はじめに
製造業の業務で機械学習モデルを運用する際に重要になる説明性・解釈性を把握するための手法を学ぶために,森下光之助 著 「機械学習を解釈する技術〜予測力と説明力を両立する実践テクニック」を読むことにした。
本記事は,「第6章 予測の理由を考える~SHapley Additive exPlanations~」における,SHAP(SHapley Additive exPlanations)値に関する読書メモである。
- 本書の紹介ページ
機械学習を解釈する技術 〜予測力と説明力を両立する実践テクニック:書籍案内|技術評論社
- 関連コード
6.4 SHapley Additive exPlanations
前節では,協力ゲーム理論におけるShapley値のコンセプトと,その計算手順を説明していた。本節ではShapley値のコンセプトを機械学習に応用し,特徴量の貢献度を計算する手法であるSHapley Additive exPlanations(SHAP)を説明している。
SHAPとShapley値の違い
機械学習におけるSHAPと,協力ゲームにおけるShapley値の違いは,限界貢献度の計算方法である。限界貢献度は,以下に示す特徴量の貢献度
において,赤字部分である。
「協力ゲーム理論におけるShapley値」の説明においては,などの報酬が事前に与えられていた。Shapley値を機械学習に応用する場合は,これらの値の計算方法を定義する必要がある。本書ではこの計算方法を,「特徴量
が分かっている場合と分かっていない場合での予測値の差分」と表現していたが,この「分かっている」・「分かっていない」という表現がピンとこなかったので整理してみた。
「特徴量が分かっている場合・分かっていない場合」の解釈
まず記号を再確認する。本書では特徴量を
と表現している。この特徴量は,数理統計学における確率変数
のように,変数として扱われている。
一方で,学習データ・テストデータのように,値が確定したものはインスタンスと表現されている。個のインスタンスのうち,
番目のインスタンス(インスタンス
)は,
のように,表示される。特徴は,
- 特徴量は変数であり,
のように大文字で表されている。
- 一方インスタンスは確定値であり,
のように小文字で表されている。
- インスタンスの要素は
のように表されるが,インスタンスの番号の添え字は
で,特徴量の番号の添え字は
で表されている。
ということである。
学習済みモデルと,
個のインスタンスからなるデータが揃っていれば,「特徴量が分かっていない」という状況は起きえないと思っていた。しかし本節の説明を読み進めると,
という意味であると解釈できた。
具体例 : 特徴量が2つの場合
本項では具体例として,特徴量がで,インスタンス
は
という値を取っているとする。
SHAPで最終的に行ないたいことは,
インスタンス
を,ベースライン
および各特徴量の貢献度
で表す。
ということである(ICEと同様に,インスタンスごとに計算する)。
以下では,「全ての特徴量が変わっている場合」と「全ての特徴量が分かっていない場合」に分けて,Shapley値の計算における報酬の計算方法を説明する。
全ての特徴量が分かっている場合
まずインスタンスにおける全ての特徴量
が分かっているとする。この場合,Shapley値の計算における報酬
は,
とすればよい。これは通常の機械学習タスクにおける,テストデータを用いた予測値の算出と同じである。
全ての特徴量が分かっていない場合
次に,特徴量が分かっていない場合について考える。この場合は,インスタンスの全ての特徴量
は用いずに計算する(一部は用いることがある)。
- インスタンスにおける特徴量の情報が全くない場合
インスタンスにおける特徴量の情報が全くない場合は,予測値の期待値を取る。すなわち,
とする。テストデータを用いて具体的に計算する場合は,全てのインスタンスについて予測値を計算し,その平均を取ればよい。
- インスタンスにおける特徴量の情報の一部がない場合
特徴量の値が分かっている,すなわちインスタンス
における特徴量
の値が
であることが分かっているとする。逆に,特徴量
の値は分かっていない。
インスタンスにおける特徴量の情報が,一部が存在して一部がない場合は,存在していない特徴量について積分消去(または平均)すればよい。
この期待値を実測値から計算する場合,は値が固定されているので,特徴量
に関しては全てのインスタンスで値を
で上書きし,全てのインスタンスに対して予測を行ない,これらの平均を計算する。
予測値の構成方法
上記を踏まえて,の順で特徴量の値が分かった場合に予測値がどのように変化するかを確認する。
- 全ての特徴量が分かっていない →
のみが分かったときの予測値の変化
が分かったときの予測値の変化
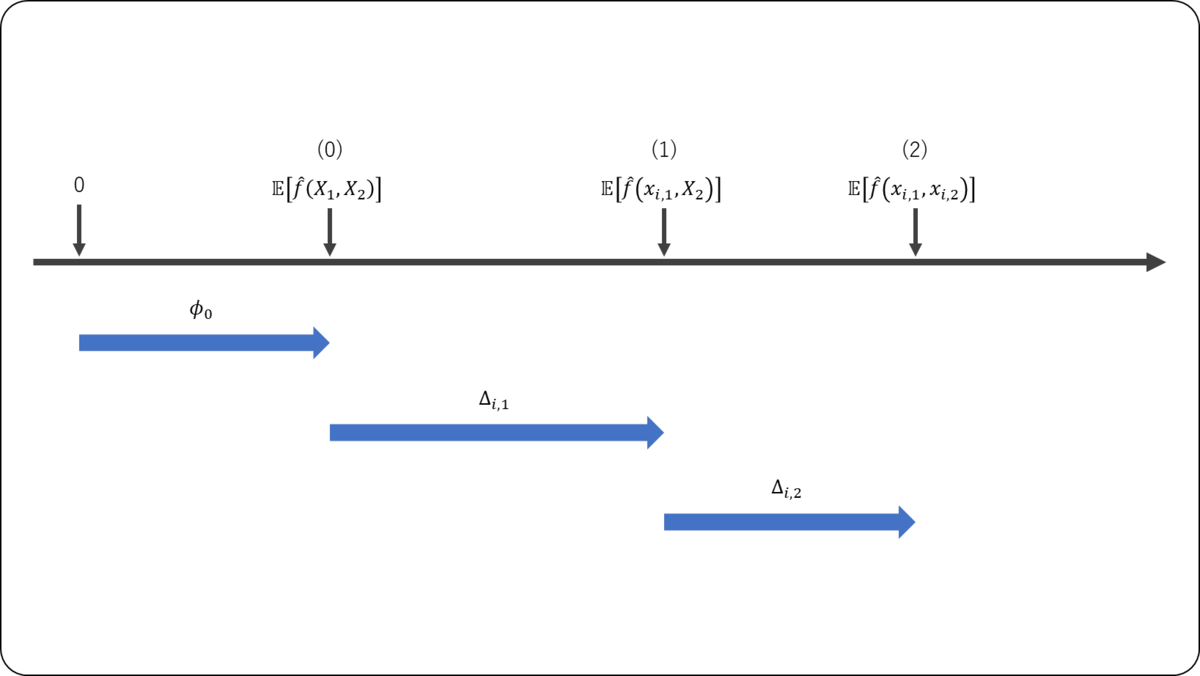
- 特徴量の値が分かる順番の考慮
協力ゲーム理論におけるShapley値の計算では,順番を考慮することが重要であった。SHAPの計算においても同様に,の順で特徴量の値が分かった場合では,各特徴量が予測値に与える影響が変化する。
考え得る全ての順序とその場合の予測値が与える影響は下表の通りである。
| 特徴量の値が分かった順番 | |
|
|---|---|---|
| |
|
|
| |
|
Shapley値の計算と同様に,SHAP値はそれぞれの特徴量が分かったことによる差分を平均すればよいので,以下のようになる。
更に上式からSHAP値の合計は,
となり,インスタンスの予測値は,ベースラインと各特徴量の貢献度の足し算に分解できることが分かる。
まとめと感想
今回は,「第6章 予測の理由を考える~SHapley Additive exPlanations~」における,SHAP(SHapley Additive exPlanations)値にについてまとめた。
協力ゲーム理論におけるShapley値では,ゲームの参加者のパターンに応じた報酬が設計されていたが,機械学習の利用シーンでは特定の特徴量が除外された状態で予測値が得られることはない。そのため,周辺化を行なうことでこのような値を算出する,というアイディアは興味深かった。
考え方自体はシンプルではあるが,SHAP値の計算では「特徴量の順列の回数分」の計算が発生するので,計算量は結構多いと考えられる。次節以降では,サンプルコードを動かしてみて挙動を確認してみたい。
本記事を最後まで読んでくださり,どうもありがとうございました。