はじめに
データのつながりに着目した新たなデータ分析の手法を学ぶために,黒木裕鷹・保坂大樹 著 「データのつながりを活かす技術〜ネットワーク/グラフデータの機械学習から得られる新視点」を読むことにした。
本記事は,「第7章 さまざまな分野における実例」における,自然言語処理におけるネットワーク分析に関する読書メモである。
- 本書の紹介ページ
第7章 さまざまな分野における実例
本章では,ネットワーク分析の技術が実社会の多様な分野で活用されていることを概観している。
などさまざまな事例が紹介されている。
7.1 自然言語処理におけるネットワーク分析
本節では,自然言語処理とネットワーク分析を組合わせるにあたり,ノードになり得る要素,エッジとなり得る要素を事例とともに紹介している。
ノードとして考慮されやすいもの
自然言語処理において,ノードとして考慮されやすいものには以下のようなものが挙げられる。
- トークン
- エンティティ
- エンティティは,特定の意味やカテゴリをもつ単語やフレーズのことである。たとえば,「2021年3月3日」は日付を表すエンティティである。
- エンティティを抽出するには,固有表現抽出(Named Entity Recognition; NER)などが挙げられる。
- エンティティによる表現は,WikipediaやDBpediaといった外部の知識ベースと接続することで,元のテキストに含まれる情報をより豊かにすることができる。
- 文書
- 文書は,自然言語処理で対象となるテキストのひとまとまりを指す。
エッジとして考慮されやすいもの
自然言語処理において,エッジとして考慮されやすいものには以下のようなものが挙げられる。
- 共起の関係
- 共起は,同じ文章に複数の単語が同時に出現することである。
- 同じ文書内で共起する単語間にエッジを張ったり,文書間で同じ単語が共起する場合に文書間にエッジを張ったりすることが考えられる。
- 文書への関与
- 複数の人物が文書作成にかかわる場合,共著者間にエッジが張られる。
- 類似性
- 明確な共起関係だけでなく,文書や単語が共有する意味的・位置的な類似性(類義語,上位下位関係など)をエッジとして扱う方法も広く利用されている。
レイアウトを考慮した帳票からの情報抽出
背景と課題
請求書などの帳票には,テキストの情報だけでなく,テキストのレイアウトが重要な情報になる。たとえば,「請求日」という文字列と「2020年4月14日」という文字列が近くにあれば,「請求日が2020年4月14日である」と解釈できる。このような,テキスト以外の情報を用いて,帳票に書かれている内容を自動的に判別できるようになることが課題である。
アプローチ方法
このようなテキスト以外の視覚情報を活用するための手法の1つとして注目されているのが,GNNを利用したアプローチである。
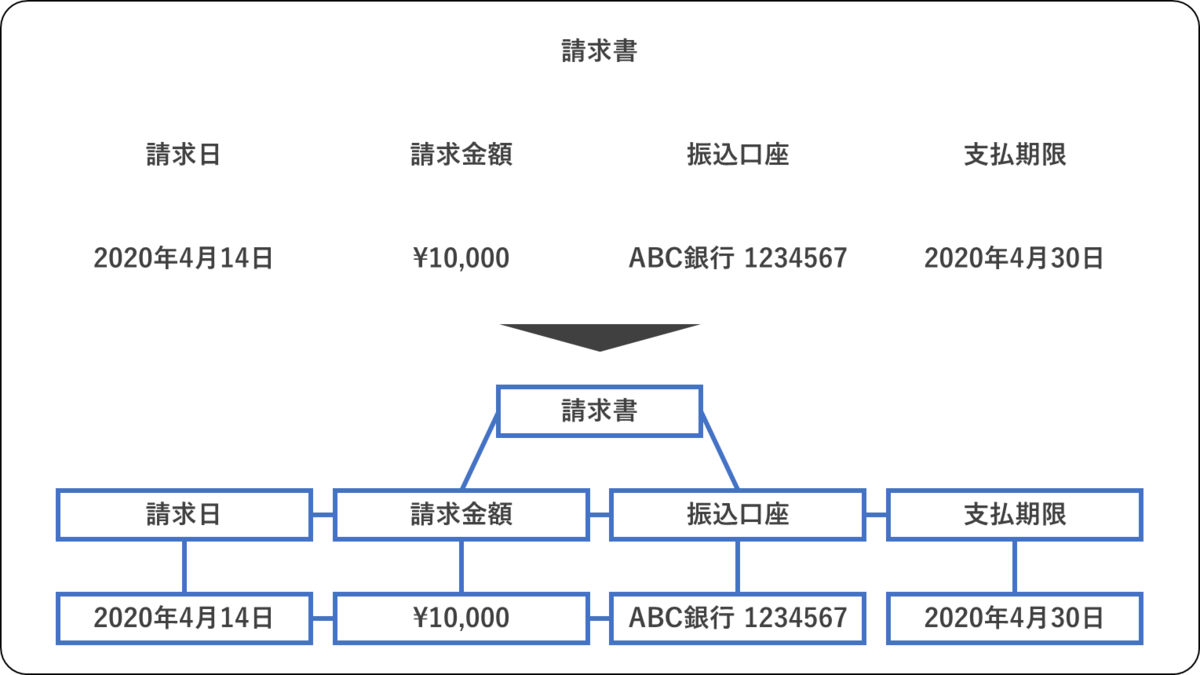
テキストに加えてレイアウト情報を利用した情報抽出の手順は以下の通りである。
- OCRやPDF解析にもとづき,レイアウト情報を取り出す。
- 文字情報をもと特徴ベクトルを獲得する。
- GNNに入力する。GNNはテキストの配置や関係性を学習し,テキストのみからの情報抽出だけでは難しかった,レイアウトに依存した情報を捉える。
大規模言語モデルの活用とRAGの改善
背景と課題
RAG(Retrieval-Augmented Generation)は,LLMによるテキスト生成を,外部の知識ベースや文書コーパスへの検索処理と組み合わせる方法である。
RAGにより,LLMに含まれない新情報や,特定ドメインに特化した専門知識を柔軟に利用できる。
しかし多くのRAGの実装では,テキストチャンク(文書を一定の長さで区切ったもの)単位で検索するため,
- クエリに関連する情報が複数のチャンクに分散している場合
- 複数の文書間の微妙な関連性や矛盾関係を含む場合
の検索が難しい。
アプローチ方法 : GraphRAG
GraphRAGは,従来のRAGが主にベクトルデータベースを用いるのに対して,知識グラフを活用して情報を表現・検索する。知識グラフは,エンティティ(ノード)とリレーション(エッジ)によってデータの複雑な相互依存関係を直接かつ柔軟に表現できる。
GraphRAGは,以下のプロセスから構成される。
- 知識グラフの構築
- ソースとなる文書集合から知識グラフを構築する。
- コミュニティ検出と要約
- 部分的な回答の生成と統合
- 質問が与えられた際に,各コミュニティ要約を並列的に参照し,部分的回答を得る。
- 最後にこれらを統合し,グローバルな回答を要約として提示する。
GraphRAGは,このような分割統治的なアプローチにより,大規模なデータセットに対しても包括的なトピックの理解や,複数の情報源を統合した回答生成を可能にする。
アプローチ方法 : LightRAG
LightRAGは,GraphRAGと同様に知識グラフを活用する手法であるが,特に継続的に変化・増大する文書集合に対して,リアルタイム性と効率性を両立することに焦点を当てている。
LightRAGは,以下のプロセスから構成される。
- 知識グラフの構築
- 文書集合を小規模なテキストチャンクへ分割し,LLMによってエンティティとそれらの関係を抽出する。
- デュアルレベル検索
- ユーザが入力するクエリから,より具体的な概念を表す低レベルキーワードと,複数エンティティを統合し抽象的な概念を表す高レベルキーワードを生成する。
- 両方のキーワードをもとに知識グラフからテキストチャンクを抽出することにより,包括的な知識を統合した回答の生成を行なう。
- 動的な更新
- 新たな文書が追加された際には,全インデックスをゼロから再構築する必要はなく,追加されたテキストチャンクとともに必要なエンティティやリレーションを付け加える。
GraphRAGは,巨大なコーパスを包括的に要約するため,階層的なコミュニティ検出とその要約生成を事前に行なう。そのため,新規文書の追加・更新が生じるたびに再度コミュニティ検出や要約生成を行なう必要がある。
一方でLightRAGでは,追加されたテキストチャンクとともに必要なエンティティやリレーションを付け加えるため,常に更新が求められる状況でも迅速で的確な回答を提供することが期待される。
まとめと感想
今回は,「第7章 さまざまな分野における実例」における,自然言語処理におけるネットワーク分析についてまとめた。
テキストデータは代表的な非構造化データの1つであるが,ノードとして考慮されやすいものや,エッジとして考慮されやすいものに着目することで,ネットワーク構造が見いだせることが理解できた。これは共起分析や構文解析,固有表現抽出といった,これまでの自然言語処理技術の応用だと考えられるが,GNNによってより豊かな情報抽出ができるようになったのだと考えられる。
また,RAGは企業におけるLLMの重要な活用事例の1つであるが,チャンク分けによって生じる問題点をGraphRAGやLightRAGによって解決しうるということは興味深かった。知識グラフの構築は大変そうではあるが,知識の種類や利用目的に応じた知識グラフが構築できるよう,知識グラフについても調べてみたいと感じた。
本記事を最後まで読んでくださり,どうもありがとうございました。