はじめに
製造業の業務で機械学習モデルを運用する際に重要になる説明性・解釈性を把握するための手法を学ぶために,森下光之助 著 「機械学習を解釈する技術〜予測力と説明力を両立する実践テクニック」を読むことにした。
本記事は,「第3章 特徴量の重要度を知る~Permutation Feature Importance~」における,サンプルコードを動作確認したときの読書メモである。
- 本書の紹介ページ
機械学習を解釈する技術 〜予測力と説明力を両立する実践テクニック:書籍案内|技術評論社
- 関連コード
GitHub - ghmagazine/ml_interpret_book
目次
第3章 特徴量の重要度を知る~Permutation Feature Importance~
本記事では,第3章のサンプルコードを動作確認しながら,その挙動を確認した。
github.com
動作確認は,Google Colab上で行なった。
なお本書は2021年に発行された本である。そのため,scikit-learnのバージョンが変わっており,そのままではエラーが発生してしまった。
そのため,2025年3月現在のscikit-leanのバージョン1.6.1でも動作するように修正してみた*1。
3.2 線形回帰モデルにおける特徴量重要度
初期設定における修正
2025年3月現在,Google Colabではjapanize_matplotlibがインストールされていないようなので,pip installする必要がある。
!pip install japanize_matplotlib
また,別のディレクトリにあるコードを呼び出しているので,ドライブを設定する必要があった。
from google.colab import drive drive.mount('/content/drive') <|| そのうえで,ディレクトリの場所を指定する必要があった。 >|python| (中略) # 自作モジュール ROOT_PATH = "/content/drive/My Drive/Colab Notebooks/ml_interpret_book" sys.path.append(ROOT_PATH) #sys.path.append("..") (以下略)
散布図作成のコード修正
散布図を作成するために,plot_scatterを自作している。散布図作成のコア部分はseabornを用いている。このscatterplot関数の引数の扱い方が変わっているようで,以下のようにな修正が必要だった。
def plot_scatter(X, y, var_names): """目的変数と特徴量の散布図を作成""" (中略) for d, ax in enumerate(axes): #sns.scatterplot(X[:, d], y, alpha=0.3, ax=ax) #<-- 修正前 sns.scatterplot(x=X[:, d], y=y, alpha=0.3, ax=ax) #<-- 修正後 ax.set( xlabel=var_names[d], ylabel="Y", xlim=(X.min() * 1.1, X.max() * 1.1) ) (以下略)
3.3 Permutation Feature Importance
PermutationFeatureImoprtance クラスにおける予測誤差計算の修正
本節では,Permutation Feature Importance (PFI)の説明に沿って,自作のPermutationFeatureImportanceクラスを作成している。
特徴量重要度を計算するには,予測誤差を計算する必要がある。予測誤差の計算には,scikit-learnのmean_squared_error関数を用いている。
上記の自作のクラスでは,
(中略)
def __post_init__(self) -> None:
# シャッフルなしの場合の予測精度
# mean_squared_error()はsquared=TrueならMSE、squared=FalseならRMSE
(以下略)
のように,引数squaredに応じて,MSEとRMSEをスイッチできるようにしている。
ただscikit-learnのmean_squared_error関数は,2025年3月現在でsquared引数を廃止している。また新たに,root_mean_squared_error関数が作成されている。
本書中では,評価指標としてRMSEのみしか使っていなかったので,root_mean_squared_error関数を使って書き直してみた。
#from sklearn.metrics import mean_squared_error # scikit-learn 1.6.1では,mean_squared_error関数の引数からsquaredが除外されている # https://scikit-learn.org/stable/modules/generated/sklearn.metrics.mean_squared_error.html from sklearn.metrics import root_mean_squared_error @dataclass class PermutationFeatureImportance: (中略) def __post_init__(self) -> None: # シャッフルなしの場合の予測精度 # mean_squared_error()はsquared=TrueならMSE、squared=FalseならRMSE # <-- 修正前 #self.baseline = mean_squared_error( # self.y, self.estimator.predict(self.X), squared=False #) # <-- 修正後 self.baseline = root_mean_squared_error( self.y, self.estimator.predict(self.X) ) (中略) def _permutation_metrics(self, idx_to_permute: int) -> float: """ある特徴量の値をシャッフルしたときの予測精度を求める Args: idx_to_permute: シャッフルする特徴量のインデックス """ (中略) #return mean_squared_error(self.y, y_pred, squared=False) # <-- 修正前 return root_mean_squared_error(self.y, y_pred) # <--修正後 (以下略)
PermutationFeatureImoprtance クラスにおけるPFI計算の修正
PFIの計算自体は,permutation_feature_importance関数の中で行なっている。この関数において,予測精度の変化具合を差(difference)と比率(ratio)の2種類を計算している。
この部分において,計算結果の型の問題で,list型とfloat型の引き算が発生していたので,list型をnumpy.array型に変換した。
(中略)
def permutation_feature_importance(self, n_shuffle: int = 10) -> None:
"""PFIを求める
Args:
n_shuffle: シャッフルの回数。多いほど値が安定する。デフォルトは10回
"""
(中略)
# データフレームとしてまとめる
# シャッフルでどのくらい予測精度が落ちるかは、
# 差(difference)と比率(ratio)の2種類を用意する
df_feature_importance = pd.DataFrame(
data={
"var_name": self.var_names,
"baseline": self.baseline,
"permutation": metrics_permuted,
#"difference": metrics_permuted - self.baseline, # <-- 修正前
#"ratio": metrics_permuted / self.baseline, # <-- 修正前
"difference": np.array(metrics_permuted) - self.baseline, # <-- 修正後
"ratio": np.array(metrics_permuted) / self.baseline, # <-- 修正後
}
)
(以下略)
上記のような修正を行なうことにより,無事に本書と同様の出力を得ることができた。
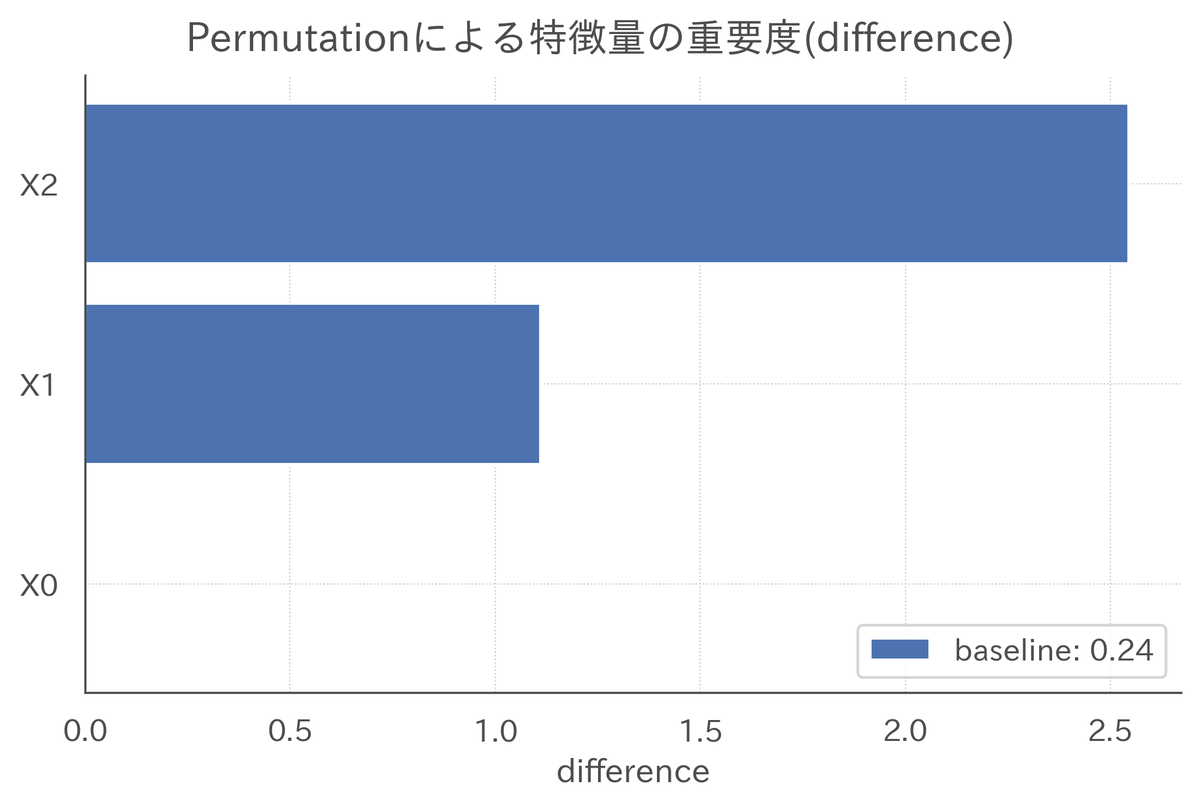
3.5 Grouped Permutation Feature Importance
Grouped Permutation Feature Importance (GPFI)は,PermutationFeatureImportanceクラスを継承したGroupedPermutationFeatureImportanceクラスとして実装している。この関数内でも同様に,予測誤差の計算と,PFIの計算の修正を行なう必要がある。
まとめと感想
今回は,「第3章 特徴量の重要度を知る~Permutation Feature Importance~」における,サンプルコードを動作確認の結果についてまとめた。
サンプルコードが作成された2021年からscikit-learnのバージョンが変わったことに起因して,そのままでは動かせない箇所が出てきたが,コードやエラーを確認することでコードを動作させることができた。なお本書で紹介されているPFIのアルゴリズムはかなりわかりやすく書かれていたため,将来的に別の言語で再実装する必要がある場合でも,ある程度流用できると感じた。
今回のコード修正では,Geminiを併用した。コードの修正案まで出してくれるが,これを鵜呑みにして動作させたときは正しく動作しなかった。生成AIによってコード開発は楽になったものの,エラーメッセージを読み解き,ライブラリや数式の知識を使って問題解決を図るということは,しばらくの間は必要であると感じた。
本記事を最後まで読んでくださり,どうもありがとうございました。
*1:時代が進めばscikit-learnのバージョンも新しくなり,本記事で紹介した修正も陳腐化するが,いつの時代でも動くコードを作成することを目指したわけではなく,自身の理解のために修正している点をご了承いただきたい。