はじめに
東京大学教養学部統計学教室編「自然科学の統計学」は,1992年発行のやや古典的な文献であるが,自然科学に関わる統計学的テーマが簡潔にまとめられている。数理統計学の復習も兼ねて,本書を読むこととした。
ただ,基本的なことは他書で学んできたのと,本書自体がかなり細かく説明されているので,本書内の内容や数式を細かく追うというより,実務や統計検定の受験において有用そうなことを選んでまとめてみたい。
9.3 ベイズ推定
一般に,事後確率分布は,パラメータの確率分布を示している。しかしこれは1つの値を示したものではない。すなわち事後確率分布は,パラメータの値が出る可能性は示しているが,どの値が出るかは示していない。
パラメータの値として1つの値
を示すことは1つの決定であり,統計学的には推定の問題となる。事後確率分布の期待値(平均値)は1つの規準であるが,他にも基準は存在する。
一般に推定値と真のパラメータ
のはなるべく近い方が良く,離れるにしたがい望ましくないことになる。そこで,推定のペナルティー(損失関数)を
を導入し,これを基準に考える。
期待損失の最小化の原理
の推定基準として,まずは
の期待値を考える。
これらの総和または積分は,まだの関数である。もともと
は未知であるので,このままでは最小化ができない。
にはもともと
(連続値の場合は
)という事前確率分布を設定しているので,これを用いて期待値を取る。
この基準のことを,最小事後期待損失の基準と呼ぶ。
ベイズ推定
最小事後期待損失による基準,すなわち事後確率分布による損失の期待値(平均値)を最小にする
を求める。なお,事後確率による期待損失を
と表記する。
典型的な損失関数に応じて,は変わってくる。
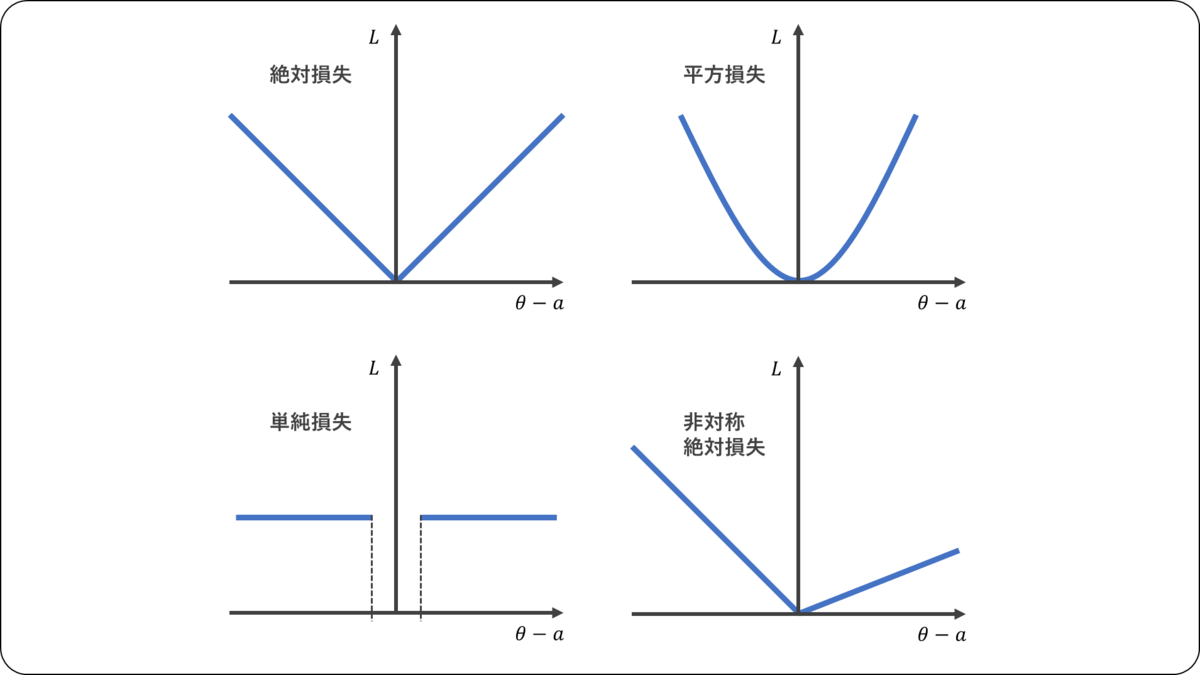
以下では,各種の損失と,その損失におけるの推定値
を導出する。ただし確率変数やパラメータは連続変数とする。
絶対損失
絶対損失は,
このときは,事後確率分布
による期待値を用いて
絶対値が含まれているので,積分を分割すると,
第1項と第2項をそれぞれで微分すると,
全確率は1,すなわちを代入すると,
最小値を取る点の条件であるを用いると,このとき
平方損失
平方損失は,
このときは,
が最小となる点では,
となるので,
単純損失
単純損失は,
このときは,定義関数
を用いて,
したがって,を最小化する
は,
9.4 統計的決定理論
前節までは,パラメータを推定する際に,「事後確率分布による損失関数の期待値」を最小にするように求めていた。
一方で,パラメータの検定を行なう際に,検定方式は「第1種の過誤が有意水準を超えないという条件のもとで第2種の過誤を最小化する」ような検定方式とみなせるので,第1種の過誤と第2種の過誤をコスト(損失)とみなして,これを最小化するようにしている,と考えられる。
このことから,推定も検定も,ある基準になるコストを最小にする統計量を求めているといえる。この統計量は,
- 推定 : 推定量
- 検定 : 検定統計量
である。
このように,統計的推測全体を1つの見地から統一的にとらえる考え方を,ワルドの統計的決定理論(Statistical Decision Theory)という。
統計的決定問題
統計的決定理論において,
- 推定 : 推定量を求める
- 検定 : 検定統計量と棄却域を用いて採択・棄却を判断する
といった行動を行なうが,この行動はデータによって行われるため,行動を
の関数として
と表す。
統計的決定理論では,最適な行動を求めることを目的とし,このような問題を統計的決定問題という。この一般的な解法は,最小事後期待損失の基準によって求めることになる。
まとめと感想
今回は「第9章 ベイズ決定」における,ベイズ決定についてまとめた。
本節を学ぶことを通じて,「ベイズ推定」と「統計的決定理論」が密接に結びついているということを理解した。特に,損失関数の選び方によって推定量が大きく変わるという事実は,実務において「最適な推定量」を考える際の指針になる。例えば,平均値推定がノイズに弱い状況では中央値推定を選ぶ方が合理的であり,モード推定が適切な場面もある。
また、推定と検定を「統計的決定」という共通の視点で整理する考え方は,統計学の理解を一段深める助けになった。普段の業務では「推定」と「検定」を別々のツールとして使い分けがちだが,実はどちらも「意思決定問題」に還元できるという見方を得ると,モデル選択や不確実性の扱いをより体系的に考えられるようになる。
統計的決定理論は,竹村「現代数理統計学」においても説明されている。ここではベイズ統計学を陽には扱っていないが,今一度復習してみたいと思う。
本記事を最後まで読んでくださり,どうもありがとうございました。