるし,単語の種類数が増えても巨大な行列のSVDを行なう必要もないので,word2vecは単語埋め込みを大きく進化させたものであると言える。
また,埋め込み表現の妥当性が,RAND-WALKによって裏付けられるというのも興味深かった。
実務上は,文脈も考慮できるモデルの方が有利ではあるが,本節の内容は基礎の理解には有益であると考えられる。
本記事を最後まで読んでくださり,どうもありがとうございました。
参考サイト
- 確率的機械学習:入門編 II |朝倉書店
- 『確率的機械学習:入門編』サポートサイト
- 原著関連
- Probabilistic Machine Learning: An Introduction : 原著のサポートページ
- pyprobml/notebooks.md at auto_notebooks_md · probml/pyprobml · GitHub : 原著の図作成用Notebooks一覧