はじめに
データを使って仮説の生成と検証を行なうための方法であるベイズ最適化を学ぶために,今村秀明・松井孝太 著「ベイズ最適化 ー適応的実験計画の基礎と実践ー」を読むことにした。
本記事は,「第7章 高次元空間でのベイズ最適化」における,目的関数の加法的分解に基づく方法に関する読書メモである。
- 本書の紹介ページ
第7章 高次元空間でのベイズ最適化
入力が高次元空間の場合,
- ガウス過程モデルの推定が不安定になる
- 獲得関数が入力空間上で平坦になり最適化が難しくなる
といった理由から,通常のベイズ最適化が困難になる。
本章ではこのような問題を回避し,高次元空間上で適切にベイズ最適化を実行するための方法が説明されている。
7.1 高次元空間上でのベイズ最適化問題の課題
ベイズ最適化は,探索空間が比較的低次元(たかだか10次元程度)の場合に良い性能が示され,高次元ではベイズ最適化が困難であることが知られている。
主な理由は
- ブラックボックス関数の推定が高次元空間では難しくなる
- 獲得関数の最大化が高次元空間では難しくなる
の2点である。
1つ目の理由は,入力次元が大きくなるにつれて,ガウス過程回帰モデルの推定誤差が著しく悪化するためである(「次元の呪い」と呼ばれる現象の1つである)。
2つ目の理由については,入力次元が大きいときに,ガウス過程回帰で得られた予測分布から計算された期待改善量(EI)獲得関数が,候補点においてほぼ一様になるためである。
本書では,入力次元がのStyblinski-Tang関数を題材に,上記の現象が示されていた。獲得関数の変化が小さいと,獲得関数を最適化する過程で生じる誤差よって埋もれてしまうのである。
本章では,高次元空間におけるベイズ最適化の手法として,
- 目的関数の加法的分解に基づく方法
- 入力空間の次元削減に基づく方法
- 局所的なモデリングに基づく方法
の3つが紹介されている。
7.2 目的関数の加法的分解に基づく方法
本節では,高次元ベクトルを入力に持つブラックボックス関数を,交わりのない低次元な部分ベクトルを入力に持つ複数の関数に分解し,それぞれに対してガウス過程モデルを当てはめた結果を統合する方法を紹介している。
加法的ガウス過程モデルとその推論
モデルの定義
以下では,入力は各成分ごとに最大値が1,最小値が0に規格化されているとする(
)。
さらに,通常のベイズ最適化の問題設定に加えて,次のような仮定を置く。
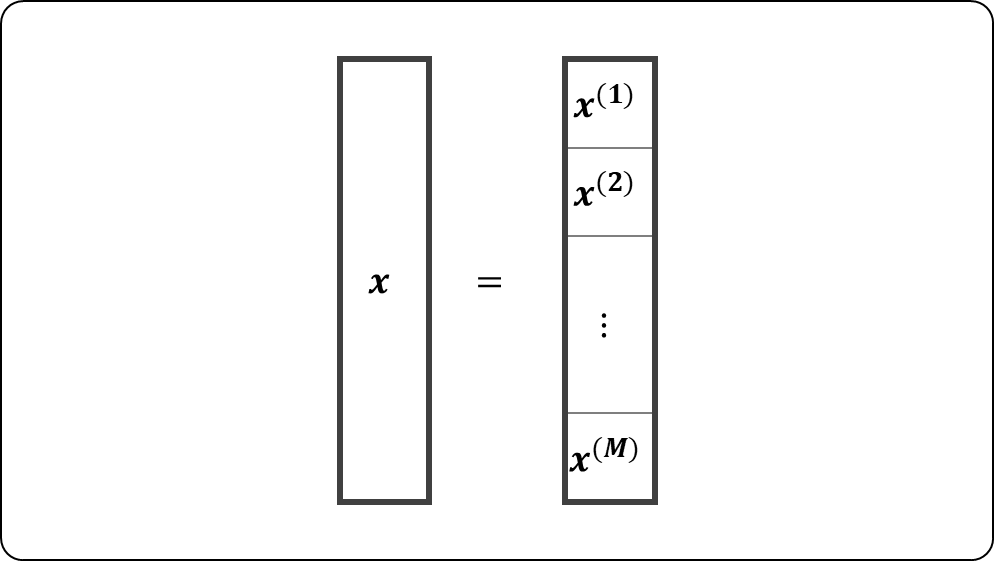
ただし,次元ベクトル
は
かつ互いに交わりが無い
の部分ベクトルで,それらは
の分割をなすとする。
また,とする。
各に対して平均関数
,カーネル関数
のガウス過程事前分布を仮定する。
ただし,であり,
さらに観測モデルについて
とすると,のガウス過程モデルは
のガウス過程モデルを用いて,
とする。このような加法的分解に基づいたガウス過程モデルを加法的ガウス過程モデル (additive Gaussian process model)と呼ぶ。
推論
の加法的分解の定義から,加法的ガウス過程モデルのもとでは,各コンポーネント
ごとに推論を行ない,その結果を結合することで
の推論を行なうことができる。
観測していない(すなわち評価をしたい点)について,その観測値
に対する推論を考える。
多変量正規分布の同時分布・条件付き分布の性質を用いると,データを観測した時における
の予測分布は,
をそれぞれ予測平均と予測分散にもつ正規分布になる。
加法的ガウス過程モデルに基づくベイズ最適化
本項では,加法的ガウス過程モデルに基づくベイズ最適化の方法として,信頼下限獲得関数を用いる方法が説明されている。
信頼下限獲得関数は,ガウス過程の予測平均と予測分散
およびハイパーパラメータ
を用いて
で定まる獲得関数であった。
これを加法的ガウス過程モデルに拡張した加法的信頼下限 (additive lower confidence bound) は,以下で定義される。
- 加法的信頼下限
加法的信頼下限は,加法的分解の各分割[te: f^{(j)}]に対する信頼下限の総和になっている。そのため,高次元における獲得関数の計算を回避することができる。
まとめと感想
今回は,「第7章 高次元空間でのベイズ最適化」のうち,目的関数の加法的分解に基づく方法について学んだ。
ベイズ最適化においても次元の呪いが発生するが,これに対する3つの対応策が紹介されていた。目的関数の加法的分解に基づく方法は,入力変数や目的関数がいくつかのブロックに分けられることを仮定したもとでの手法であり,高次元の計算を避けることができていた。
実際の応用シーンでも,たとえばプラントのデータに対してベイズ最適化を用いる場合でも,プラントの部品ごとに分解して考えれば加法的分解に基づく方法を適用できうるので,実用的であると感じた。ただし,入力ベクトルの分割は事前知識に基づいて行なう必要があるため,対象に関する知識が重要であると感じた。
本記事を最後まで読んでくださり,どうもありがとうございました。